词汇
- 功能目录
- 硬件
- 字位、字节、字符
- 构建自动化 Build automation
- 计算机硬件
- 字符编码
- 非托管网络应用程序
- 电磁波、电磁波谱
- 单页应用程序
- 二进制(Base-2)系统
- 软件构建 Software build
- 操作系统
- Markdown
- 计算机网络
- NPM
- webpack
- Taro 安装及使用
- 开源软件的依赖性
- 从源头安装系统
- 在线语法转换
- 管理数字
- 备份
- 操作系统词典
- 存储系统——基本概念
- 数据存储
- 挂载
- 分区
- 增加 /home容量
- Node.js
- Apache HTTP Server
- Python
- PHP
- 设备
- RAID 技术
- 磁盘结构
- 网络术语、端口、协议
- 数据位
- 操作系统
- 哪些端口无法访问?
- 命名空间
- 基带和宽带之间的差异
- 吞吐量和带宽之间的差异
- CSMA/CD和CSMA/CA
- 信息定义
- 端口号常识
- 端口号规范
- 域名系统
- Domain Name
- IP Address
- InterNIC
- WHOIS
- Name Server
- ICANN
- Domain Suffix
- Web Host
- Backbone
- ISP
- Bandwidth
- Mbps
- External Hard Drive
- IEEE
- VLAN
- LAN
- Ad Hoc Network
- File Format
- Component
- Port
- ASCII
- ARP
- Gateway
- Default
- Router
- Access Point
- Switch
- Firewall
- WAN
- Storage Device
- RAM
- Protocol
- Font
- Utility
- Hardware
- Software
- Network
- Server
- Proxy Server
- Node
- IPv4
- IPv6
- MAC Address
- Packet
- AR
- Authentication
- Baseband
- Video Card
- Bézier Curve
- Binary
- Boot
- Boot Sector
- Boot Sequence
- VM
- Snapshot
功能目录
级别: 1

级别: 2
级别: 3
级别: 4
硬件
缩写为HW,最好将硬件描述为包含电路板、IC或其他电子设备的计算机系统的任何物理组件。硬件的一个完美示例是您正在查看此页面的屏幕。无论是显示器、平板电脑还是智能手机,它都是硬件。
没有任何硬件,您的计算机将不存在,软件也无法使用。图片是一个罗技 网络摄像头,一个外部硬件外围设备的例子。该硬件设备允许用户拍摄视频或图片,并通过 Internet 传输它们。
外部硬件示例
下面是在计算机之外找到的外部硬件或硬件的列表。
内部硬件示例
以下是计算机内部的内部硬件或硬件列表。
计算机中最常见的硬件是什么?
以下是当今计算机中常见的或连接到计算机(台式计算机或笔记本电脑)的最常见硬件的列表。
- 处理器 (CPU)
- 一个或多个风扇和散热器
- 最有可能集成了显卡、声卡和网卡的主板。
- 对于大多数台式计算机(尤其是游戏计算机),使用单独的视频卡。
- 内存
- 硬盘
- 电源
- 连接内部组件和外围设备的电缆。
- 键盘
- 带笔记本电脑的鼠标或触摸板。
- 平板电脑、显示器或电视,用于台式电脑和作为笔记本电脑一部分的液晶显示器。
字位、字节、字符
字位
计算机存储信息的最小单位,称之为位(bit),音译为比特,二进制的一个“0”或一个“1”叫一位。
字节
计算机存储容量基本单位是字节(Byte),音译为拜特,8个二进制位组成1个字节。一般而言:一个标准英文字母占一个字节位置,一个标准汉字占二个字节位置。
计算机存储容量大小以字节数来度量,1024进位制:
1024B=1K(千)B
1024KB=1M(兆)B
1024MB=1G(吉)B
1024GB=1T(太)B
以下还有PB、EB、ZB、YB 、NB、DB,一般人不常使用了。
字符
字符是一种符号,同以上说的存储单位不是一回事。1个字节等于8个bit位,每个bit位又0/1两种状态,也就是说一个字节可以表示256个状态,计算机里用字节来作为最基本的存储单位。一般来说,英文状态下一个字母或数字(称之为字符)占用一个字节,一个汉字用两个字节表示。在不同的编码方式下一个字符占的字节不太一样。按照ANSI编码标准,标点符号、数字、大小写字母都占一个字节,汉字占2个字节。按照UNICODE标准所有字符都占2个字节。
解释
“字节”的定义
字节(Byte)是一种计量单位,表示数据量多少,它是计算机信息技术用于计量存储容量的一种计量单位。
“字符”的定义
字符是指计算机中使用的文字和符号,比如1、2、3、A、B、C、~!·#¥%……—*()——+、等等。
“字节”与“字符”的区别
它们完全不是一个位面的概念,所以两者之间没有“区别”这个说法。不同编码里,字符和字节的对应关系不同:
①ASCII码中:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。
②UTF-8编码中:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
③Unicode编码中:一个英文字符等于两个字节,一个中文(含繁体)等于两个字节。符号:英文标点占一个字节;中文标点占两个字节。举例:英文句号“.”占1个字节的大小;中文句号“。”占2个字节的大小。
④UTF-16编码中:一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
⑤UTF-32编码中:世界上任何字符的存储都需要4个字节。
构建自动化 Build automation
组建自动化(英语:Build automation,又称构建自动化、自动化构建、构建系统)指自动创建软件组建的一组进程,包括将计算机源代码编译成二进制码、将二进制码包装成软件包以及运行自动化测试。
概要
组建自动化原先是通过创建makefile来完成的,如今则主要使用两大类工具完成组建:
- 组建自动化工具(如Make、Rake、Cake、MS build、Ant、Gradle、CMake等)
- 这些工具的主要目的是通过编译和链接源代码等活动来生成组建工件。
- 组建自动化服务器
- 这些基于Web的通用工具能够在预定或触发的基础上执行组建自动化实用程序。持续集成是组建自动化服务器的类型之一。
根据自动化程度的不同有如下分类:
组建自动化工具
组建自动化工具允许自动化简单且重复的任务,这些工具会通过以正确的、特定的顺序执行任务并运行每个任务来计算如何达到目标。其又可分为任务导向工具与产品导向工具:任务导向工具用以描述网络在特定集合任务方面的依赖性;产品导向工具则根据其生成的的产品来描述事物。
组建自动化服务器
虽然组建服务器早在持续集成服务器出现之前就已存在,但组建服务器(英语:build servers)通常与持续集成服务器(英语:continuous integration servers)在英语上是同义词。组建服务器也可以并入软件生命周期管理(ALM)工具以及应用发布自动化(ARA)工具中。
服务器类型
计算机硬件
电源
主板
处理器
内存
外存
控制器
网卡
声卡
显卡
光盘驱动器
软盘驱动器
调制解调器
显示器
打印机
扫描仪
字符编码
字符编码是将数字分配给图形字符的过程,特别是人类语言的书面字符,允许使用数字计算机存储、传输和转换它们。[1]构成字符编码的数字值称为“代码点”,统称为“代码空间”、“代码页面”或“字符映射”。

与光学或电报相关的早期字符代码只能代表书面语言中使用的字符子集,有时仅限于大写字母、数字和一些标点符号。现代计算机系统中数据数字表示成本低,允许更复杂的字符代码(如Unicode),这些代码代表了许多书面语言中使用的大多数字符。使用国际公认标准的字符编码允许在全球范围内以电子形式交换文本。
- 与字符编码相关的术语
.svg)
- 字符是具有语义值的最小文本单位。
- 字符集是多种语言可能使用的字符集合。示例:拉丁字符集被英语和大多数欧洲语言使用,尽管希腊字符集仅由希腊语使用。
- 编码字符集是每个字符对应一个唯一数字的字符集。
- 编码字符集的代码点是字符集或代码空间中允许的任何值。
- 代码空间是一系列整数,其值为代码点
- 代码单元是一个位序列,用于在给定编码表单中对剧目的每个字符进行编码。在某些文档中,这被称为代码值。
- 角色库(抽象字符集)
角色曲目是一套抽象的,包含100多万个字符,包括拉丁文、西里尔文、中文、韩文、日文、希伯来语和阿拉姆文等多种文字。
角色曲目中还包括音乐符号等其他符号。Unicode和GB18030标准都有字符库。当新字符添加到一个标准中时,另一个标准也会添加这些字符,以保持奇偶校验。
代码单元大小相当于特定编码的位测量:
代码单元的示例:考虑一串字母“abc”,后跟U+10400?DESERET大写字母LONG I(用1个char32_t、2个char16_t或4个char8_t表示)。该字符串包含:
- 四个字符;
- 四个代码点
- 要么:
