开发
- 设备地址
- 文件类型
- exFAT 文件系统指南
- 编译器的工作过程
- 主引导记录的内存地址是0x7C00?
- 数据库的最简单实现
- 如何验证 Email 地址
- Linux 的启动流程
- Nativefier 详细设置
- DNS 原理入门
- HTML/框架
- 练习
设备地址
数字设备(公共)
A 段 0-30
|
序 |
编码 / IP | 名称 / 域名 | 端口 外:内 | 应用程序 | 描述 | 网口 | 电源 | 苹果 |
位置 |
|
0 |
192.168.1.1 | 光猫 | 电口 | 2相 / 5V | 1.2.1.100 | ||||
|
1 |
192.168.2.1 | cz.321jr.com | 10000:80 | Openwrt | 路由 | 电口 | 3相 / 12V | 2.L. | |
|
2
|
192.168.2.2 |
cz.321jr.com | 20000:8000 | 华硕 NAS | 2号 |
电口 | 3相 / 12V | 24:4B:FE:84:30:88 | |
|
3 |
192.168.2.3 |
cz.321jr.com | 30000:80 | Ubuntu | 3号 |
电口 光口 |
3相 / 12V | 34:97:F6:5C:70:63 | |
| 30001 | 英国电信 | ||||||||
| 30002 | GitLab | ||||||||
|
4 |
192.168.2.4 | cz.321jr.com | 40000 | 4号 |
电口 光口 |
3相 / 12V | 34:97:F6:5A:AE:D4 | ||
| 40001 | |||||||||
| 40002 | |||||||||
|
5 |
192.168.2.5 | cz.321jr.com | 50000 | 5号 |
电口 光口 |
3相 / 12V | 30:5A:3A:78:21:7E | ||
| 50001 | |||||||||
| 50002 | |||||||||
| 6 | 192.168.2.6 | cz.321jr.com | 60000 | 6号 |
电口 光口 |
3相 / 12V | 4C:ED:FB:3C:D5:57 | ||
| 60001 | |||||||||
| 60002 | |||||||||
|
7 |
|||||||||
|
8 |
|||||||||
| 9 | |||||||||
| 10 | |||||||||
| 11 | 打印机 | ||||||||
| 12 | |||||||||
| 13 | |||||||||
| 14 | |||||||||
|
15 |
|||||||||
|
16 |
|||||||||
|
17 |
|||||||||
|
18 |
|||||||||
|
19 |
|||||||||
|
20 |
|||||||||
|
21 |
|||||||||
|
22 |
|||||||||
|
23 |
|||||||||
|
24 |
|||||||||
|
25 |
|||||||||
|
26 |
|||||||||
|
27 |
|||||||||
|
28 |
|||||||||
|
29 |
|||||||||
|
30 |
|||||||||
|
A 段完 |
|||||||||
B 段 31-60
|
序 |
编码 / IP | 名称 / 域名 | 端口 | 应用程序 | 描述 | 网口 | 电源 | 位置 |
| 31 | 192.168.2.31 | 321JR-1 | Openwrt | 1号 wifi | 电口 | 2相 / 5V | 1.2.5.200 | |
| 32 | 192.168.2.32 | 321JR-2 | Openwrt | 2号 wifi | 电口 | 2相 / 5V | ||
| 33 | 192.168.2.33 | 321JR-3 | Openwrt | 3号 wifi | 电口 | 2相 / 5V | ||
| 34 | 192.168.2.34 | 321JR-4 | Openwrt | 4号 wifi | 电口 | 2相 / 5V | ||
| 35 | 192.168.2.35 | 321JR-5 | Openwrt | 5号 wifi | 电口 | 2相 / 5V | ||
| 36 | 192.168.2.36 | 321JR-6 | Openwrt | 6号 wifi | 电口 | 2相 / 5V | ||
|
37 |
||||||||
|
38 |
||||||||
|
39 |
||||||||
|
40 |
||||||||
|
41 |
||||||||
|
42 |
||||||||
|
43 |
||||||||
|
44 |
||||||||
|
45 |
||||||||
|
46 |
||||||||
|
47 |
||||||||
|
48 |
||||||||
|
49 |
||||||||
|
50 |
||||||||
|
51 |
||||||||
|
52 |
||||||||
|
53 |
||||||||
|
54 |
||||||||
|
55 |
||||||||
|
56 |
||||||||
|
57 |
||||||||
|
58 |
||||||||
|
59 |
||||||||
|
60 |
||||||||
|
B 段完 |
||||||||
文件类型
常见文件类型
常见的文件扩展名,按文件格式组织
文本文件
| Extension | 文件类型 |
|---|---|
| .DOC | Microsoft Word Document (Legacy) |
| .DOCX | Microsoft Word Document |
| .LOG | Log File |
| .MSG | Outlook Message Item File |
| .ODT | OpenDocument Text Document |
| .PAGES | Apple Pages Document |
| .RTF | Rich Text Format File |
| .TEX | LaTeX Source Document |
| .TXT | Plain Text File |
| .WPD | WordPerfect Document |
| .WPS | Microsoft Works Word Processor Document |
数据文件
| Extension | 文件类型 |
|---|---|
| .CSV | Comma-Separated Values File |
| .DAT | Data File |
| .GED | GEDCOM Genealogy Data File |
| .KEY | Apple Keynote Presentation |
| .KEYCHAIN | Mac OS X Keychain File |
| .PPT | Microsoft PowerPoint Presentation (Legacy) |
| .PPTX | Microsoft PowerPoint Presentation |
| .SDF | Standard Data File |
| .TAR | Consolidated Unix File Archive |
| .TAX2016 | TurboTax 2016 Tax Return |
| .TAX2020 | TurboTax 2020 Tax Return |
| .TAX2021 | TurboTax 2021 Tax Return |
| .VCF | vCard File |
| .XML | XML File |
音频文件
| Extension | 文件类型 |
|---|---|
| .AIF | Audio Interchange File Format |
| .IFF | Interchange File Format |
| .M3U | Media Playlist |
| .M4A | MPEG-4 Audio File |
| .MID | MIDI File |
| .MP3 | MP3 Audio File |
| .MPA | MPEG-2 Audio File |
| .WAV | WAVE Audio File |
| .WMA | Windows Media Audio File |
视频文件
| Extension | 文件类型 |
|---|---|
| .3G2 | 3GPP2 Multimedia File |
| .3GP | 3GPP Multimedia File |
| .ASF | Advanced Systems Format File |
| .AVI | Audio Video Interleave File |
| .FLV | Flash Video File |
| .M4V | iTunes Video File |
| .MOV | Apple QuickTime Movie |
| .MP4 | MPEG-4 Video File |
| .MPG | MPEG Video File |
| .RM | RealMedia File |
| .SRT | SubRip Subtitle File |
| .SWF | Shockwave Flash Movie |
| .VOB | DVD Video Object File |
| .WMV | Windows Media Video |
3D 图像文件
| Extension | 文件类型 |
|---|---|
| .3DM | Rhino 3D Model |
| .3DS | 3D Studio Scene |
| .MAX | 3ds Max Scene File |
| .OBJ | Wavefront 3D Object File |
光栅图像文件
| Extension | 文件类型 |
|---|---|
| .BMP | Bitmap Image |
| .DDS | DirectDraw Surface Image |
| .GIF | Graphical Interchange Format File |
| .HEIC | High Efficiency Image Format |
| .JPG | JPEG Image |
| .PNG | Portable Network Graphic |
| .PSD | Adobe Photoshop Document |
| .PSPIMAGE | PaintShop Pro Image |
| .TGA | Targa Graphic |
| .THM | Thumbnail Image File |
| .TIF | Tagged Image File |
| .TIFF | Tagged Image File Format |
| .YUV | YUV Encoded Image File |
See all raster image file types
矢量图像文件
| Extension | 文件类型 |
|---|---|
| .AI | Adobe Illustrator File |
| .EPS | Encapsulated PostScript File |
| .SVG | Scalable Vector Graphics File |
See all vector image file types
页面布局文件
See all page layout file types
电子表格文件
| Extension | 文件类型 |
|---|---|
| .XLR | Works Spreadsheet |
| .XLS | Microsoft Excel Spreadsheet (Legacy) |
| .XLSX | Microsoft Excel Spreadsheet |
See all spreadsheet file types
数据库文件
| Extension | 文件类型 |
|---|---|
| .ACCDB | Access 2007 Database File |
| .DB | Database File |
| .DBF | Database File |
| .MDB | Microsoft Access Database |
| .PDB | Program Database |
| .SQL | Structured Query Language Data File |
可执行文件
| Extension | 文件类型 |
|---|---|
| .APK | Android Package File |
| .APP | macOS Application |
| .BAT | DOS Batch File |
| .CGI | Common Gateway Interface Script |
| .COM | DOS Command File |
| .EXE | Windows Executable File |
| .GADGET | Windows Gadget |
| .JAR | Java Archive |
| .WSF | Windows Script File |
游戏文件
| Extension | 文件类型 |
|---|---|
| .B | Grand Theft Auto 3 Saved Game File |
| .DEM | Video Game Demo File |
| .GAM | Saved Game File |
| .NES | Nintendo (NES) ROM File |
| .ROM | N64 Game ROM File |
| .SAV | Saved Game |
CAD 文件
地理信息系统文件
| Extension | 文件类型 |
|---|---|
| .GPX | GPS Exchange File |
| .KML | Keyhole Markup Language File |
| .KMZ | Google Earth Placemark File |
网页文件
| Extension | File Type |
|---|---|
| .ASP | Active Server Page |
| .ASPX | Active Server Page Extended File |
| .CER | Internet Security Certificate |
| .CFM | ColdFusion Markup File |
| .CRDOWNLOAD | Chrome Partially Downloaded File |
| .CSR | Certificate Signing Request File |
| .CSS | Cascading Style Sheet |
| .DCR | Shockwave Media File |
| .HTM | Hypertext Markup Language File |
| .HTML | Hypertext Markup Language File |
| .JS | JavaScript File |
| .JSP | Jakarta Server Page |
| .PHP | PHP Source Code File |
| .RSS | Rich Site Summary |
| .XHTML | Extensible Hypertext Markup Language File |
插件文件
字体文件
| Extension | File Type |
|---|---|
| .FNT | Windows Font File |
| .FON | Windows Font Library |
| .OTF | OpenType Font |
| .TTF | TrueType Font |
系统文件
| Extension | File Type |
|---|---|
| .CAB | Windows Cabinet File |
| .CPL | Windows Control Panel Item |
| .CUR | Windows Cursor |
| .DESKTHEMEPACK | Windows 8 Desktop Theme Pack File |
| .DLL | Dynamic Link Library |
| .DMP | Windows Memory Dump |
| .DRV | Device Driver |
| .ICNS | macOS Icon Resource File |
| .ICO | Icon File |
| .LNK | Windows Shortcut |
| .SYS | Windows System File |
设置文件
| Extension | File Type |
|---|---|
| .CFG | Configuration File |
| .INI | Windows Initialization File |
| .PRF | Outlook Profile File |
编码文件
| Extension | File Type |
|---|---|
| .HQX | BinHex 4.0 Encoded File |
| .MIM | Multi-Purpose Internet Mail Message File |
| .UUE | Uuencoded File |
压缩文件
| Extension | File Type |
|---|---|
| .7Z | 7-Zip Compressed File |
| .CBR | Comic Book RAR Archive |
| .DEB | Debian Software Package |
| .GZ | Gnu Zipped Archive |
| .PKG | Mac OS X Installer Package |
| .RAR | WinRAR Compressed Archive |
| .RPM | Red Hat Package Manager File |
| .SITX | StuffIt X Archive |
| .TAR.GZ | Compressed Tarball File |
| .ZIP | Zipped File |
| .ZIPX | Extended Zip Archive |
磁盘映像文件
| Extension | File Type |
|---|---|
| .BIN | Binary Disc Image |
| .CUE | Cue Sheet File |
| .DMG | Apple Disk Image |
| .ISO | Disc Image File |
| .MDF | Media Disc Image File |
| .TOAST | Toast Disc Image |
| .VCD | Virtual CD |
开发人员文件
| Extension | File Type |
|---|---|
| .C | C/C++ Source Code File |
| .CLASS | Java Class File |
| .CPP | C++ Source Code File |
| .CS | C# Source Code File |
| .DTD | Document Type Definition File |
| .FLA | Adobe Animate Animation |
| .H | C/C++/Objective-C Header File |
| .JAVA | Java Source Code File |
| .LUA | Lua Source File |
| .M | Objective-C Implementation File |
| .PL | Perl Script |
| .PY | Python Script |
| .SH | Bash Shell Script |
| .SLN | Visual Studio Solution File |
| .SWIFT | Swift Source Code File |
| .VB | Visual Basic Project Item File |
| .VCXPROJ | Visual C++ Project |
| .XCODEPROJ | Xcode Project |
备份文件
杂项文件
| Extension | File Type |
|---|---|
| .ICS | Calendar File |
| .MSI | Windows Installer Package |
| .PART | Partially Downloaded File |
| .TORRENT | BitTorrent File |
exFAT 文件系统指南
作者: 阮一峰
日期: 2018年10月16日
国庆假期,我拍了一些手机视频,打算存到新买的移动硬盘。
然后,就傻眼了。我的 Mac 电脑无法写入移动硬盘,因为移动硬盘的默认文件系统是 NTFS,Mac 不支持写入 NTFS。