- UTF-32中的四个代码单元(00000061,00000062,00000063,00010400)
- UTF-16(0061、0062、0063、d801、dc00)中的五个代码单元,或
- UTF-8中的七个代码单元(61、62、63、f0、90、90、80)。
在Unicode中引用字符的约定是以“U+”开头,然后以十六进制表示代码点值。Unicode标准的有效代码点范围为U+0000到U+10FFFF,包括,分为17个平面,由数字0到16标识。U+0000到U+FFFF范围内的字符在平面0中,称为基本多语言平面(BMP)。这个平面包含最常用的字符。其他平面上U+10000到U+10FFFF范围内的字符称为补充字符。
下表显示了代码点值的示例:
| 性格 | Unicode代码点 | 字形 |
|---|---|---|
| 拉丁语A | U+0041 | Α |
| 拉丁语锋利的S | U+00DF | ß |
| 汉朝东方 | U+6771 | 东方 |
| 安珀桑德 | U+0026 | & |
| 倒感叹号 | U+00A1 | ¡ |
| 部分标志 | U+00A7 | § |
代码点由一系列代码单元表示。映射由编码定义。因此,表示代码点所需的代码单元数量取决于编码:
- UTF-8:代码点映射到一个、两个、三个或四个代码单元的序列。
- UTF-16:代码单元的长度是8位代码单元的两倍。因此,任何标量值小于U+10000的代码点都使用单个代码单元进行编码。值为U+10000或以上的代码点每个需要两个代码单元。这些代码单元对在UTF-16中有一个唯一的术语:“Unicode代理对”。
- UTF-32:32位代码单元足够大,每个代码点都表示为单个代码单元。
- GB18030:由于代码单元较小,每个代码点的多个代码单元很常见。代码点映射到一个、两个或四个代码单元。
Unicode编码模型
Unicode及其并行标准ISO/IEC 10646通用字符集共同构成了一个现代、统一的字符编码。他们没有将字符直接映射到八位数(字节),而是分别定义了可用的字符、相应的自然数字(代码点)、这些数字如何编码为一系列固定大小的自然数字(代码单元),以及最后这些单元如何编码为八位数流。这种分解的目的是建立一套通用字符,该字符可以通过多种方式编码。[8] 要正确描述此模型,需要比“字符集”和“字符编码”更精确的术语。现代模型中使用的术语如下:[8]
字符库是系统支持的全套抽象字符。剧目可能会关闭,即如果不创建新标准(如ASCII和大多数ISO-8859系列),则不允许添加,也可能是开放的,允许添加(如Unicode和有限的Windows代码页面)。给定剧目中的字符反映了就如何将写作系统划分为基本信息单元所做的决定。拉丁字母、希腊字母和西里尔字母的基本变体可以分为字母、数字、标点符号和空格等几个特殊字符,这些字符都可以按简单的线性顺序排列,按读取顺序显示。但即使使用这些字母表,变音符也造成了复杂因素:它们可以被视为包含字母和变音符(称为预合成字符)的单个字符的一部分,也可以被视为单独的字符。前者允许更简单的文本处理系统,但后者允许在文本中使用任何字母/变音符组合。连字也带来了类似的问题。其他书写系统,如阿拉伯语和希伯来语,都以更复杂的字符库表示,因为需要容纳双向文本和字形等内容,这些文本和字形在不同情况下以不同方式连接在一起。
编码字符集(CCS)是一个将字符映射到代码点的函数(每个代码点代表一个字符)。例如,在给定的曲目中,拉丁字母中的大写字母“A”可以用代码点65、字符“B”到66等表示。多个编码字符集可能共享相同的曲目;例如ISO/IEC 8859-1和IBM代码页面037和500都涵盖了相同的曲目,但将它们映射到不同的代码点。
字符编码形式(CEF)是将代码点映射到代码单元,以方便在将数字表示为固定长度位序列的系统中(即几乎任何计算机系统)中的存储。例如,一个以16位单位存储数字信息的系统只能直接表示每个单元中的代码点0到65,535,但较大的代码点(例如65,536到140万)可以通过使用多个16位单元来表示。此通信由CEF定义。
接下来,字符编码方案(CES)是将代码单元映射到八位数序列,以方便在基于八位数的文件系统上存储或通过基于八位数的网络传输。简单的字符编码方案包括UTF-8、UTF-16BE、UTF-32BE、UTF-16LE或UTF-32LE;复合字符编码方案,如UTF-16、UTF-32和ISO/IEC 2022,通过使用字节顺序标记或转义序列在几个简单的方案之间切换;压缩方案试图将每个代码单元(如SCSU、BOCU和Punycode)使用的字节数最小化。
虽然UTF-32BE是一个更简单的CES,但大多数使用Unicode的系统要么使用UTF-8,它向后兼容固定宽度的ASCII,并将Unicode代码点映射到八位数的变宽度序列,要么使用UTF-16BE,后者向后兼容固定宽度的UCS-2BE,并将Unicode代码点映射到16位单词的可变宽度序列。有关详细讨论,请参阅Unicode编码的比较。
最后,可能有一个更高级别的协议,为选择Unicode字符的特定变体提供更多信息,特别是在Unicode中有一些区域变体与同一字符“统一”的情况下。一个例子是XML属性xml:lang。
Unicode模型使用术语字符映射来描述历史系统,这些系统直接将字符序列分配给字节序列,涵盖所有CCS、CEF和CES层。
字符集、字符映射和代码页面
从历史上看,“字符编码”、“字符映射”、“字符集”和“代码页面”等术语在计算机科学中是同义词,因为同一标准将指定字符库以及如何将字符编码成代码单元流——通常每个代码单元只有一个字符。但现在这些术语具有相关但不同的含义,[9] 由于标准机构在编写和统一许多不同的编码系统时努力使用准确的术语。[8]无论如何,这些术语仍然可以互换使用,字符集几乎无处不在。
“代码页面”通常是指面向字节的编码,但对于某些编码集(涵盖不同的脚本),其中许多字符在大多数或所有代码页面中共享相同的代码。著名的代码页面套件是“Windows”(基于Windows-1252)和“IBM”/“DOS”(基于代码页面437),有关详细信息,请参阅Windows代码页面。大多数(但不是所有)被称为代码页面的编码都是单字节编码(但请参阅字节大小的八位数)。
IBM的字符数据表示架构(CDRA)指定具有编码字符集标识符(CCSID)的实体,每个标识符都不同地称为“字符集”、“字符集”、“代码页面”或“CHARMAP”。[8]
“代码页面”一词不出现在首选“charmap”的Unix或Linux中,通常在更大的区域设置上下文中。
与“编码字符集”不同,“字符编码”是从抽象字符到编码单词的映射。HTTP(和MIME)语中的“字符集”与字符编码相同(但与CCS不同)。
“传统编码”是一个术语,有时用于描述旧字符编码,但含义模糊。它的大部分使用是在Unicodification的背景下,它指的是未能涵盖所有Unicode代码点的编码,或者更笼统地说,使用有点不同的字符库:代表一个Unicode字符的几个代码点,[10]或反之亦然(例如,见代码第437页)。一些来源仅将编码称为遗留,因为它先于Unicode。[11]所有Windows代码页面通常都被称为遗留页面,因为它们比Unicode更年,也因为它们无法代表所有221个可能的Unicode代码点。
字符编码翻译
由于使用了多种字符编码方法(以及需要向后兼容存档数据),开发了许多计算机程序,在编码方案之间将数据转换为数据传输形式。下文引用其中一些。
跨平台:
- 网络浏览器——大多数现代网络浏览器都具有自动字符编码检测功能。例如,在Firefox 3上,请参阅视图/字符编码子菜单。
- iconv – 转换编码的程序和标准化API
- luit – 将输入和输出编码转换为交互式运行的程序的程序
- convert_encoding.py – 基于Python的实用程序,用于在任意编码和行尾之间转换文本文件。[12]
- decodeh.py – 启发式猜测字符串编码的算法和模块。[13]
- Unicode的国际组件-一组用于执行字符集转换的C和Java库。uconv可以从ICU4C使用。
- chardet – 这是Mozilla自动编码检测代码翻译成Python计算机语言。
- 较新版本的Unix文件命令试图对字符编码进行基本检测(也可以在Cygwin上使用)。
- charset – C++模板库,具有简单的界面,可在C++/用户定义的流之间转换。charset定义了许多字符集,并允许您使用Unicode格式来支持外部性。
非托管网络应用程序
定义
非托管网络应用程序也称为“无服务器”、“客户端”或“静态”网络应用程序,不会将您的用户数据发送到他们的服务器。要么您在运行时连接自己的服务器,要么您的数据保留在浏览器中。
与原生(iOS、Android)应用程序相比的优势
- 网络应用程序适用于任何设备,无论哪个平台或提供商
- 您可以从任何网站获取应用程序,而不仅仅是通过审查的应用程序商店
与托管网络应用程序相比的优势
- 独立于您使用哪些应用程序选择您的服务器提供商
- 同样,您的存储提供商不会缩小您对应用程序的选择范围
- 默认情况下,应用程序提供商不再查看您的数据
- 非托管网络应用程序发布成本低于托管网络应用程序
- 未托管的网络应用程序可以轻松镜像,以获得终止开关的弹性
- 每个应用程序的无限后端可伸缩性(根本没有每个应用程序后端)
什么?没有后端?所以整个应用程序实际上是客户端的?
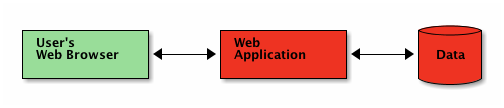
您的日常LAMP-stack、J2SE、.net或Ruby-on-Rails托管的Web应用程序
是的。通过http,您会收到应用程序的源代码,而不是不透明的用户界面。花一分钟来绕过这个......
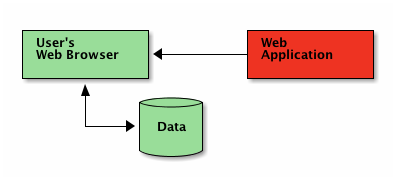
新的“无主机网络应用程序”架构
...然后继续阅读,了解工具,或构建您的第一个应用程序!
电磁波、电磁波谱
无线通讯技术的基础
电磁波/电磁波谱
无线电波的信道
无线电的属性 频率 波长 振幅
波长和频率详解
关于波长和频率的几个基础知识
模拟信号的优缺点 频率的调制AM和FM
数字信号的优缺点 三种调制方式ASK FSK PSK
振幅
振幅,指波的波动幅度,能量越大,振幅越高,表现出来的信号强度📶也就越高。
波长
波长,指波在一个振动周期传播的距离。
频率
频率,指波的周期。
-
1 秒钟通过 1 个完整的波长就等于 1Hz
-
1 秒钟通过1000个波长等于 1000Hz= 1KHz,1MHz等于 1000 000Hz(一百万赫兹),1GHz等于 1000 000 000Hz(十亿赫兹)
速度
电磁波在真空中以光速传播,在空气中的传播速度接近光速。
单页应用程序
单页应用程序
历史编辑
技术方法编辑
可以使用各种技术使浏览器即使在应用程序需要服务器通信时也能保留单个页面。
文档散列编辑
HTML作者可以利用元素ID来显示或隐藏HTML文档的不同部分。然后,使用CSS,作者可以使用“#target”选择器仅显示浏览器导航到的页面部分。
JavaScript框架编辑
Web浏览器JavaScript框架和库,如AngularJS、Ember.js、ExtJS、Knockout.js、Meteor.js、React、Vue.js和Svelte,都采用了SPA原则。除了ExtJS,所有这些都是免费的。
- AngularJS是一个完全客户端的框架。AngularJS的模板基于双向UI数据绑定。数据绑定是一种自动更新模型更改视图的方法,以及每当视图更改时更新模型的方法。HTML模板在浏览器中编译。编译步骤创建纯HTML,浏览器将其重新呈现到实时视图中。对于后续页面浏览,将重复此步骤。在传统的服务器端HTML编程中,控制器和模型等概念在服务器进程中交互,以生成新的HTML视图。在AngularJS框架中,控制器和模型状态在客户端浏览器中保持。因此,无需与服务器进行任何交互即可生成新页面。
- Ember.js是基于模型-视图控制器(MVC)软件架构模式的客户端JavaScript Web应用程序框架。它允许开发人员通过将常见习语和最佳做法集成到一个框架中来创建可扩展的单页应用程序,该框架提供丰富的对象模型、声明性双向数据绑定、计算属性、由Handlebars.js支持的自动更新模板以及用于管理应用程序状态的路由器。
- ExtJS也是一个客户端框架,允许创建MVC应用程序。它有自己的事件系统、窗口和布局管理、状态管理(商店)和各种UI组件(网格、对话框窗口、表单元素等)。它有自己的类系统,有动态或静态加载程序。使用ExtJS构建的应用程序可以单独存在(在浏览器中具有状态),也可以与服务器(例如,使用用于填充内部存储的REST API)一起存在。ExtJS仅内置使用localStorage的功能,因此大型应用程序需要服务器来存储状态。
- Knockout.js是一个客户端框架,使用基于Model-View-ViewModel模式的模板。
- Meteor.js是一个专为SPA设计的全栈(客户端服务器)JavaScript框架。它具有比Angular、Ember或ReactJS[5]更简单的数据绑定,[5]并使用分布式数据协议[6]和发布订阅模式自动向客户端传播数据更改,而无需开发人员编写任何同步代码。全堆栈反应性确保从数据库到模板的所有层在必要时自动更新自己。服务器端渲染[7]等生态系统软件包解决了搜索引擎优化的问题。
- React是一个用于构建用户界面的JavaScript库。它由Facebook、Instagram以及个人开发人员和公司社区维护。React使用一种新语言,即JS和HTML(HTML的一个子集)的混合。几家公司使用React with Redux(JavaScript库),这增加了状态管理功能,(与其他几个库一起)允许开发人员创建复杂的应用程序。[8]
- Vue.js是一个用于构建用户界面的JavaScript框架。Vue开发人员还为状态管理提供Vuex。
- Svelte是一个用于构建用户界面的框架,该框架将Svelte代码编译为JavaScript DOM操作,无需将框架捆绑到客户端,并允许更简单的应用程序开发语法。
阿贾克斯编辑
截至2006年,使用的最突出的技术是Ajax。[1] Ajax涉及对服务器的XML或JSON数据使用异步请求,例如JavaScript的XMLHttpRequest或更现代的获取(自2017年以来),或不建议使用的ActiveX对象。与大多数SPA框架的声明性方法相反,使用Ajax,网站直接使用JavaScript或JavaScript库(如jQuery)来操作DOM和编辑HTML元素。Ajax进一步被jQuery等库推广,jQuery提供了更简单的语法,并使历史上行为不同的浏览器之间的Ajax行为正常化。
WebSockets编辑
WebSockets是一种双向实时客户端-服务器通信技术,是HTML5规范的一部分。对于实时通信,它们的使用在性能[9]和简单性方面优于Ajax。
服务器发送的事件编辑
服务器发送事件(SSE)是一种服务器可以启动数据传输到浏览器客户端的技术。建立初始连接后,事件流将保持打开状态,直到客户端关闭。SSE通过传统HTTP发送,具有WebSockets在设计上缺乏的各种功能,如自动重新连接、事件ID和发送任意事件的能力。[10]
浏览器插件编辑
虽然此方法已过时,但也可以使用Silverlight、Flash或Java小程序等浏览器插件技术实现对服务器的异步调用。
数据传输(XML、JSON和Ajax)编辑
对服务器的请求通常会导致原始数据(例如XML或JSON)或返回新的HTML。在服务器返回HTML的情况下,客户端上的JavaScript会更新DOM(文档对象模型)的部分区域。返回原始数据时,通常使用客户端JavaScript XML / (XSL)进程(在JSON的情况下,使用模板)将原始数据转换为HTML,然后用于更新DOM的部分区域。
服务器架构编辑
薄服务器架构编辑
SPA将逻辑从服务器移动到客户端,Web服务器的角色演变为纯数据API或Web服务。在某些圈子里,这种架构转换被创造为“薄服务器架构”,以强调复杂性已从服务器转移到客户端,并认为这最终降低了系统的整体复杂性。
厚厚的有状态服务器架构编辑
服务器在页面的客户端状态的内存中保持必要的状态。这样,当任何请求击中服务器(通常是用户操作)时,服务器会发送适当的HTML和/或JavaScript,并进行具体更改,以使客户端达到新的所需状态(通常添加/删除/更新客户端DOM的一部分)。同时,服务器中的状态会更新。大多数逻辑都在服务器上执行,HTML通常也在服务器上呈现。在某些方面,服务器模拟网页浏览器,接收事件,并在服务器状态中执行增量更改,这些更改会自动传播到客户端。
这种方法需要更多的服务器内存和服务器处理,但优势是简化了开发模型,因为a)应用程序通常在服务器中完全编码,b)服务器中的数据和UI状态共享在同一内存空间中,不需要自定义客户端/服务器通信桥接器。
厚厚的无状态服务器架构编辑