虽然可以买一个软件解决这个问题,但是我不想为这种功能付钱。经过一番研究,我发现把移动硬盘的文件系统改成 exFAT,就可以解决问题,Mac 原生支持读写 exFAT。
由于这个问题很普遍,下面我就来写一写跟 exFAT 相关的知识。
一、文件系统
所谓文件系统,就是文件的储存方式。简单说,它就是一个门牌系统,为储存设备划分门牌号,每个文件分配一个门牌,然后就能按照门牌找到文件。
没有文件系统的硬盘,就是一块荒地。如果有人住在那里,你只能说那里有人住,精确位置你说不出来。只有划分了路牌,你才能说出,这个人住在"人民路15号",这样才能精确定位。文件系统就是路牌的划分方法。

储存设备都需要指定文件系统,计算机才能读写。所谓"格式化",就是为硬盘安装文件系统。不同的操作系统有不同的文件系统,Linux 使用 ext4,OSX使用 HFS +,Windows 使用 NTFS,Solaris 和 Unix 使用ZFS。如果计算机不认识某个文件系统,就会显示这块盘无法读写。
现在的问题就是,NTFS 文件系统是 Windows 的专有系统,Mac 可以读,但是默认不能写入。
二、Windows 的文件系统
Windows 系统主要有三种文件系统。
- FAT32
- NTFS
- exFAT
格式化硬盘的时候,Windows 系统会提供这三种文件系统让你选。这时应该选哪一种呢?

FAT32 是最老的文件系统,所有操作系统都支持,兼容性最好。但是,它是为32位计算机设计的,文件不能超过 232 - 1 个字节,也就是不能超过 4GB,分区不能超过 8TB。目前来看,这个文件系统有点过时了,只适合小文件,如果有大的视频文件,就不能使用它。
NTFS 是 Windows 的默认文件系统,用来替换 FAT32。Windows 的系统盘只能使用这个系统,移动硬盘买来装的也是它。
exFAT 可以看作是 FAT32 的64位升级版,ex就是 extended 的缩写(表示"扩展的 FAT32"),功能不如 NTFS,但是解决了文件和分区的大小问题,两者最大都可以到 128PB。由于 Mac 和 Linux 电脑可以读写这种系统,所以移动硬盘的文件系统可以改成它。
三、解决方案
移动硬盘买来后,你把它格式化成 exFAT 文件系统,问题就解决了。
Windows 在资源管理器或我的电脑里面,都可以进行格式化。

Mac 在磁盘工具进行格式化。

格式化完成后,就 OK 了。如果你使用 Linux 系统,可能需要装一下 exFAT 支持,Ubuntu 和 Debian 执行下面的命令。
$ sudo apt-get install exfat-utils exfat-fuse
一般读者读到这里,就可以了。如果你像我一样,想用 Linux 进行 exFAT 格式化,请接着往下读。
四、Linux 的 exFAT 格式化
Linux 进行硬盘格式化,需要先找到设备路径。
$ sudo fdisk -l
上面命令会列出本机的所有储存设备,移动硬盘一般是/dev/sdX1的形式,比如/dev/sdc1。这里需要了解sdX1的含义,sd表示可移动设备和SATA 设备,X表示设备的序号,依次为 a、b、c 等,最后的1表示这是该设备的第一个分区。
然后,使用下面的命令进行格式化。
$ sudo mkfs.exfat /dev/sdX1
注意,如果你的储存设备只显示为/dev/sdX,没有最后的数字,表明这个设备没有分区。exFAT 只能用来格式化硬盘的一个分区,所以必须先分区,再格式化,下面介绍如何分区。
五、分区表
所谓硬盘分区,就是指一块硬盘上面,同时存在多个文件系统。每个文件系统管理的区域,就称为一个分区(partition)。比如,一块 100 GB 的硬盘,可以一半是 NTFS 分区,另一半是 exFAT 分区。
硬盘必须先分区,才能指定每个区的文件系统。分区大小、起始位置、结束位置、文件系统等信息,都储存在分区表里面。
分区表也分成两种格式:MBR 和 GPT。前者是传统格式,兼容性好;后者更现代,功能更强大。一般来说,都推荐使用 GPT。gdisk命令用于分区操作。
$ sudo gdisk /dev/sdX GPT fdisk (gdisk) version 0.8.8 Partition table scan: MBR: not present BSD: not present APM: not present GPT: not present Creating new GPT entries. Command (? for help):
上面命令表示对/dev/sdX进行分区。输出结果表明,这个设备还没有分区表。
第一步,o命令表示创建 GPT 分区表。
Command (? for help): o This option deletes all partitions and creates a new protective MBR. Proceed? (Y/N): Y
第二步,n命令表示新建一个分区。
Command (? for help): n Partition number (1-128, default 1): First sector (34-16326462, default = 2048) or {+-}size{KMGTP}: Last sector (2048-16326462, default = 16326462) or {+-}size{KMGTP}: Current type is 'Linux filesystem' Hex code or GUID (L to show codes, Enter = 8300): 0700 Changed type of partition to 'Microsoft basic data'
上面代码中,分区号(Partition number,默认为1)、起始扇区、结束扇区,都可以接受默认值,直接按回车。这时整个硬盘只建一个分区,占据所有空间。文件系统的类型要设成0700,代表 exFAT。
第三步,w命令表示写入所有变更。
Command (? for help): w Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING PARTITIONS!! Do you want to proceed? (Y/N): Y OK; writing new GUID partition table (GPT) to /dev/sdX. Warning: The kernel is still using the old partition table. The new table will be used at the next reboot. The operation has completed successfully.
到了这一步,分区表应该已经建立了。然后,使用上一节的命令,建立 exFAT 文件系统。
$ sudo mkfs.exfat /dev/sdX1 mkexfatfs 1.0.1 Creating... done. Flushing... done. File system created successfully.
六、参考链接
编译器的工作过程
日期: 2014年11月11日
源码要运行,必须先转成二进制的机器码。这是编译器的任务。
比如,下面这段源码(假定文件名叫做test.c)。
#include <stdio.h> int main(void) { fputs("Hello, world!\n", stdout); return 0; }
要先用编译器处理一下,才能运行。
$ gcc test.c $ ./a.out Hello, world!
对于复杂的项目,编译过程还必须分成三步。
$ ./configure $ make $ make install
这些命令到底在干什么?大多数的书籍和资料,都语焉不详,只说这样就可以编译了,没有进一步的解释。
本文将介绍编译器的工作过程,也就是上面这三个命令各自的任务。我主要参考了Alex Smith的文章《Building C Projects》。需要声明的是,本文主要针对gcc编译器,也就是针对C和C++,不一定适用于其他语言的编译。
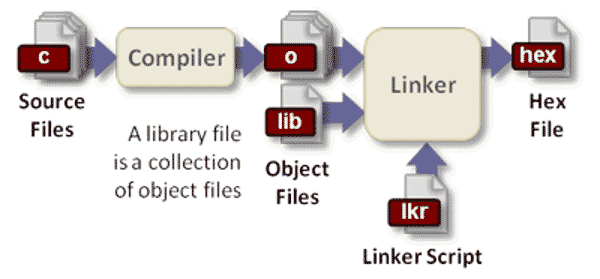
第一步 配置(configure)
编译器在开始工作之前,需要知道当前的系统环境,比如标准库在哪里、软件的安装位置在哪里、需要安装哪些组件等等。这是因为不同计算机的系统环境不一样,通过指定编译参数,编译器就可以灵活适应环境,编译出各种环境都能运行的机器码。这个确定编译参数的步骤,就叫做"配置"(configure)。
这些配置信息保存在一个配置文件之中,约定俗成是一个叫做configure的脚本文件。通常它是由autoconf工具生成的。编译器通过运行这个脚本,获知编译参数。
configure脚本已经尽量考虑到不同系统的差异,并且对各种编译参数给出了默认值。如果用户的系统环境比较特别,或者有一些特定的需求,就需要手动向configure脚本提供编译参数。
$ ./configure --prefix=/www --with-mysql
上面代码是php源码的一种编译配置,用户指定安装后的文件保存在www目录,并且编译时加入mysql模块的支持。
第二步 确定标准库和头文件的位置
源码肯定会用到标准库函数(standard library)和头文件(header)。它们可以存放在系统的任意目录中,编译器实际上没办法自动检测它们的位置,只有通过配置文件才能知道。
编译的第二步,就是从配置文件中知道标准库和头文件的位置。一般来说,配置文件会给出一个清单,列出几个具体的目录。等到编译时,编译器就按顺序到这几个目录中,寻找目标。
第三步 确定依赖关系
对于大型项目来说,源码文件之间往往存在依赖关系,编译器需要确定编译的先后顺序。假定A文件依赖于B文件,编译器应该保证做到下面两点。
(1)只有在B文件编译完成后,才开始编译A文件。
(2)当B文件发生变化时,A文件会被重新编译。
编译顺序保存在一个叫做makefile的文件中,里面列出哪个文件先编译,哪个文件后编译。而makefile文件由configure脚本运行生成,这就是为什么编译时configure必须首先运行的原因。
在确定依赖关系的同时,编译器也确定了,编译时会用到哪些头文件。
第四步 头文件的预编译(precompilation)
不同的源码文件,可能引用同一个头文件(比如stdio.h)。编译的时候,头文件也必须一起编译。为了节省时间,编译器会在编译源码之前,先编译头文件。这保证了头文件只需编译一次,不必每次用到的时候,都重新编译了。
不过,并不是头文件的所有内容,都会被预编译。用来声明宏的#define命令,就不会被预编译。
第五步 预处理(Preprocessing)
预编译完成后,编译器就开始替换掉源码中bash的头文件和宏。以本文开头的那段源码为例,它包含头文件stdio.h,替换后的样子如下。
extern int fputs(const char *, FILE *); extern FILE *stdout; int main(void) { fputs("Hello, world!\n", stdout); return 0; }
为了便于阅读,上面代码只截取了头文件中与源码相关的那部分,即fputs和FILE的声明,省略了stdio.h的其他部分(因为它们非常长)。另外,上面代码的头文件没有经过预编译,而实际上,插入源码的是预编译后的结果。编译器在这一步还会移除注释。
这一步称为"预处理"(Preprocessing),因为完成之后,就要开始真正的处理了。
第六步 编译(Compilation)
预处理之后,编译器就开始生成机器码。对于某些编译器来说,还存在一个中间步骤,会先把源码转为汇编码(assembly),然后再把汇编码转为机器码。
下面是本文开头的那段源码转成的汇编码。
.file "test.c" .section .rodata .LC0: .string "Hello, world!\n" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movq stdout(%rip), %rax movq %rax, %rcx movl $14, %edx movl $1, %esi movl $.LC0, %edi call fwrite movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Debian 4.9.1-19) 4.9.1" .section .note.GNU-stack,"",@progbits
这种转码后的文件称为对象文件(object file)。
第七步 连接(Linking)
对象文件还不能运行,必须进一步转成可执行文件。如果你仔细看上一步的转码结果,会发现其中引用了stdout函数和fwrite函数。也就是说,程序要正常运行,除了上面的代码以外,还必须有stdout和fwrite这两个函数的代码,它们是由C语言的标准库提供的。
编译器的下一步工作,就是把外部函数的代码(通常是后缀名为.lib和.a的文件),添加到可执行文件中。这就叫做连接(linking)。这种通过拷贝,将外部函数库添加到可执行文件的方式,叫做静态连接(static linking),后文会提到还有动态连接(dynamic linking)。
make命令的作用,就是从第四步头文件预编译开始,一直到做完这一步。
第八步 安装(Installation)
上一步的连接是在内存中进行的,即编译器在内存中生成了可执行文件。下一步,必须将可执行文件保存到用户事先指定的安装目录。
表面上,这一步很简单,就是将可执行文件(连带相关的数据文件)拷贝过去就行了。但是实际上,这一步还必须完成创建目录、保存文件、设置权限等步骤。这整个的保存过程就称为"安装"(Installation)。
第九步 操作系统连接
可执行文件安装后,必须以某种方式通知操作系统,让其知道可以使用这个程序了。比如,我们安装了一个文本阅读程序,往往希望双击txt文件,该程序就会自动运行。
这就要求在操作系统中,登记这个程序的元数据:文件名、文件描述、关联后缀名等等。Linux系统中,这些信息通常保存在/usr/share/applications目录下的.desktop文件中。另外,在Windows操作系统中,还需要在Start启动菜单中,建立一个快捷方式。
这些事情就叫做"操作系统连接"。make install命令,就用来完成"安装"和"操作系统连接"这两步。
第十步 生成安装包
写到这里,源码编译的整个过程就基本完成了。但是只有很少一部分用户,愿意耐着性子,从头到尾做一遍这个过程。事实上,如果你只有源码可以交给用户,他们会认定你是一个不友好的家伙。大部分用户要的是一个二进制的可执行程序,立刻就能运行。这就要求开发者,将上一步生成的可执行文件,做成可以分发的安装包。
所以,编译器还必须有生成安装包的功能。通常是将可执行文件(连带相关的数据文件),以某种目录结构,保存成压缩文件包,交给用户。
第十一步 动态连接(Dynamic linking)
正常情况下,到这一步,程序已经可以运行了。至于运行期间(runtime)发生的事情,与编译器一概无关。但是,开发者可以在编译阶段选择可执行文件连接外部函数库的方式,到底是静态连接(编译时连接),还是动态连接(运行时连接)。所以,最后还要提一下,什么叫做动态连接。
前面已经说过,静态连接就是把外部函数库,拷贝到可执行文件中。这样做的好处是,适用范围比较广,不用担心用户机器缺少某个库文件;缺点是安装包会比较大,而且多个应用程序之间,无法共享库文件。动态连接的做法正好相反,外部函数库不进入安装包,只在运行时动态引用。好处是安装包会比较小,多个应用程序可以共享库文件;缺点是用户必须事先安装好库文件,而且版本和安装位置都必须符合要求,否则就不能正常运行。
现实中,大部分软件采用动态连接,共享库文件。这种动态共享的库文件,Linux平台是后缀名为.so的文件,Windows平台是.dll文件,Mac平台是.dylib文件。
(文章完)
主引导记录的内存地址是0x7C00?
日期:2015年9月28日
《计算机原理》课本说,启动时,主引导记录会存入内存地址0x7C00。
这个的目的,是本课本不怎么解释的解释,我现在有疑问,为什么来存入内存的地址、比32其他位置偏偏存入这个地方的地址、比32KB的小1024字节?
昨天,我读到了一篇文章,终于解开了这个谜。
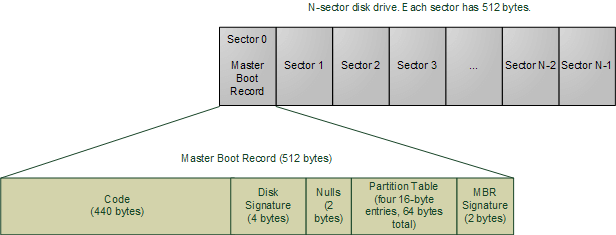
首先,如果你不知道,主引导记录(主引导记录,缩写为MBR)是什么,可以先读《计算机是如何开始的?》。
简单来说,计算机启动就是这样一个过程。
- 通电
- 读取ROM里面的BIOS,使用硬件检查
- 硬件检查通过
- BIOS根据指定的第一个顺序,检查在引导设备的第一个顺序,即在加载主引导地址时记录0x7C00
- 主引导记录把操作所有者权限
主引导就是引导所以”运行”进入内存的一段小程序,不记录1个记录。(512字节)

0x7C00 来自英特尔第一代个人电脑芯片8088的这个地址,以后的CPU为了保持这个地址,一直使用这个地址。

18 月,IBM 99 公司这8 年的个人电脑,就用了IBM PC 5150 上市的芯片。
在那里,用于的操作系统是86-DOS。这个作业需要的内存最少是32KB。我们,内存地址从0x000开始编号,32KB的内存就是86-DOS 0x0000~0x7FFF。
8088本身本身占用0x0000~0x03FF,用于保存各种中断处理程序的存放位置。(主记录就是正常的信号处理程序INT 19h。)所以,内存只剩下可以使用了0x0400~0x7FFF。
为了把多个内存留给作业,被记录下来就给了主记录。由于显示的原因,导致存储的原因是 521 需要留存的原因是 555所以,它的位置就变成了:
0x7FFF - 512 - 512 + 1 = 0x7C00
0x7C00就是这样来的。
计算机启动后,32KB内存的使用情况如下。
+--------------------- 0x0 | Interrupts vectors +--------------------- 0x400 | BIOS data area +--------------------- 0x5?? | OS load area +--------------------- 0x7C00 | Boot sector +--------------------- 0x7E00 | Boot data/stack +--------------------- 0x7FFF | (not used) +--------------------- (...)
数据库的最简单实现
日期: 2014年7月 4日
所有应用软件之中,数据库可能是最复杂的。
MySQL的手册有3000多页,PostgreSQL的手册有2000多页,Oracle的手册更是比它们相加还要厚。