这是有状态服务器方法的变体。客户端页面通常通过Ajax请求向服务器发送代表其当前状态的数据。使用此数据,服务器能够重建页面中需要修改的部分的客户端状态,并可以生成必要的数据或代码(例如JSON或JavaScript),这些数据或代码将返回给客户端以使其进入新状态,通常根据激发请求的客户端操作修改页面DOM树。
这种方法要求向服务器发送更多数据,并且每个请求可能需要更多的计算资源来部分或完全重建服务器中的客户端页面状态。与此同时,这种方法更容易扩展,因为服务器中没有保存每个客户端的页面数据,因此,Ajax请求可以发送到不同的服务器节点,而无需会话数据共享或服务器亲和力。
在本地运行编辑
SPA模型的挑战编辑
由于SPA是从浏览器最初设计的无状态页面重绘模型的演变而来,因此出现了一些新的挑战。可能的解决方案(复杂度、全面性和作者控制程度各不相同)包括:[12]
搜索引擎优化编辑
由于一些流行的网络搜索引擎的爬虫上缺乏JavaScript执行,[17] SEO(搜索引擎优化)历来给希望采用SPA模型的面向公众的网站带来了问题。[18]
2009年至2015年,Google Webmaster Central提出并随后推荐了“AJAX爬行方案”[19][20],在有状态AJAX页面的片段标识符中使用初始感叹号(#!)。SPA网站必须实现特殊行为,以便搜索引擎的爬虫提取相关元数据。对于不支持此URL散列方案的搜索引擎,SPA的散列URL仍然不可见。这些“hash-bang”URI被包括W3C的Jeni Tennison在内的一些作家认为是有问题的,因为它们使那些没有在浏览器中激活JavaScript的人无法访问页面。他们还破坏了HTTP引用头,因为浏览器不允许在引用头中发送片段标识符。[21] 2015年,谷歌不建议使用他们的散列式AJAX爬行提案。[22]
或者,应用程序可以在服务器上呈现第一页加载,并在客户端上呈现后续页面更新。这在传统上很困难,因为渲染代码可能需要在服务器和客户端上使用不同的语言或框架编写。使用无逻辑模板、从一种语言交叉编译到另一种语言,或在服务器和客户端上使用同一语言可能有助于增加可以共享的代码量。
2018年,谷歌引入了动态渲染,作为希望为爬虫提供非JavaScript重版页面用于索引目的的网站的另一种选择。[23]动态渲染在客户端渲染页面的版本和特定用户代理的预渲染版本之间切换。这种方法涉及您的Web服务器检测爬虫(通过用户代理)并将其路由到渲染器,然后从渲染器中为它们提供更简单的HTML内容版本。
由于搜索引擎优化兼容性在SPA中并不微不足道,值得注意的是,SPA通常不用于搜索引擎索引是要求或可取的上下文。用例包括显示隐藏在身份验证系统后面的私有数据的应用程序。在这些应用程序是消费品的情况下,应用程序登录页面和营销网站通常使用经典的“页面重绘”模型,该模型为应用程序提供了足够的元数据,使应用程序在搜索引擎查询中显示为热门。博客、支持论坛和其他传统的页面重绘工件通常位于SPA周围,SPA可以使用相关术语为搜索引擎播种。
截至2021年,特别是谷歌,普通SPA的SEO兼容性很简单,只需要满足几个简单的条件。[24] 还提供了使用选择性预渲染的更高级SPA的实用指南。[25]
基于Java的ItsNat等以服务器为中心的Web框架使用的另一种方法是使用相同的语言和模板技术渲染服务器上的任何超文本。在这种方法中,服务器准确地知道客户端上的DOM状态,所需的任何大页面或小页面更新都会在服务器中生成,并由Ajax传输,Ajax是将客户端页面带到执行DOM方法的新状态的确切JavaScript代码。开发人员可以决定哪些页面状态必须由Web蜘蛛为SEO抓取,并能够在加载时生成所需的状态,生成纯HTML而不是JavaScript。就ItNat框架而言,这是自动的,因为ItsNat将客户端DOM树保留在服务器中作为Java W3C DOM树;在服务器中渲染此DOM树会在加载时生成普通HTML和Ajax请求的JavaScript DOM操作。这种二元性对搜索引擎优化非常重要,因为开发人员可以使用相同的Java代码和纯粹基于HTML在服务器中模板化所需的DOM状态;在页面加载时,传统的HTML由ItNat生成,使这种DOM状态与SEO兼容。
从1.3版本开始,[26]其Nat提供了新的无状态模式,客户端DOM不会保留在服务器上,因为使用无状态模式客户端,在根据客户端发送的所需数据在服务器上处理任何Ajax请求时,DOM状态会在服务器上部分或完全重建;无状态模式也可能与SEO兼容,因为SEO兼容性发生在初始页面的加载时,不受状态或无状态模式的影响。另一个可能的选择是PreRender、Pupeteer、Rendertron等框架,这些框架可以很容易地作为具有Web服务器配置的中间件集成到任何网站中,使中间件能够满足机器人请求(谷歌机器人和其他),而非机器人请求则像往常一样提供服务。这些框架定期缓存相关网站页面,以便搜索引擎可以使用最新版本。这些框架已获得谷歌的正式批准。[27]
有几个变通方法可以让它看起来像是可爬行的。两者都涉及创建单独的HTML页面,以镜像SPA的内容。服务器可以创建基于HTML的网站版本并将其交付给爬虫,或者可以使用PhantomJS等无头浏览器运行JavaScript应用程序并输出生成的HTML。
两者确实需要付出相当大的努力,最终可能会给大型复杂站点带来维护问题。还有潜在的搜索引擎优化陷阱。如果服务器生成的HTML被认为与SPA内容太不同,那么该网站将受到处罚。运行PhantomJS输出HTML可以减缓页面的响应速度,为此,搜索引擎——特别是谷歌——降级了增加服务器和客户端之间可以共享的代码量的一种方法是使用无逻辑模板语言,如胡子或手柄。此类模板可以从不同的主机语言呈现,例如服务器上的Ruby和客户端中的JavaScript。然而,仅共享模板通常需要复制用于选择正确模板并用数据填充它们的业务逻辑。当仅更新页面的一小部分时,例如大型模板中的文本输入值,从模板渲染可能会产生负面的性能影响。更换整个模板也可能扰乱用户的选择或光标位置,仅更新更改的值可能不会。为了避免这些问题,应用程序可以使用UI数据绑定或粒度DOM操作来仅更新页面的适当部分,而不是重新呈现整个模板。排名。[28]
客户端/服务器代码分区编辑
浏览器历史记录编辑
根据定义,SPA是“单个页面”,该模型使用“前进”或“返回”按钮打破了浏览器的页面历史记录导航设计。当用户按下后退按钮时,这会遇到可用性障碍,希望在SPA中出现上一个屏幕状态,但相反,应用程序的单页卸载,浏览器历史记录中的上一页会出现。
SPA的传统解决方案是根据当前屏幕状态更改浏览器URL的散列片段标识符。这可以通过JavaScript实现,并导致在浏览器中构建URL历史记录事件。只要SPA能够从URL散列中包含的信息中恢复相同的屏幕状态,预期的后退按钮行为就会保留。
为了进一步解决这个问题,HTML5规范引入了 pushState,并替换了State,提供了对实际URL和浏览器历史记录的编程访问。
分析编辑
Google Analytics等分析工具严重依赖浏览器中由新页面加载启动的整个新页面加载。SPA不是这样工作的。
第一页加载后,所有后续的页面和内容更改都由应用程序内部处理,应用程序只需调用一个函数来更新分析包。如果无法调用上述功能,浏览器永远不会触发新的页面加载,浏览器历史记录中不会添加任何东西,分析包也不知道谁在网站上做什么。
安全扫描编辑
与搜索引擎爬虫遇到的问题类似,DAST工具可能会在这些富含JavaScript的应用程序中遇到困难。问题可能包括缺乏超文本链接、内存使用情况以及SPA加载的资源通常由应用程序编程接口或API提供。单页应用程序仍然面临与跨站点脚本(XSS)等传统网页相同的安全风险,但也面临许多其他独特的漏洞,如通过API的数据暴露和客户端逻辑以及服务器端安全性的客户端执行。[29]为了有效地扫描单页应用程序,DAST扫描仪必须能够以可靠和可重复的方式浏览客户端应用程序,以便发现应用程序的所有区域并拦截应用程序发送到远程服务器的所有请求(例如API请求)。能够采取此类行动的商业工具很少,但此类工具肯定存在。[需要引用]