但是,自己写一个最简单的数据库,做起来并不难。Reddit上面有一个帖子,只用了几百个字,就把原理讲清楚了。下面是我根据这个帖子整理的内容。
一、数据以文本形式保存
第一步,就是将所要保存的数据,写入文本文件。这个文本文件就是你的数据库。
为了方便读取,数据必须分成记录,每一条记录的长度规定为等长。比如,假定每条记录的长度是800字节,那么第5条记录的开始位置就在3200字节。
大多数时候,我们不知道某一条记录在第几个位置,只知道主键(primary key)的值。这时为了读取数据,可以一条条比对记录。但是这样做效率太低,实际应用中,数据库往往采用B树(B-tree)格式储存数据。
二、什么是B树?
要理解B树,必须从二叉查找树(Binary search tree)讲起。
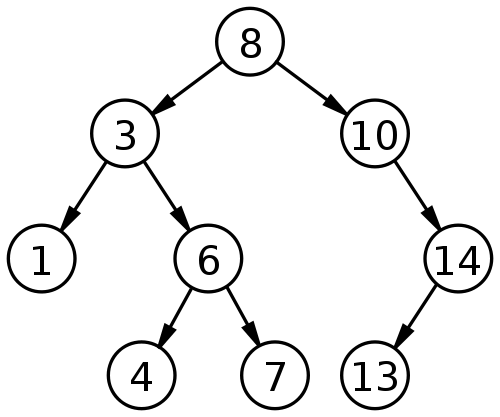
二叉查找树是一种查找效率非常高的数据结构,它有三个特点。
(1)每个节点最多只有两个子树。
(2)左子树都为小于父节点的值,右子树都为大于父节点的值。
(3)在n个节点中找到目标值,一般只需要log(n)次比较。
二叉查找树的结构不适合数据库,因为它的查找效率与层数相关。越处在下层的数据,就需要越多次比较。极端情况下,n个数据需要n次比较才能找到目标值。对于数据库来说,每进入一层,就要从硬盘读取一次数据,这非常致命,因为硬盘的读取时间远远大于数据处理时间,数据库读取硬盘的次数越少越好。
B树是对二叉查找树的改进。它的设计思想是,将相关数据尽量集中在一起,以便一次读取多个数据,减少硬盘操作次数。
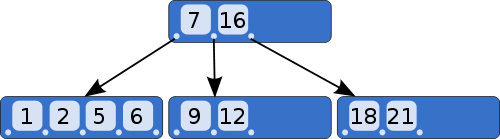
B树的特点也有三个。
(1)一个节点可以容纳多个值。比如上图中,最多的一个节点容纳了4个值。
(2)除非数据已经填满,否则不会增加新的层。也就是说,B树追求"层"越少越好。
(3)子节点中的值,与父节点中的值,有严格的大小对应关系。一般来说,如果父节点有a个值,那么就有a+1个子节点。比如上图中,父节点有两个值(7和16),就对应三个子节点,第一个子节点都是小于7的值,最后一个子节点都是大于16的值,中间的子节点就是7和16之间的值。
这种数据结构,非常有利于减少读取硬盘的次数。假定一个节点可以容纳100个值,那么3层的B树可以容纳100万个数据,如果换成二叉查找树,则需要20层!假定操作系统一次读取一个节点,并且根节点保留在内存中,那么B树在100万个数据中查找目标值,只需要读取两次硬盘。
三、索引
数据库以B树格式储存,只解决了按照"主键"查找数据的问题。如果想查找其他字段,就需要建立索引(index)。
所谓索引,就是以某个字段为关键字的B树文件。假定有一张"雇员表",包含了员工号(主键)和姓名两个字段。可以对姓名建立索引文件,该文件以B树格式对姓名进行储存,每个姓名后面是其在数据库中的位置(即第几条记录)。查找姓名的时候,先从索引中找到对应第几条记录,然后再从表格中读取。
这种索引查找方法,叫做"索引顺序存取方法"(Indexed Sequential Access Method),缩写为ISAM。它已经有多种实现(比如C-ISAM库和D-ISAM库),只要使用这些代码库,就能自己写一个最简单的数据库。
四、高级功能
部署了最基本的数据存取(包括索引)以后,还可以实现一些高级功能。
(1)SQL语言是数据库通用操作语言,所以需要一个SQL解析器,将SQL命令解析为对应的ISAM操作。
(2)数据库连接(join)是指数据库的两张表通过"外键",建立连接关系。你需要对这种操作进行优化。
(3)数据库事务(transaction)是指批量进行一系列数据库操作,只要有一步不成功,整个操作都不成功。所以需要有一个"操作日志",以便失败时对操作进行回滚。
(4)备份机制:保存数据库的副本。
(5)远程操作:使得用户可以在不同的机器上,通过TCP/IP协议操作数据库。
(完)
如何验证 Email 地址
作者: 阮一峰
日期: 2017年6月25日
Email 是最常用的用户识别手段。
开发者常常需要验证邮箱的真实性。一般的方法是,注册时向该邮箱发出一封验证邮件,要求用户点击邮件里面的链接。
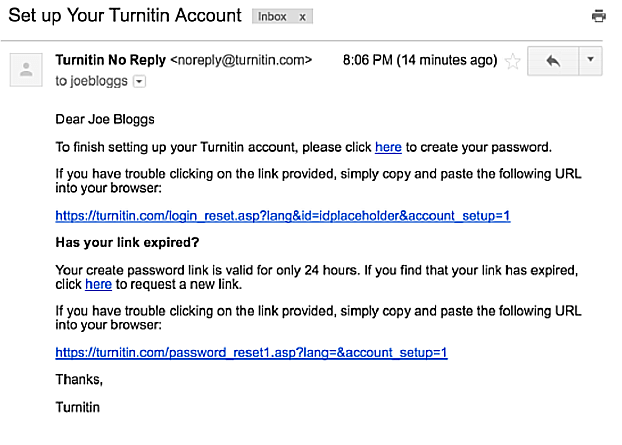
但是很多时候(比如要搞邮件营销时),拿到的是成千上万现成的 Email 地址,不可能通过回复确认真实性,这时该怎么办呢?
答案就是使用 SMTP 协议。本文将介绍如何通过该协议验证邮箱的真假。

另外,结尾处还有一则移动端 H5 开发的培训消息,欢迎关注。
一、SMTP 协议简介
SMTP 是"简单邮件传输协议"(Simple Mail Transfer Protocol)的缩写,基于 TCP 协议,用来发送电子邮件。
只要运行了该协议的服务器端(daemon),当前服务器就变为邮件服务器,可以接收电子邮件。
验证 Email 邮箱的基本思路如下。
- 找到邮箱所在域名的 SMTP 服务器
- 连接该服务器
- 询问有没有该邮箱
- 如果服务器返回 250 或 251 状态码,邮箱就是真的;如果返回 5xx(500~599),就是假的。
注意,即使服务器确认邮箱是真的, 也不代表邮件一定会发送到该邮箱,更不代表用户一定会读到该邮件。
二、查找域名的 MX 记录
下面通过一个例子,演示如何验证test@gmail.com这个邮箱。
首先,需要查找gmail.com 的 MX 记录。它指向真正处理邮件的那台服务器。
$ nslookup >
输入nslookup命令后,会提示一个大于号,表示等待用户进一步输入。
> set q=mx > gmail.com
上面代码中,set q=mx设定查询的是 MX 记录,第二行输入要查找的域名,结果返回了5条 MX 记录。
Server: 192.168.1.1 Address: 192.168.1.1#53 Non-authoritative answer: gmail.com mail exchanger = 20 alt2.gmail-smtp-in.l.google.com. gmail.com mail exchanger = 30 alt3.gmail-smtp-in.l.google.com. gmail.com mail exchanger = 10 alt1.gmail-smtp-in.l.google.com. gmail.com mail exchanger = 5 gmail-smtp-in.l.google.com. gmail.com mail exchanger = 40 alt4.gmail-smtp-in.l.google.com.
gmail.com是很大的邮件服务商,所以会有多条记录,一般的域名只有一条。如果这一步查不到 MX 记录,该邮箱肯定是假的。
除了自己执行nslookup,也可以使用线上服务(1,2,3)。更多 DNS 的介绍,请参考《DNS 原理入门》。
三、建立 TCP 连接
知道了邮件服务器的地址,就可以与它建立 TCP 连接了。SMTP 协议的默认端口是25。使用 Telnet 或 Netcat 命令,都可以连接该端口。
$ telnet gmail-smtp-in.l.google.com 25 # 或者 $ nc gmail-smtp-in.l.google.com 25
服务器返回220状态码,就表示连接成功。
220 mx.google.com ESMTP f14si7006176pln.607 - gsmtp
接下来,就可以使用 SMTP 协议的各种命令与邮件服务器交互了。
四、HELO 命令和 EHLO 命令
SMTP 协议规定,连接成功后,必须向邮件服务器提供连接的域名,也就是邮件将从哪台服务器发来。
假定从mail@example.com向test@gmail.com发送邮件,这里要提供的域名就是example.com。
HELO exampl.com
邮件服务器返回状态码250,表示响应成功。
250 mx.google.com at your service
不过,HELO命令现在比较少用,一般都使用EHLO命令。
EHLO example.com
邮件服务器收到EHLO命令以后,不仅会返回250状态码,还会返回自己支持的各种扩展的列表。
250-mx.google.com at your service, [114.84.160.153] 250-SIZE 157286400 250-8BITMIME 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-PIPELINING 250-CHUNKING 250 SMTPUTF8
五、MAIL FROM 命令
然后,连接者要使用MAIL FROM命令,向邮件服务器提供邮件的来源邮箱。
MAIL FROM:<mail@example.com>
上面代码表示,连接者将从mail@example.com向邮件服务器发送邮件。邮件服务器返回250状态码,表示响应成功。
250 2.1.0 OK h10si3194349otb.59 - gsmtp
SMTP 是一个很简单的协议,本身没有规定如何验证邮件的来源,也就是说,不验证邮件是否真的从mail@example.com发来,所以导致了后来垃圾邮件泛滥。为了控制垃圾邮件,许多邮件服务器会用自己的方法验证邮件地址,下面就是其中的一些方法。
- example.com 是否有 MX 记录
- example.com 是否可以 Ping 通
- 是否存在 postmaster@example.com 这个邮箱
- 发起连接的 IP 地址是否在黑名单之中
- IP 地址的反向 DNS 解析,是否指向一个邮件服务器
六、RCPT TO 命令
最后一步就是使用RCPT TO命令,验证邮件地址是否存在。
RCPT TO:<test@gmail.com>
邮件服务器返回了550状态码,表示该 Email 地址不存在。
550-5.1.1 The email account that you tried to reach does not exist. Please try 550-5.1.1 double-checking the recipient's email address for typos or 550-5.1.1 unnecessary spaces. Learn more at 550 5.1.1 https://support.google.com/mail/?p=NoSuchUser p34si3372771otp.228 - gsmtp
如果查询的是一个真实的 Email 地址,邮件服务器就会返回250状态码。
RCPT TO:<yifeng.ruan@gmail.com> 250 2.1.5 OK p34si3372771otp.228 - gsmtp
一般来说,状态码 250 和 251 都表示邮箱存在,状态码 5xx 表示不存在,其他状态码(主要是 4xx)则代表无法确认。
RCPT TO:<xxx@censored.pl> 451 Temporary local problem - please try later
验证完成后,使用QUIT命令关闭 TCP 连接。
QUIT 221 2.0.0 closing connection p34si3372771otp.228 - gsmtp
七、参考链接
Linux 的启动流程
日期: 2013年8月17日
半年前,我写了《计算机是如何启动的?》,探讨BIOS和主引导记录的作用。
那篇文章不涉及操作系统,只与主板的板载程序有关。今天,我想接着往下写,探讨操作系统接管硬件以后发生的事情,也就是操作系统的启动流程。
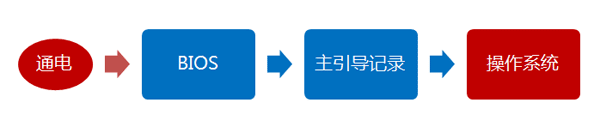
这个部分比较有意思。因为在BIOS阶段,计算机的行为基本上被写死了,程序员可以做的事情并不多;但是,一旦进入操作系统,程序员几乎可以定制所有方面。所以,这个部分与程序员的关系更密切。
我主要关心的是Linux操作系统,它是目前服务器端的主流操作系统。下面的内容针对的是Debian发行版,因为我对其他发行版不够熟悉。
第一步、加载内核
操作系统接管硬件以后,首先读入 /boot 目录下的内核文件。

以我的电脑为例,/boot 目录下面大概是这样一些文件:
$ ls /boot config-3.2.0-3-amd64 config-3.2.0-4-amd64 grub initrd.img-3.2.0-3-amd64 initrd.img-3.2.0-4-amd64 System.map-3.2.0-3-amd64 System.map-3.2.0-4-amd64 vmlinuz-3.2.0-3-amd64 vmlinuz-3.2.0-4-amd64
第二步、启动初始化进程
内核文件加载以后,就开始运行第一个程序 /sbin/init,它的作用是初始化系统环境。
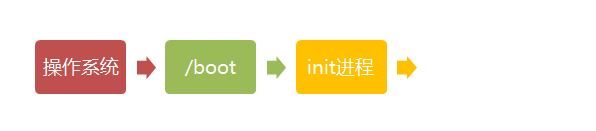
由于init是第一个运行的程序,它的进程编号(pid)就是1。其他所有进程都从它衍生,都是它的子进程。
第三步、确定运行级别
许多程序需要开机启动。它们在Windows叫做"服务"(service),在Linux就叫做"守护进程"(daemon)。
init进程的一大任务,就是去运行这些开机启动的程序。但是,不同的场合需要启动不同的程序,比如用作服务器时,需要启动Apache,用作桌面就不需要。Linux允许为不同的场合,分配不同的开机启动程序,这就叫做"运行级别"(runlevel)。也就是说,启动时根据"运行级别",确定要运行哪些程序。

Linux预置七种运行级别(0-6)。一般来说,0是关机,1是单用户模式(也就是维护模式),6是重启。运行级别2-5,各个发行版不太一样,对于Debian来说,都是同样的多用户模式(也就是正常模式)。
init进程首先读取文件 /etc/inittab,它是运行级别的设置文件。如果你打开它,可以看到第一行是这样的:
id:2:initdefault:
initdefault的值是2,表明系统启动时的运行级别为2。如果需要指定其他级别,可以手动修改这个值。
那么,运行级别2有些什么程序呢,系统怎么知道每个级别应该加载哪些程序呢?......回答是每个运行级别在/etc目录下面,都有一个对应的子目录,指定要加载的程序。
/etc/rc0.d /etc/rc1.d /etc/rc2.d /etc/rc3.d /etc/rc4.d /etc/rc5.d /etc/rc6.d
上面目录名中的"rc",表示run command(运行程序),最后的d表示directory(目录)。下面让我们看看 /etc/rc2.d 目录中到底指定了哪些程序。
$ ls /etc/rc2.d README S01motd S13rpcbind S14nfs-common S16binfmt-support S16rsyslog S16sudo S17apache2 S18acpid ...
可以看到,除了第一个文件README以外,其他文件名都是"字母S+两位数字+程序名"的形式。字母S表示Start,也就是启动的意思(启动脚本的运行参数为start),如果这个位置是字母K,就代表Kill(关闭),即如果从其他运行级别切换过来,需要关闭的程序(启动脚本的运行参数为stop)。后面的两位数字表示处理顺序,数字越小越早处理,所以第一个启动的程序是motd,然后是rpcbing、nfs......数字相同时,则按照程序名的字母顺序启动,所以rsyslog会先于sudo启动。
这个目录里的所有文件(除了README),就是启动时要加载的程序。如果想增加或删除某些程序,不建议手动修改 /etc/rcN.d 目录,最好是用一些专门命令进行管理(参考这里和这里)。
第四步、加载开机启动程序
前面提到,七种预设的"运行级别"各自有一个目录,存放需要开机启动的程序。不难想到,如果多个"运行级别"需要启动同一个程序,那么这个程序的启动脚本,就会在每一个目录里都有一个拷贝。这样会造成管理上的困扰:如果要修改启动脚本,岂不是每个目录都要改一遍?
Linux的解决办法,就是七个 /etc/rcN.d 目录里列出的程序,都设为链接文件,指向另外一个目录 /etc/init.d ,真正的启动脚本都统一放在这个目录中。init进程逐一加载开机启动程序,其实就是运行这个目录里的启动脚本。
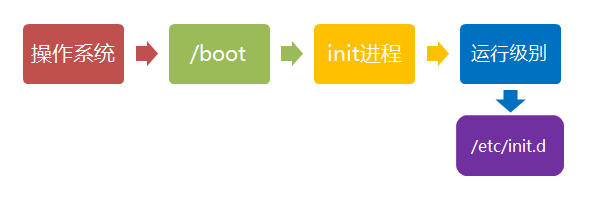
下面就是链接文件真正的指向。
$ ls -l /etc/rc2.d README S01motd -> ../init.d/motd S13rpcbind -> ../init.d/rpcbind S14nfs-common -> ../init.d/nfs-common S16binfmt-support -> ../init.d/binfmt-support S16rsyslog -> ../init.d/rsyslog S16sudo -> ../init.d/sudo S17apache2 -> ../init.d/apache2 S18acpid -> ../init.d/acpid ...
这样做的另一个好处,就是如果你要手动关闭或重启某个进程,直接到目录 /etc/init.d 中寻找启动脚本即可。比如,我要重启Apache服务器,就运行下面的命令:
$ sudo /etc/init.d/apache2 restart
/etc/init.d 这个目录名最后一个字母d,是directory的意思,表示这是一个目录,用来与程序 /etc/init 区分。
第五步、用户登录
开机启动程序加载完毕以后,就要让用户登录了。
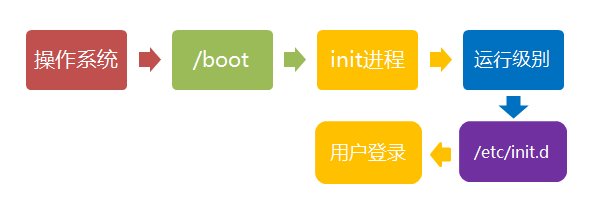
一般来说,用户的登录方式有三种:
(1)命令行登录
(2)ssh登录
(3)图形界面登录
这三种情况,都有自己的方式对用户进行认证。
(1)命令行登录:init进程调用getty程序(意为get teletype),让用户输入用户名和密码。输入完成后,再调用login程序,核对密码(Debian还会再多运行一个身份核对程序/etc/pam.d/login)。如果密码正确,就从文件 /etc/passwd 读取该用户指定的shell,然后启动这个shell。
(2)ssh登录:这时系统调用sshd程序(Debian还会再运行/etc/pam.d/ssh ),取代getty和login,然后启动shell。
(3)图形界面登录:init进程调用显示管理器,Gnome图形界面对应的显示管理器为gdm(GNOME Display Manager),然后用户输入用户名和密码。如果密码正确,就读取/etc/gdm3/Xsession,启动用户的会话。
第六步、进入 login shell
所谓shell,简单说就是命令行界面,让用户可以直接与操作系统对话。用户登录时打开的shell,就叫做login shell。
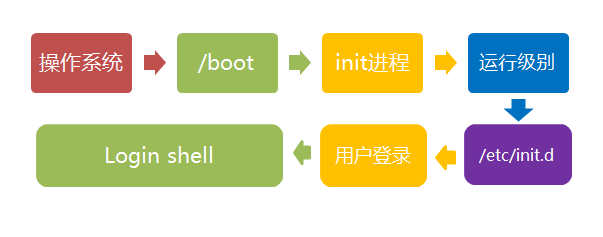
Debian默认的shell是Bash,它会读入一系列的配置文件。上一步的三种情况,在这一步的处理,也存在差异。
(1)命令行登录:首先读入 /etc/profile,这是对所有用户都有效的配置;然后依次寻找下面三个文件,这是针对当前用户的配置。
~/.bash_profile ~/.bash_login ~/.profile
需要注意的是,这三个文件只要有一个存在,就不再读入后面的文件了。比如,要是 ~/.bash_profile 存在,就不会再读入后面两个文件了。
(2)ssh登录:与第一种情况完全相同。
(3)图形界面登录:只加载 /etc/profile 和 ~/.profile。也就是说,~/.bash_profile 不管有没有,都不会运行。
第七步,打开 non-login shell
老实说,上一步完成以后,Linux的启动过程就算结束了,用户已经可以看到命令行提示符或者图形界面了。但是,为了内容的完整,必须再介绍一下这一步。
用户进入操作系统以后,常常会再手动开启一个shell。这个shell就叫做 non-login shell,意思是它不同于登录时出现的那个shell,不读取/etc/profile和.profile等配置文件。
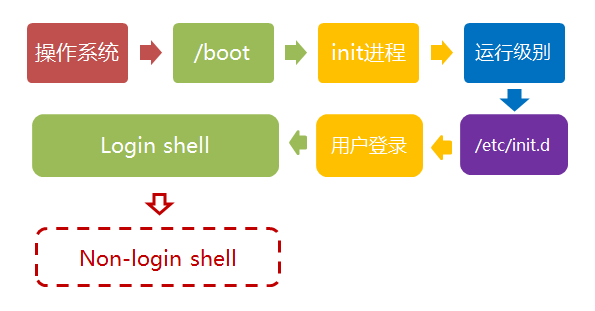
non-login shell的重要性,不仅在于它是用户最常接触的那个shell,还在于它会读入用户自己的bash配置文件 ~/.bashrc。大多数时候,我们对于bash的定制,都是写在这个文件里面的。
你也许会问,要是不进入 non-login shell,岂不是.bashrc就不会运行了,因此bash 也就不能完成定制了?事实上,Debian已经考虑到这个问题了,请打开文件 ~/.profile,可以看到下面的代码:
if [ -n "$BASH_VERSION" ]; then if [ -f "$HOME/.bashrc" ]; then . "$HOME/.bashrc" fi fi
上面代码先判断变量 $BASH_VERSION 是否有值,然后判断主目录下是否存在 .bashrc 文件,如果存在就运行该文件。第三行开头的那个点,是source命令的简写形式,表示运行某个文件,写成"source ~/.bashrc"也是可以的。
因此,只要运行~/.profile文件,~/.bashrc文件就会连带运行。但是上一节的第一种情况提到过,如果存在~/.bash_profile文件,那么有可能不会运行~/.profile文件。解决这个问题很简单,把下面代码写入.bash_profile就行了。
if [ -f ~/.profile ]; then . ~/.profile fi
这样一来,不管是哪种情况,.bashrc都会执行,用户的设置可以放心地都写入这个文件了。
Bash的设置之所以如此繁琐,是由于历史原因造成的。早期的时候,计算机运行速度很慢,载入配置文件需要很长时间,Bash的作者只好把配置文件分成了几个部分,阶段性载入。系统的通用设置放在 /etc/profile,用户个人的、需要被所有子进程继承的设置放在.profile,不需要被继承的设置放在.bashrc。
顺便提一下,除了Linux以外, Mac OS X 使用的shell也是Bash。但是,它只加载.bash_profile,然后在.bash_profile里面调用.bashrc。而且,不管是ssh登录,还是在图形界面里启动shell窗口,都是如此。
参考链接
[1] Debian Wiki, Environment Variables
[2] Debian Wiki, Dot Files
[3] Debian Administration, An introduction to run-levels
[4] Debian Admin,Debian and Ubuntu Linux Run Levels
[5] Linux Information Project (LINFO), Runlevel Definition
[6] LinuxQuestions.org, What are run levels?
[7] Dalton Hubble, Bash Configurations Demystified
Nativefier 详细设置
安装工具
第一行命令:
npm install nativefier -g
制作应用
第二行命令:
nativefier "https://mr-houzi.github.io/"
附加内容
设置名字
nativefier在制作应用的时候,可以自动识别网站的名字,您也可以自己设置名字。
nativefier --name "AppName" "https://mr-houzi.github.io/"
设置图标
nativefier --icon <path>
Windows和Linux打包
icon参数应该是.png文件的路径。
OSX打包
如果安装了可选的依赖关系,icon参数可以是a .icns或.png文件。
指定输出不同系统的应用
默认情况下,会根据当前操作系统,输出对应系统的应用。如果您需要特殊指定转换成不同系统的应用,可以 使用一下命令。
nativefier --p <value>
可选参数linux、windows、osx。
替代值win32(用于Windows)或darwin,mac(对于OSX)也可以使用。
显示菜单栏
指定是否应该显示菜单栏。
禁用上下文菜单
--disable-context-menu
禁用上下文菜单
单实例
--single-instance
阻止应用程序多次运行。如果发生这种尝试,那么已经运行的实例就会出现在前面。
托盘
--tray
应用程序将保留为系统托盘中的图标。通过点击窗口关闭按钮来防止关闭应用程序。
设置应用版权
nativefier --app-copyright <value>
应用的版权信息会映射到Windows系统的LegalCopyright和OS X系统的NSHumanReadableCopyright的元数据属性。
设置显示
宽度
--width <value>
打包应用程序的宽度,默认为1280px。
高度
--height <value>
打包应用程序的高度,默认为800px。
最小宽度
--min-width <value>
打包应用程序的最小宽度,默认为0。
最小高度
--min-height <value>
打包应用程序的最小高度,默认为0。
最大宽度
--max-width <value>
打包应用程序的最大宽度,默认为无限制。
最大高度
--max-height <value>
打包应用程序的最大高度,默认为无限制。
X
--x <value>
打包的应用程序窗口的X位置。
Y
--y <value>
打包的应用程序窗口的Y位置。
修改网址
resources\app\nativefier.json
| 代码 | 内容 | 默认 |
| 名称 | --name | 云盘登录 2.0 |
| 图标 | --icon |
Windows、Linux打包 icon参数是 .png文件的路径【D:\app\favicon.ico】 OSX打包 如果安装了可选的依赖关系,icon参数可以是 a .icns或 .png文件 |
| 平台 | --platform | Linux / Windows |
| 架构 | --arch | |
| 托盘 | --tray | 应用程序将保留为系统托盘中的图标。通过点击窗口关闭按钮来防止关闭应用程序 |
| 显示菜单栏 | -m, --show-menu-bar | 指定是否应该显示菜单栏 |
| 指定输出不同系统的应用 | nativefier --p <value> | linux、windows / win32、osx / darwin /mac |
| 单实例 | --single-instance | 阻止应用程序多次运行。如果发生这种尝试,那么已经运行的实例就会出现在前面 |
| 禁用上下文菜单 | --disable-context-menu | |
| 版权 | nativefier --app-copyright <value> | 应用的版权信息会映射到Windows系统的LegalCopyright和OS X系统的NSHumanReadableCopyright的元数据属性。 |
|
将本地网页制作成程序,在生成的命令里面添加指向的 HTML 文件,如下: nativefier --name "Sample" "index.html" |
||
| 设置显示 | ||
| 宽度 | --width <value> | 1280px |
| 高度 | --height <value> | 800px |
| 最小宽度 | --min-width <value> | 0 |
| 最小高度 | --min-height <value> | 0 |
| 最大宽度 | --max-width <value> | 无限制 |
| 最大高度 | --max-height <value> | 无限制 |
| X | --x <value> | 应用程序窗口的X位置 |
| Y | --y <value> | 应用程序窗口的Y位置 |
| --tray | 托盘图标 | |
| --disable-dev-tools | 禁用 Chrome 开发工具 | |
| --single-instance | 只允许应用的一个实例 | |
DNS 原理入门
作者: 阮一峰
日期: 2016年6月16日
DNS 是互联网核心协议之一。不管是上网浏览,还是编程开发,都需要了解一点它的知识。
本文详细介绍DNS的原理,以及如何运用工具软件观察它的运作。我的目标是,读完此文后,你就能完全理解DNS。