向SPA添加页面加载编辑
可以使用HTML5历史记录API将页面加载事件添加到SPA中;这将有助于集成分析。困难在于管理这一点,并确保准确跟踪所有内容——这涉及检查丢失的报告和重复条目。一些框架针对大多数主要分析提供商提供免费的分析集成。开发人员可以将它们集成到应用程序中,并确保一切正常,但没有必要从头开始做任何事情。[28]
加快页面加载速度编辑
有一些方法可以加快SPA的初始加载速度,例如选择性地预渲染SPA登录/索引页面、缓存和各种代码拆分技术,包括需要时的惰性加载模块。但不可能摆脱这样一个事实,即它需要下载框架,至少下载一些应用程序代码;如果页面是动态的,它将点击API获取数据。[28]这是一个“现在付钱给我,要么稍后付钱”的权衡方案。性能和等待时间问题仍然是开发人员必须做出的决定。
页面生命周期编辑
二进制(Base-2)系统
二进制数仅由0和1组成,如下所示:1011。如何计算该值二进制数1011是?您的操作方式与十进制系统篇中6357相同,但是您使用2的底数而不是10的底数。因此:
(1 * 2 ^ 3)+(0 * 2 ^ 2)+(1 * 2 ^ 1)+(1 * 2 ^ 0)= 8 + 0 + 2 + 1 = 11
您会看到,二进制数的每一位都具有2的幂的递增值。这使得对二进制进行计数非常容易。从零开始,一直到20,以十进制和二进制形式计数如下:
0 = 0
1 = 1
2 = 10
3 = 11
4 = 100
5 = 101
6 = 110
7 = 111
8 = 1000
9 = 1001
10 = 1010
11 = 1011
12 = 1100
13 = 1101
14 = 1110
15 = 1111
16 = 10000
17 = 10001
18 = 10010
19 = 10011
20 = 10100
当您查看此序列时,十进制和二进制数字系统的0和1相同。在数字2处,您首先看到了二进制系统中的进位。如果某个位为1,然后将其加1,则该位将变为0,下一个位将变为1。在从15到16的过渡中,此效果将滚动4位,将1111变为10000。
在计算机中很少看到比特。它们几乎总是捆绑在一起成为8位集合,这些集合称为bytes。为什么一个字节中有8位?一个类似的问题是:“为什么一打中有十二个鸡蛋?” 在过去的50年中,人们通过反复试验确定了8位字节。
字节中有8位,您可以表示256个值,范围从0到255,如下所示:
0 = 00000000
1 = 00000001
2 = 00000010
...
254 = 11111110
255 = 11111111
提示(2 ^ 16=256)
在文章CD的工作原理中,您了解到CD每个样本使用2个字节或16位。这样每个样本的范围为0到65,535,如下所示:
0 = 0000000000000000
1 = 0000000000000001
2 = 0000000000000010
...
65534 = 1111111111111110
65535 = 1111111111111111
提示(2 ^ 256=65536)
综上所述,这是我们所了解的位和字节:
位是二进制数字。一位可以保留值0或1。
字节每个由8位组成。
二进制数学就像十进制数学一样工作,但是每个位的值只能是0或1。
真的没有更多了-位和字节就是这么简单。
软件构建 Software build
意指由源代码文件转换成可以在电脑上执行的软件这中间的过程,或是转换后的结果。软件组建中最重要的一个步骤,就是由源代码转换为可执行机器代码这之间的编译过程。为了进行版本控制,在执行完软件组建,之后发布的软件程序,通常会给与一个软件版本号。
操作系统
OS
操作系统(也称为“OS”)是最重要的软件程序集,最初通过引导程序加载到任何类似计算机的设备中。操作系统控制计算机中的几乎所有资源,包括网络、数据存储、用户和用户密码数据库、外围设备等。操作系统产品是非常复杂的软件产品。操作系统软件产品由数百万行源代码编译而成。
类型
客户端
您可以将客户端视为网络中的计算机,网络用户正在执行一些网络活动。例如:从文件服务器下载文件、浏览内联网/互联网等。网络用户通常使用客户端计算机进行日常工作。
- Windows XP / 7 / 10
- macOS 10.15 / macOS 11 / macOS 12
- iOS 15
- Android 12
服务器
客户端计算机与服务器计算机建立连接,并访问服务器计算机上安装的服务。服务器计算机不适用于网络用户浏览互联网或进行电子表格数据输入工作。服务器计算机安装了适当的操作系统和相关软件,以全天候连续为网络客户端提供一项或多项服务。
- Windows Server
- macOS Server
- Unix:Oracle Solaris、IBM AIX、HP UX、FreeBSD、NetBSD、OpenBSD、Xinous Open Server/SCO Unix
- GNU/Linux:RedHat Enterprise Linux、Debian Linux、SUSE Linux Enterprise Server、Ubuntu Server、CentOS Server、Fedora Server
服务器类型
文件服务器:文件服务器用于集中存储用户文档和文件。理想的文件服务器应该有大量的内存和存储空间、快速硬盘、多个处理器、快速网络适配器、冗余电源等。文件服务器在Windows、Linux或Unix网络中运行FTP(文件传输协议),或在Windows网络中运行SMBP(服务器消息块协议)。著名的FTP软件产品是Micrsoft IIS、FileZilla Server、vsftpd、Apache FTP Server等。将网络用户文件和电子文档集中保存在文件服务器中的主要优势是网络用户文件和文档可以轻松管理(备份)。考虑管理由数千台计算机组成的网络中存储在用户工作站内的网络用户文件和电子文档!几乎不可能。
打印服务器:打印服务器,它将打印作业从客户端计算机重定向到特定打印机。
邮件服务器:邮件服务器用于使用电子邮件协议传输电子邮件。最广泛使用的电子邮件传输协议是SMTP(简单的邮件传输协议)。“邮件服务器”在不同域之间交换电子邮件。最广泛使用的邮件服务器软件产品是Microsoft Exchange Server、SENDMAIL(现为校对点)、Postfix、Apache James等。
应用程序服务器:不同网络用户所需的常见计算机应用程序或程序可以在中央服务器中运行,使多个网络用户能够从网络访问常见网络应用程序。通常,应用程序服务器运行业务逻辑。意味着,每个业务都不同,应用程序服务器是控制业务流程的服务器软件。应用程序服务器软件的一些示例包括SAP ERP、Microsoft Dynamics、Oracle ERP Cloud、Ramco ERP、infor ERP等。
数据库服务器:数据库服务器允许授权网络客户端创建、查看、修改和/或删除存储在公共数据库中的组织数据。数据库管理系统的例子包括甲骨文数据库产品、Microsoft SQL Server 2019、PostgreSQL、IBM DB2数据库服务器、MySQL数据库服务器、Informix、MongoDB、MariaDB服务器等。
目录服务器:目录服务器允许对网络用户和网络资源进行集中管理。目录服务器提供网络安全、身份验证、授权和会计的基本功能。目录服务器的例子包括Microsoft Active Directory、NetIQ eDirectory、Fedora Directory Server、OpenLDAP等。
Markdown
Markdown 是什么?