一、DNS 是什么?
DNS (Domain Name System 的缩写)的作用非常简单,就是根据域名查出IP地址。你可以把它想象成一本巨大的电话本。
举例来说,如果你要访问域名math.stackexchange.com,首先要通过DNS查出它的IP地址是151.101.129.69。
如果你不清楚为什么一定要查出IP地址,才能进行网络通信,建议先阅读我写的《互联网协议入门》。
二、查询过程
虽然只需要返回一个IP地址,但是DNS的查询过程非常复杂,分成多个步骤。
工具软件dig可以显示整个查询过程。
$ dig math.stackexchange.com
上面的命令会输出六段信息。
第一段是查询参数和统计。

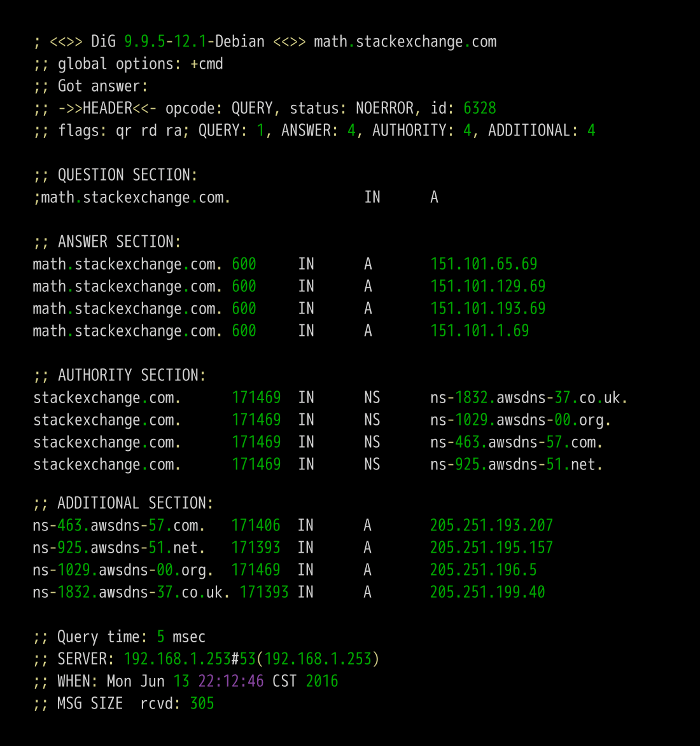
第二段是查询内容。
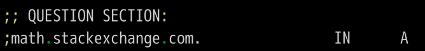
上面结果表示,查询域名math.stackexchange.com的A记录,A是address的缩写。
第三段是DNS服务器的答复。
上面结果显示,math.stackexchange.com有四个A记录,即四个IP地址。600是TTL值(Time to live 的缩写),表示缓存时间,即600秒之内不用重新查询。
第四段显示stackexchange.com的NS记录(Name Server的缩写),即哪些服务器负责管理stackexchange.com的DNS记录。