Markdown是一种轻量级的标记语言,可用于向纯文本文档添加格式元素。Markdown由John Gruber于2004年创建,现在是世界上最受欢迎的标记语言之一。
使用Markdown与使用WYSIWYG编辑器不同。在Microsoft Word等应用程序中,您可以单击按钮格式化单词和短语,更改将立即可见。减价不是那样的。创建Markdown格式的文件时,您将Markdown语法添加到文本中,以指示哪些单词和短语应该看起来不同。
例如,要表示标题,请在标题之前添加数字符号(例如# Heading One)。或者要将短语加粗,请在短语前后添加两个星号(例如**this text is bold**)。可能需要一段时间才能习惯在文本中看到Markdown语法,特别是如果您习惯了WYSIWYG应用程序。下面的屏幕截图显示了Visual Studio Code文本编辑器中显示的Markdown文件。
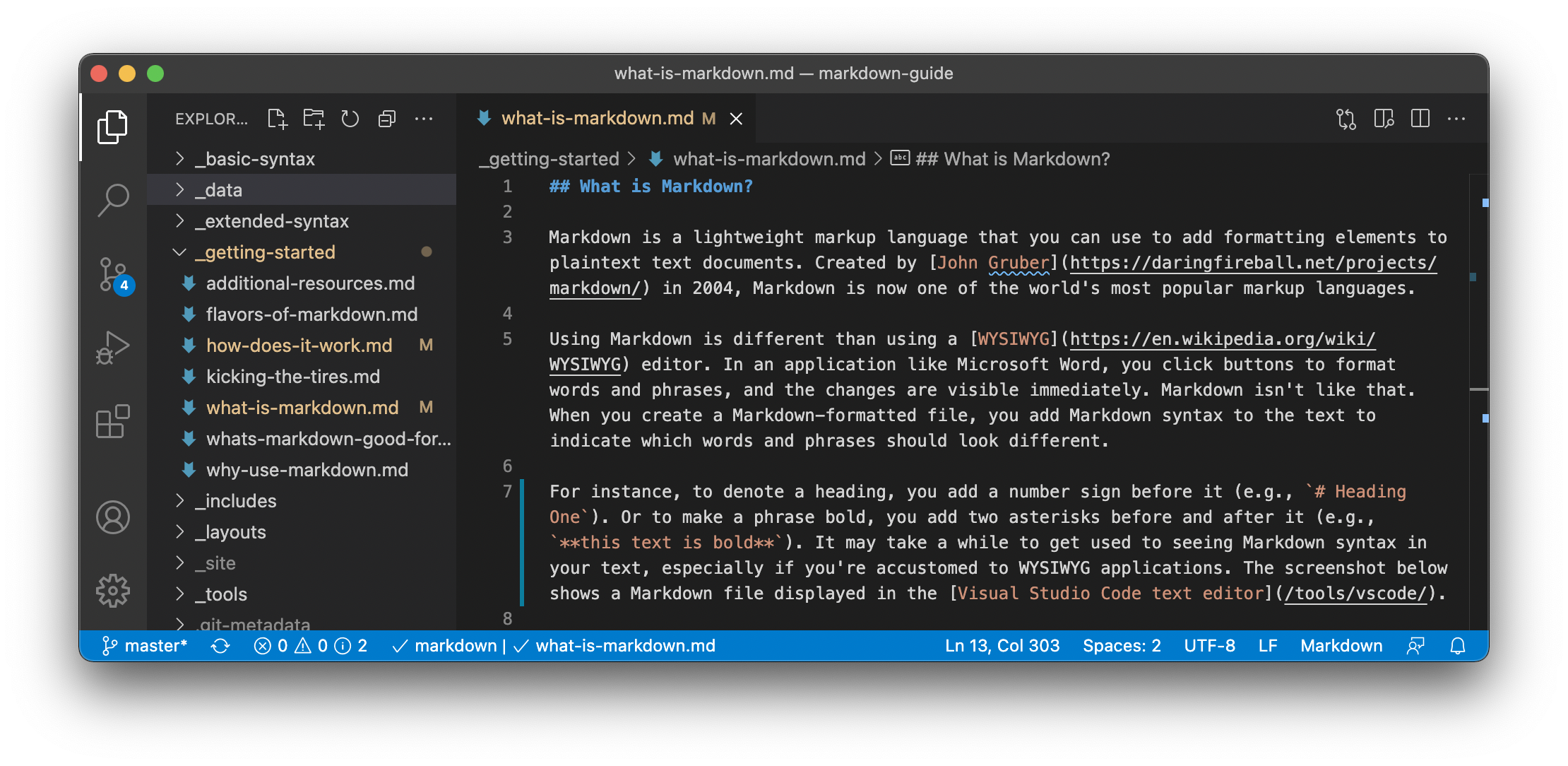
您可以使用文本编辑器应用程序将Markdown格式元素添加到纯文本文件中。或者,您可以使用适用于macOS、Windows、Linux、iOS和Android操作系统的众多Markdown应用程序之一。还有几个基于网络的应用程序专门为在Markdown中编写而设计。
根据您使用的应用程序,您可能无法实时预览格式化的文档。但没关系。根据Gruber的说法,Markdown语法被设计为可读和不引人注目,因此即使没有呈现Markdown文件中的文本也可以读取。
Markdown格式语法的首要设计目标是使其尽可能可读。其想法是,Markdown格式的文档应该可以按原样发布,作为纯文本发布,而不看起来像是带有标签或格式说明标记的。
为什么使用Markdown?