上面结果显示stackexchange.com共有四条NS记录,即四个域名服务器,向其中任一台查询就能知道math.stackexchange.com的IP地址是什么。
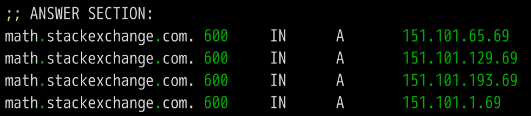
第五段是上面四个域名服务器的IP地址,这是随着前一段一起返回的。
第六段是DNS服务器的一些传输信息。
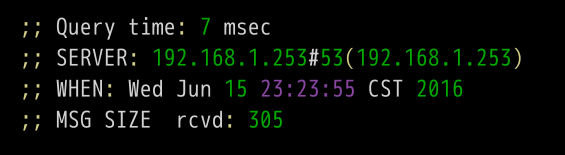
上面结果显示,本机的DNS服务器是192.168.1.253,查询端口是53(DNS服务器的默认端口),以及回应长度是305字节。
如果不想看到这么多内容,可以使用+short参数。
$ dig +short math.stackexchange.com 151.101.129.69 151.101.65.69 151.101.193.69 151.101.1.69
上面命令只返回math.stackexchange.com对应的4个IP地址(即A记录)。
三、DNS服务器
下面我们根据前面这个例子,一步步还原,本机到底怎么得到域名math.stackexchange.com的IP地址。
首先,本机一定要知道DNS服务器的IP地址,否则上不了网。通过DNS服务器,才能知道某个域名的IP地址到底是什么。
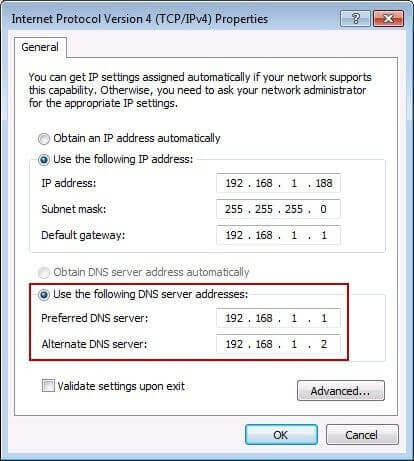
DNS服务器的IP地址,有可能是动态的,每次上网时由网关分配,这叫做DHCP机制;也有可能是事先指定的固定地址。Linux系统里面,DNS服务器的IP地址保存在/etc/resolv.conf文件。
上例的DNS服务器是192.168.1.253,这是一个内网地址。有一些公网的DNS服务器,也可以使用,其中最有名的就是Google的8.8.8.8和Level 3的4.2.2.2。
本机只向自己的DNS服务器查询,dig命令有一个@参数,显示向其他DNS服务器查询的结果。
$ dig @4.2.2.2 math.stackexchange.com
上面命令指定向DNS服务器4.2.2.2查询。
四、域名的层级
DNS服务器怎么会知道每个域名的IP地址呢?答案是分级查询。
请仔细看前面的例子,每个域名的尾部都多了一个点。
比如,域名math.stackexchange.com显示为math.stackexchange.com.。这不是疏忽,而是所有域名的尾部,实际上都有一个根域名。
举例来说,www.example.com真正的域名是www.example.com.root,简写为www.example.com.。因为,根域名.root对于所有域名都是一样的,所以平时是省略的。
根域名的下一级,叫做"顶级域名"(top-level domain,缩写为TLD),比如.com、.net;再下一级叫做"次级域名"(second-level domain,缩写为SLD),比如www.example.com里面的.example,这一级域名是用户可以注册的;再下一级是主机名(host),比如www.example.com里面的www,又称为"三级域名",这是用户在自己的域里面为服务器分配的名称,是用户可以任意分配的。
总结一下,域名的层级结构如下。
主机名.次级域名.顶级域名.根域名 # 即 host.sld.tld.root
五、根域名服务器
DNS服务器根据域名的层级,进行分级查询。
需要明确的是,每一级域名都有自己的NS记录,NS记录指向该级域名的域名服务器。这些服务器知道下一级域名的各种记录。
所谓"分级查询",就是从根域名开始,依次查询每一级域名的NS记录,直到查到最终的IP地址,过程大致如下。
- 从"根域名服务器"查到"顶级域名服务器"的NS记录和A记录(IP地址)
- 从"顶级域名服务器"查到"次级域名服务器"的NS记录和A记录(IP地址)
- 从"次级域名服务器"查出"主机名"的IP地址
仔细看上面的过程,你可能发现了,没有提到DNS服务器怎么知道"根域名服务器"的IP地址。回答是"根域名服务器"的NS记录和IP地址一般是不会变化的,所以内置在DNS服务器里面。
下面是内置的根域名服务器IP地址的一个例子。
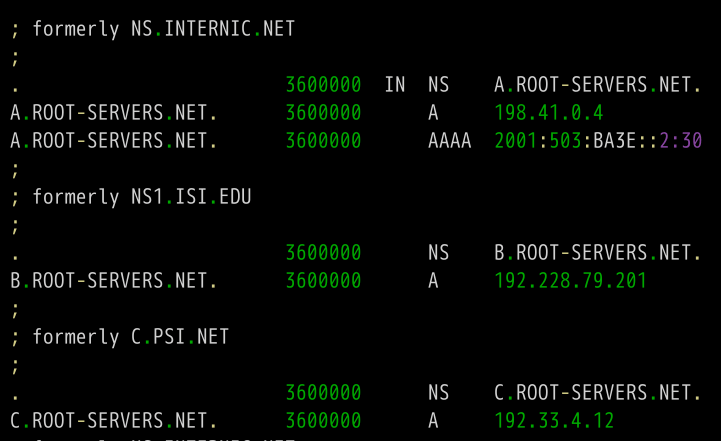
上面列表中,列出了根域名(.root)的三条NS记录A.ROOT-SERVERS.NET、B.ROOT-SERVERS.NET和C.ROOT-SERVERS.NET,以及它们的IP地址(即A记录)198.41.0.4、192.228.79.201、192.33.4.12。
另外,可以看到所有记录的TTL值是3600000秒,相当于1000小时。也就是说,每1000小时才查询一次根域名服务器的列表。
目前,世界上一共有十三组根域名服务器,从A.ROOT-SERVERS.NET一直到M.ROOT-SERVERS.NET。
六、分级查询的实例
dig命令的+trace参数可以显示DNS的整个分级查询过程。
$ dig +trace math.stackexchange.com
上面命令的第一段列出根域名.的所有NS记录,即所有根域名服务器。
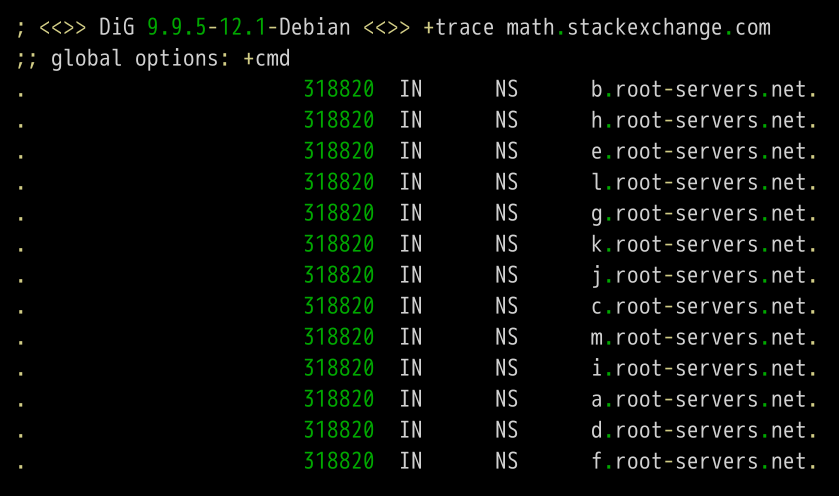
根据内置的根域名服务器IP地址,DNS服务器向所有这些IP地址发出查询请求,询问math.stackexchange.com的顶级域名服务器com.的NS记录。最先回复的根域名服务器将被缓存,以后只向这台服务器发请求。
接着是第二段。
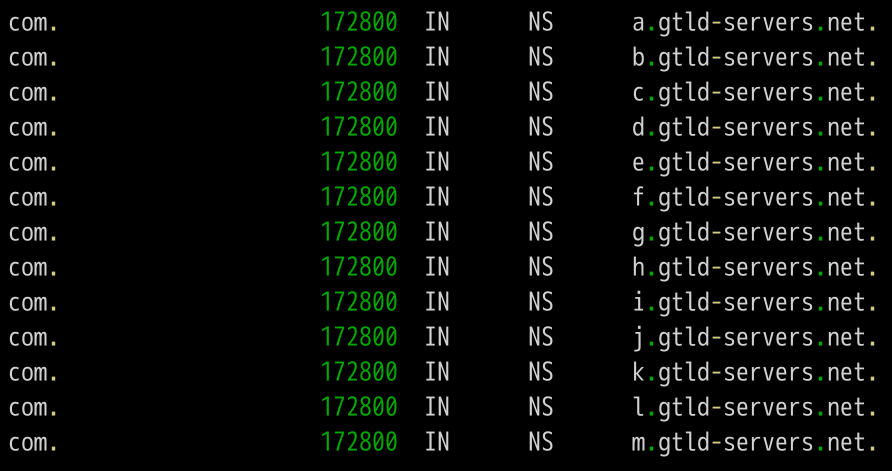
上面结果显示.com域名的13条NS记录,同时返回的还有每一条记录对应的IP地址。
然后,DNS服务器向这些顶级域名服务器发出查询请求,询问math.stackexchange.com的次级域名stackexchange.com的NS记录。

上面结果显示stackexchange.com有四条NS记录,同时返回的还有每一条NS记录对应的IP地址。
然后,DNS服务器向上面这四台NS服务器查询math.stackexchange.com的主机名。
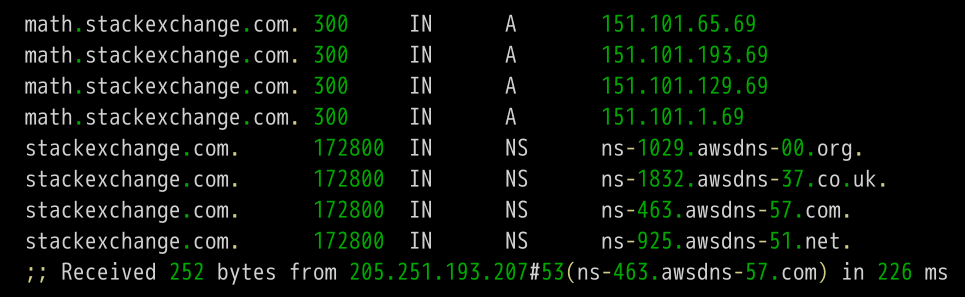
上面结果显示,math.stackexchange.com有4条A记录,即这四个IP地址都可以访问到网站。并且还显示,最先返回结果的NS服务器是ns-463.awsdns-57.com,IP地址为205.251.193.207。
七、NS 记录的查询
dig命令可以单独查看每一级域名的NS记录。
$ dig ns com $ dig ns stackexchange.com
+short参数可以显示简化的结果。
$ dig +short ns com $ dig +short ns stackexchange.com
八、DNS的记录类型
域名与IP之间的对应关系,称为"记录"(record)。根据使用场景,"记录"可以分成不同的类型(type),前面已经看到了有A记录和NS记录。
常见的DNS记录类型如下。
(1)
A:地址记录(Address),返回域名指向的IP地址。(2)
NS:域名服务器记录(Name Server),返回保存下一级域名信息的服务器地址。该记录只能设置为域名,不能设置为IP地址。(3)
MX:邮件记录(Mail eXchange),返回接收电子邮件的服务器地址。(4)
CNAME:规范名称记录(Canonical Name),返回另一个域名,即当前查询的域名是另一个域名的跳转,详见下文。(5)
PTR:逆向查询记录(Pointer Record),只用于从IP地址查询域名,详见下文。
一般来说,为了服务的安全可靠,至少应该有两条NS记录,而A记录和MX记录也可以有多条,这样就提供了服务的冗余性,防止出现单点失败。
CNAME记录主要用于域名的内部跳转,为服务器配置提供灵活性,用户感知不到。举例来说,facebook.github.io这个域名就是一个CNAME记录。
$ dig facebook.github.io ... ;; ANSWER SECTION: facebook.github.io. 3370 IN CNAME github.map.fastly.net. github.map.fastly.net. 600 IN A 103.245.222.133
上面结果显示,facebook.github.io的CNAME记录指向github.map.fastly.net。也就是说,用户查询facebook.github.io的时候,实际上返回的是github.map.fastly.net的IP地址。这样的好处是,变更服务器IP地址的时候,只要修改github.map.fastly.net这个域名就可以了,用户的facebook.github.io域名不用修改。
由于CNAME记录就是一个替换,所以域名一旦设置CNAME记录以后,就不能再设置其他记录了(比如A记录和MX记录),这是为了防止产生冲突。举例来说,foo.com指向bar.com,而两个域名各有自己的MX记录,如果两者不一致,就会产生问题。由于顶级域名通常要设置MX记录,所以一般不允许用户对顶级域名设置CNAME记录。
PTR记录用于从IP地址反查域名。dig命令的-x参数用于查询PTR记录。
$ dig -x 192.30.252.153 ... ;; ANSWER SECTION: 153.252.30.192.in-addr.arpa. 3600 IN PTR pages.github.com.
上面结果显示,192.30.252.153这台服务器的域名是pages.github.com。
逆向查询的一个应用,是可以防止垃圾邮件,即验证发送邮件的IP地址,是否真的有它所声称的域名。
dig命令可以查看指定的记录类型。
$ dig a github.com $ dig ns github.com $ dig mx github.com
九、其他DNS工具
除了dig,还有一些其他小工具也可以使用。
(1)host 命令
host命令可以看作dig命令的简化版本,返回当前请求域名的各种记录。
$ host github.com github.com has address 192.30.252.121 github.com mail is handled by 5 ALT2.ASPMX.L.GOOGLE.COM. github.com mail is handled by 10 ALT4.ASPMX.L.GOOGLE.COM. github.com mail is handled by 10 ALT3.ASPMX.L.GOOGLE.COM. github.com mail is handled by 5 ALT1.ASPMX.L.GOOGLE.COM. github.com mail is handled by 1 ASPMX.L.GOOGLE.COM. $ host facebook.github.com facebook.github.com is an alias for github.map.fastly.net. github.map.fastly.net has address 103.245.222.133
host命令也可以用于逆向查询,即从IP地址查询域名,等同于dig -x <ip>。
$ host 192.30.252.153 153.252.30.192.in-addr.arpa domain name pointer pages.github.com.
(2)nslookup 命令
nslookup命令用于互动式地查询域名记录。
$ nslookup > facebook.github.io Server: 192.168.1.253 Address: 192.168.1.253#53 Non-authoritative answer: facebook.github.io canonical name = github.map.fastly.net. Name: github.map.fastly.net Address: 103.245.222.133 >
(3)whois 命令
whois命令用来查看域名的注册情况。
$ whois github.com
HTML/框架
HTML
框架用于将网页划分为不同的部分。帧可以用作优秀的导航工具,例如,一个帧可以专用于超链接,而另一个帧可以用于打开内容。
优点:
- 使用框架进行站点维护相对容易
- 使用框架,我们可以显示其他网站的内容,而无需用户离开您自己的网站
缺点:
- 搜索引擎没有很好地索引框架网站。搜索的结果可能会将您的documnets显示在帧外,从而丢失使用帧开发的导航和其他方面
- 旧版浏览器可能不支持帧。
我们使用</NOFRAMES>...</NOFRAMES>
设计一个非常漂亮的网站并使用框架进行维护可能是一项非常具有挑战性的任务。
框架标签
- 示例1:将页面分为两列
<html><头><title>框架示例1</title><frameset cols="20%,80%"><frame src="left.html"><frame src="main.html"></frameset></head></html>
- 示例2:将页面分成两行
<html><头><title>框架示例2</title><frameset rows="20%,80%"><frame src="left.html"><frame src="main.html"></frameset></head></html>
- 示例3:将页面划分为行和列
<html><头><title>框架示例 3</title><frameset rows="20%,80%"><frame src="top.html"><frameset cols="20%,80%"><frame src="left.html"><frame src="main.html"></frameset></head></html>
框架集的属性
1.边界用于设置帧之间的边界。该值决定了以像素为单位的厚度。
<frameset cols=" ", border="2">。。</frameset>
2.边框颜色设置边框颜色。仅当设置了帧边框时,这才适用。例如bordercolor="blue"
3.框架边框决定是否显示边框。值为“1”或“是”和“0”或“否”。例如 frameborder="1"
4.帧间距用于在帧边缘及其内容之间放置位置。值必须以像素表示。例如framespacing="10"
5. col和行是框架集的属性
框架的属性
1. src是在框架中打开网页的位置
2.边框颜色定义边框的颜色
3.框架边框,设置为“1”或“是”以显示边框和边框颜色
4.边距宽度定义了帧左右两侧及其内容之间的像素空间量
5. marginheight定义了帧顶部和底部及其内容之间的像素空间量
6.名称为框架指定名称,并用于方便参考。它通常在框架中使用超链接时使用
7. noresize,您可以阻止用户调整您的网页大小。它不需要任何值
8.滚动它需要三个值(是,否,自动)
是的-如果您想允许滚动,并且即使滚动条通过滚动条也不需要不-这将防止任何滚动条,即使需要通过它auto - 让浏览器决定框架是否需要滚动条
名称属性
在使用超链接的同时在网页中创建帧时,您需要设置帧的名称。名称属性用于指定在哪个框架中打开网页。
<a href="http://www.google.com" target=" " >
名称应放在锚标签<a>的目标属性中......</a>
如果您想在单个帧中打开所有网页,您可以使用此标签<base target="" />
<html><头><base target=" " /></head></html>
Target用于指定帧的名称,但也可以使用标准值来代替帧的名称。
- _空白
此值创建一个新窗口来显示不包含任何帧的页面
- _父母
与第一个相似,但通常用于指定包含源名称的父帧
- _自己
将页面加载到同一帧中
- _顶部
这个表示一个新的文档窗口。它用于打破框架并在同一窗口中加载文档
- 框架名称
指定要加载页面的位置
- 资源窗口
在新窗口中打开文档
内联框架
内联帧是一个可以完全用作图像的浮动帧。它也像图像标签一样使用
<iframe></iframe>
内联框架的属性
1. src指定页面的位置
2.将内联框架与页面的其他元素对齐。值为左、右、上、下、中
3.高度和宽度指定iframe的尺寸(以像素为单位)
4. hspace和vspace指定iframes周围的水平和垂直空间量。值以像素为单位。
5. 页边距高度和页边宽度决定了帧左右边缘和顶部底部边缘及其内容之间的像素空间量
6.框架边框-值为1和0
7.滚动-值可以是或否
8. noresize - 防止用户调整帧大小
9. 名称 - 给框架取一个名字
练习
建议
阅读
理解
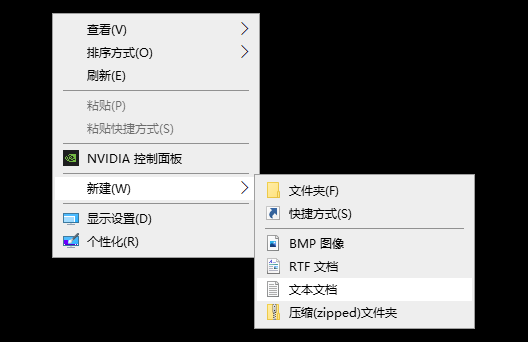
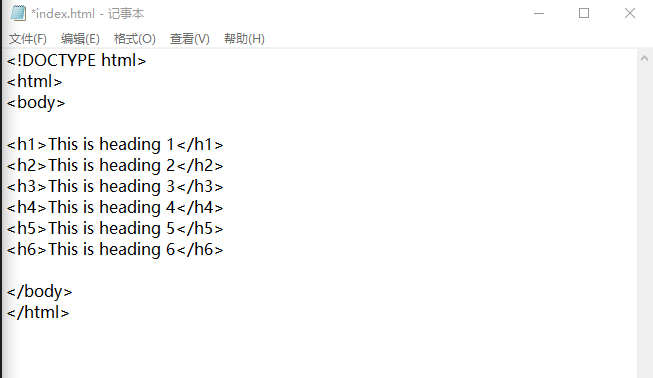
- 新建名称为 index的文本文档,并把 .txt改为 .html,保存;




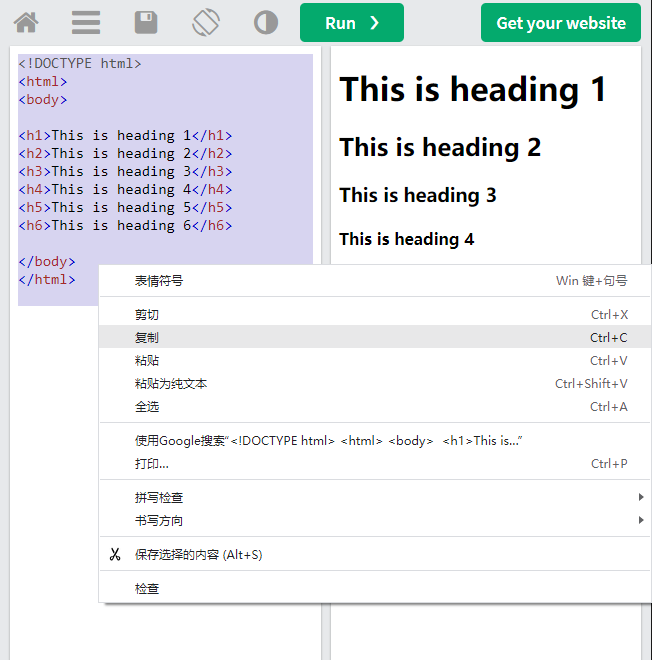
- 复制示例中的代码;

-
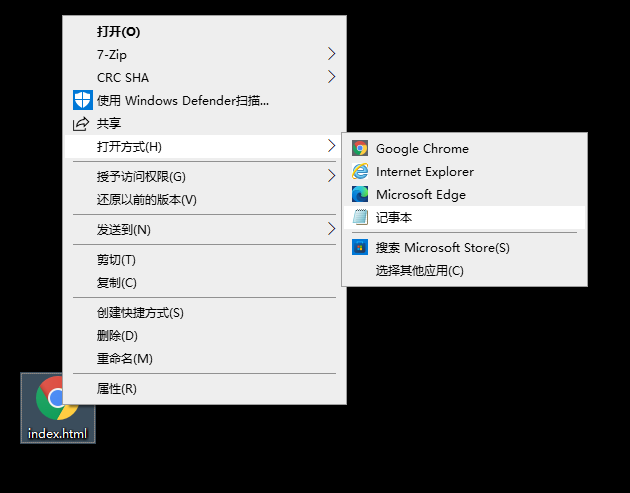
右击 index.html文件,选择打开方式为【记事本】后,单击打开;

- 粘贴第2步复制的代码;

- 修改代码功能中的内容,保存
- 点击保存的.html文件用浏览器查看效果
- 思考🤔修改后的.html文件效果是否达到第3步修改代码的目的
- 上一步若“是”,则对下一个新功能代码重复1-7步;若“否”,则回到第3步再思考及查阅相关资料,待理解后方可进入下一步