您可能想知道为什么人们使用Markdown而不是WYSIWYG编辑器。当你可以按下界面中的按钮来格式化文本时,为什么要使用Markdown写作?事实证明,人们使用Markdown而不是WYSIWYG编辑器有几个不同的原因。
-
Markdown是便携式的。包含Markdown格式文本的文件几乎可以使用任何应用程序打开。如果您决定不喜欢当前使用的Markdown应用程序,您可以将Markdown文件导入另一个Markdown应用程序。这与Microsoft Word等将内容锁定为专有文件格式的文字处理应用程序形成了鲜明对比。
-
Markdown独立于平台。您可以在运行任何操作系统的任何设备上创建Markdown格式的文本。
-
减价是未来的证明。即使您正在使用的应用程序在未来某个时候停止工作,您仍然可以使用文本编辑应用程序读取Markdown格式的文本。当涉及到需要无限期保存的书籍、大学论文和其他里程碑文件时,这是一个重要的考虑因素。
-
减价无处不在。Reddit和GitHub等网站支持Markdown,许多基于桌面和网络的应用程序支持Markdown。
踢轮胎
开始使用Markdown的最佳方法是使用它。多亏了各种免费工具,这比以往任何时候都更容易。
你甚至不需要下载任何东西。有几个在线Markdown编辑器可用于尝试在Markdown中编写。Dillinger是最好的在线Markdown编辑之一。只需打开网站,然后在左侧窗格中开始键入。渲染文档的预览显示在右侧窗格中。
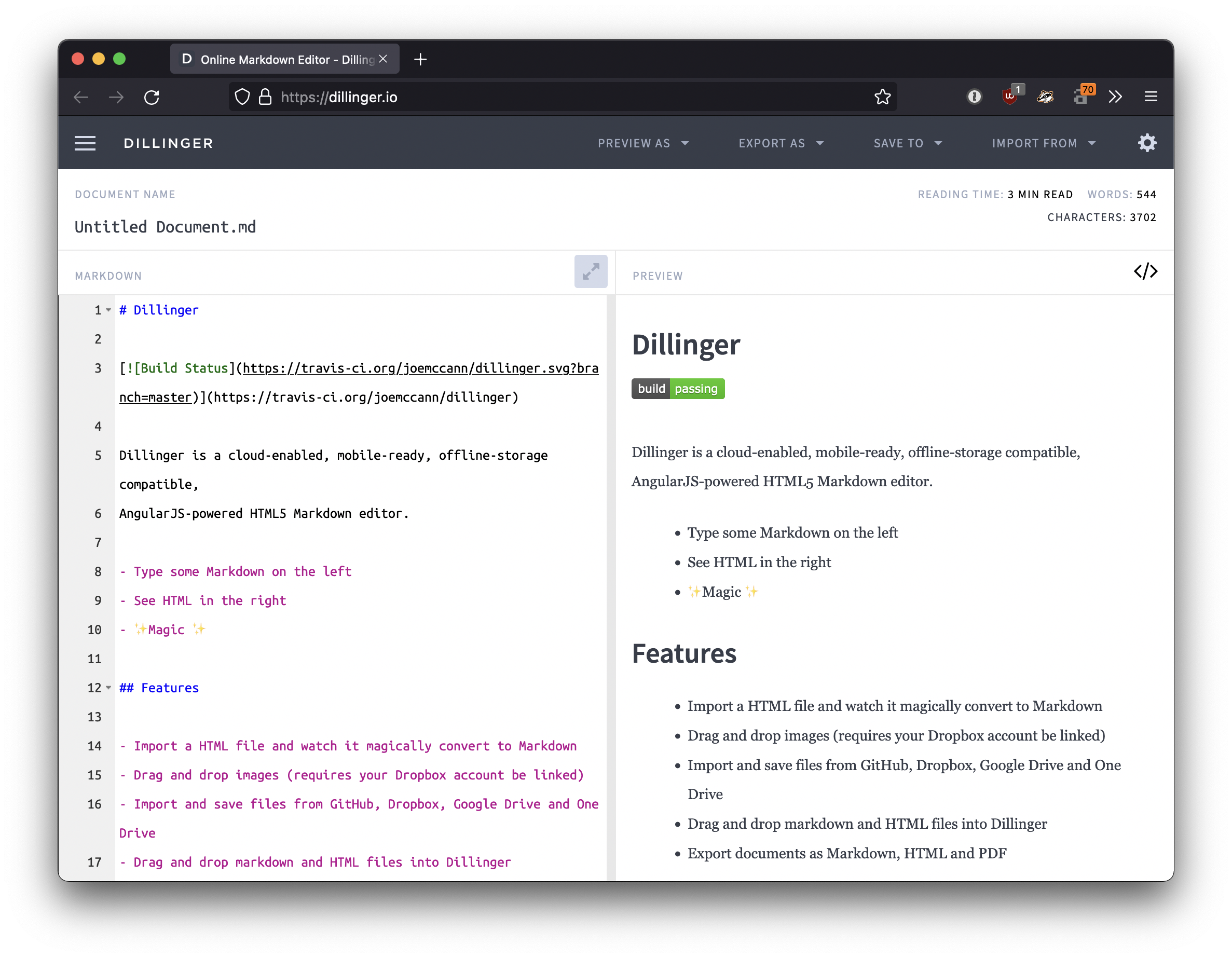
在阅读本指南时,您可能希望保持Dillinger网站的开放。这样,您可以在了解语法时尝试语法。熟悉Markdown后,您可能希望使用可以在台式计算机或移动设备上安装的Markdown应用程序。
它是如何工作的?
Dillinger使Markdown的写作变得简单,因为它隐藏了幕后发生的事情,但值得探索整个过程是如何运作的。
当您在Markdown中写入时,文本存储在具有.md或.markdown扩展名的纯文本文件中。但那又怎样?您的Markdown格式文件如何转换为HTML或可打印文档?
简短的回答是,您需要一个能够处理Markdown文件的Markdown应用程序。有很多可用的应用程序——从简单的脚本到看起来像Microsoft Word的桌面应用程序。尽管视觉上存在差异,但所有应用程序都做同样的事情。与Dillinger一样,他们都将Markdown格式的文本转换为HTML,以便可以在网页浏览器中显示。
Markdown应用程序使用一种名为Markdown处理器的东西(通常也称为“解析器”或“实现”)来获取Markdown格式的文本并将其输出为HTML格式。届时,您的文档可以在网页浏览器中查看,也可以与样式表相结合并打印。您可以在下面看到此过程的可视化表示注:Markdown应用程序和处理器是两个独立的组件。为了简短起见,我把它们合并到下图中的一个元素(“Markdown应用程序”)中。
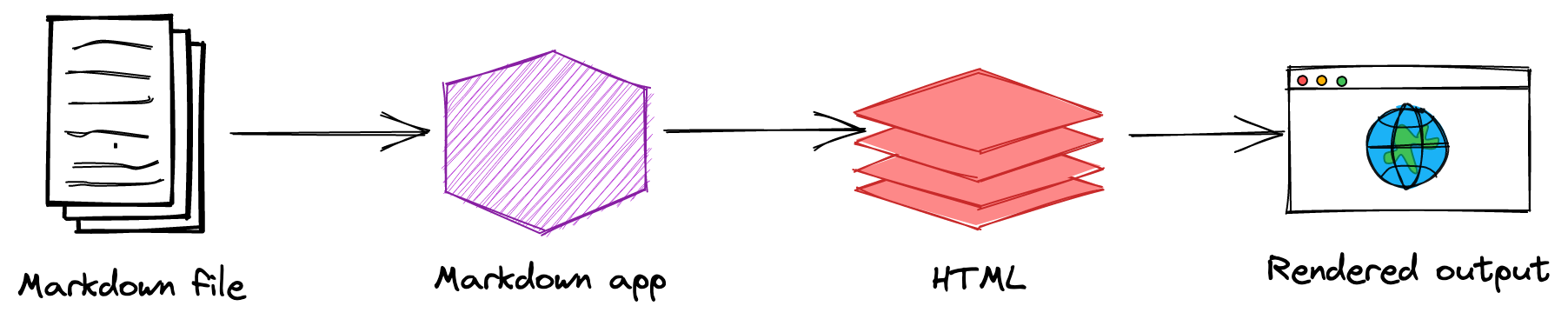
总之,这是一个由四部分组成的过程:
- 使用文本编辑器或专用的Markdown应用程序创建Markdown文件。文件应该有一个
.md或.markdown扩展名。 - 在Markdown应用程序中打开Markdown文件。
- 使用Markdown应用程序将Markdown文件转换为HTML文档。
- 在网页浏览器中查看HTML文件或使用Markdown应用程序将其转换为另一种文件格式,如PDF。
从您的角度来看,流程将因您使用的应用程序而异。例如,Dillinger基本上将步骤1-3组合成一个无缝的界面——您只需在左侧窗格中键入,渲染的输出神奇地出现在右侧窗格中。但如果您使用其他工具,例如带有静态网站生成器的文本编辑器,您会发现这个过程更明显。
减价有什么好处?
Markdown是一种快速简便的方式,可以记笔记、为网站创建内容和制作可打印文档。
学习Markdown语法不需要很长时间,一旦你学会了如何使用它,你几乎可以在任何地方使用Markdown写作。大多数人使用Markdown为网络创建内容,但Markdown有利于格式化从电子邮件到杂货清单的所有内容。
以下是一些你可以用Markdown做什么的例子。
网站
Markdown是为网络设计的,因此有很多应用程序专门为创建网站内容而设计,这不足为奇。
如果您正在寻找使用Markdown文件创建网站的最简单方法,请查看blot.im。注册Blot后,它会在您的计算机上创建一个Dropbox文件夹。只需将您的Markdown文件拖放到文件夹中,然后——噗!——它们就在您的网站上。这再简单不过了。
如果您熟悉HTML、CSS和版本控制,请查看Jekyll,这是一个流行的静态网站生成器,可以获取Markdown文件并构建HTML网站。这种方法的一个优势是GitHub Pages为Jekyll生成的网站提供免费托管服务。如果Jekyll不是你的爱好,只需从许多其他可用的静态站点生成器中选择一个。
如果您想使用内容管理系统(CMS)为您的网站供电,请查看Ghost。这是一个免费的开源博客平台,有一个不错的Markdown编辑器。如果您是WordPress用户,您会很高兴知道WordPress.com上托管的网站有Markdown支持。自托管的WordPress网站可以使用Jetpack插件。
文件
Markdown没有Microsoft Word等文字处理器的所有钟声和哨声,但它足以创建作业和字母等基本文档。您可以使用Markdown文档创作应用程序创建Markdown格式的文档并将其导出为PDF或HTML文件格式。PDF部分是关键,因为一旦您有了PDF文档,您可以使用它做任何事情——打印、通过电子邮件或上传到网站上。
以下是我推荐的一些Markdown文档创作应用程序:
- Mac:MacDown、iA Writer或Marked 2
- iOS/Android:iA Writer
- Windows:代笔人或Markdown Monster
- Linux:重写文本或代写
- Web:Dillinger或StackEdit
笔记
在几乎所有方面,Markdown都是记笔记的理想语法。可悲的是,最受欢迎的两个Note应用程序Evernote和OneNote目前不支持Markdown。好消息是,其他几个笔记应用程序确实支持Markdown:
- Obsidian是一款流行的Markdown记笔记应用程序,包含功能。
- Simplenote是一个免费的裸骨笔记应用程序,适用于每个平台。
- 值得注意的是,这是一个在各种平台上运行的笔记应用程序。
- Bear是一个类似于Evernote的应用程序,适用于Mac和iOS设备。默认情况下,它不只使用Markdown,但您可以启用Markdown兼容性模式。
- Joplin是一个尊重您隐私的笔记应用程序。它适用于每个平台。
- Boostnote本身是一个“为程序员设计的开源笔记应用程序”。
如果您无法放弃Evernote,请查看Evernote基于订阅的Markdown编辑器Marxico,或将Markdown Here与Evernote网站一起使用。
书籍
想自己出版一本小说吗?试试Leanpub,这项服务可以将您的Markdown格式的文件转换为电子书。Leanpub以PDF、EPUB和MOBI文件格式输出您的图书。如果您想创建图书的平装本,您可以将PDF文件上传到其他服务,如Kindle Direct Publishing。要了解有关使用Markdown撰写和自行出版书籍的更多信息,请阅读此博客文章。
演示文稿
信不信由你,你可以从Markdown格式的文件生成演示文稿。在Markdown中创建演示文稿需要一点时间来适应,但一旦掌握窍门,它就会比使用PowerPoint或Keynote等应用程序更快、更容易。Remark(GitHub项目)是一个流行的基于浏览器的Markdown幻灯片显示工具,Cleaver(GitHub项目)和Marp(GitHub项目)也是如此。如果您使用Mac并希望使用应用程序,请查看Deckset或Hyperdeck。
电子邮件
如果您发送了大量电子邮件,并且厌倦了大多数电子邮件提供商网站上可用的格式控制,您会很高兴地了解到使用Markdown编写电子邮件的简单方法。Markdown 这是一个免费的开源浏览器扩展,可以将Markdown格式的文本转换为HTML,并准备发送。
协作
协作和团队消息应用程序是与同事和朋友在工作和家庭中沟通的一种流行方式。这些应用程序没有使用Markdown的所有功能,但它们提供的功能相当有用。例如,无需使用WYSIWYG界面即可粗体和斜体显示文本非常方便。Slack、Discord、Wiki.js和Mattermost都是很好的协作应用程序。
文档
Markdown 自然适合技术文档。像GitHub这样的公司越来越多地切换到Markdown获取文档——查看他们的博客帖子,了解他们如何将Markdown格式的文档迁移到Jekyll。如果您为产品或服务编写文档,请查看以下方便的工具:
- 阅读文档可以从您的开源Markdown文件中生成文档网站。只需将您的GitHub存储库连接到他们的服务并推送——阅读文档即可完成其余操作。他们还为商业实体提供服务。
- MkDocs是一种快速简单的静态站点生成器,旨在构建项目文档。文档源文件用Markdown编写,并使用单个YAML配置文件进行配置。MkDocs有几个内置主题,包括一个用于MkDocs的Read the Docs文档主题端口。最新的主题之一是MkDocs Material。
- Docusaurus是一个静态网站生成器,专为创建文档网站而设计。它支持翻译、搜索和版本管理。
- VuePress是由Vue供电的静态站点发电机,经过优化以编写技术文档。
- Jekyll早些时候在网站上的章节中被提及,但它也是从Markdown文件中生成文档网站的好选择。如果您走这条路,请务必查看Jekyll文档主题。
Markdown的味道
使用Markdown最令人困惑的一个方面是,几乎每个Markdown应用程序都实现的Markdown版本略有不同。Markdown的这些变体通常被称为风味。掌握应用程序已实现的任何口味的Markdown都是您的工作。
要将你的头环顾Markdown口味的概念,将其视为语言方言可能会有所帮助。纽约市的人说英语和伦敦人一样,但这两个城市使用的方言之间有很大差异。使用不同Markdown应用程序的人也是如此。使用Dillinger使用Markdown写作与使用Ulysses有很大不同。
实际上,这意味着当他们说他们支持“Markdown”时,你永远不知道公司到底是什么意思。他们只谈论基本语法元素,还是所有基本和扩展语法元素的组合,还是语法元素的任意组合?在阅读文档或开始使用应用程序之前,您不会知道。
如果您刚刚起步,我可以为您提供的最佳建议是选择一个具有良好Markdown支持的Markdown应用程序。这将大大有助于维护Markdown文件的可移植性。您可能希望在其他应用程序中存储和使用Markdown文件,为此,您需要从提供良好支持的应用程序开始。您可以使用工具目录查找符合账单的应用程序。
其他资源
您可以使用许多资源来学习Markdown。以下是一些其他介绍性资源:
- John Gruber的Markdown文档。Markdown的创作者撰写的原始指南。
- 减价教程。一个开源网站,允许您在网页浏览器中尝试Markdown。
- 很棒的减价。Markdown工具和学习资源的列表。
- 排版标记。一个多部分系列,描述了使用pandoc和ConTeXt排版Markdown文档的生态系统。
计算机网络
什么是计算机网络
计算机网络是一组计算机或类似计算机的设备连接在一起,以共享文件、数据、软件、打印机、网络服务等网络资源。典型的计算机网络由在工作站计算机(也称为客户端或台式机)工作的用户组成,运行Windows 7、Windows 8/8.1或Windows 10等客户端操作系统,并将其文件存储在中央网络文件服务器中。

速度为10 Gbps(千兆位/秒)的计算机网络正在变得普遍。这些高速网络也非常多余。如果一条通往目的地的路径丢失,在几分之一秒内找到另一条通往目的地的路径,并运行。今天的计算机网络不仅用于文件传输或打印,还用于语音、视频、洪流等各种不同的流量类型。
网络通信和网络资源共享需要计算机网络(打印机、扫描仪、存储空间等)。为了构建和连接计算机网络,我们需要计算机(客户端和服务器)和特殊的网络基础设施设备,如交换机、路由器、防火墙、服务器等。
NPM
npm(node package manage of JavaScript)作用:Node.js下载后自带npm,类似于迅雷下载资源,可以下载项目所需的依赖模块/包。
- 允许用户从NPM服务器下载别人编写的第三方包到本地使用。
- 允许用户从NPM服务器下载并安装别人编写的命令行程序到本地使用。
- 允许用户将自己编写的包或命令行程序上传到NPM服务器供别人使用。
webpack
webpack是一个静态的模块化打包工具,为现代的JavaScript应用程序。
- 打包bundler:webpack可以将帮助我们打包的工具。
- 静态的static:将代码打包成最终的静态资源(css、js、html等部署到静态服务器)。
- 模块化module:支持模块化开发(ES module、CommonJS、AMD等)。
- 现代的modern:现代前端开发的复杂性催生了webpack的出现和发展。
Taro 安装及使用
taro-安装及使用
https://nervjs.github.io/taro/docs/GETTING-STARTED.html
安装
Taro 项目基于 node,请确保已具备较新的 node 环境(>=8.0.0),推荐使用 node 版本管理工具 nvm 来管理 node,这样不仅可以很方便地切换 node 版本,而且全局安装时候也不用加 sudo 了。
npx:
# 使用 npm 安装 CLI
$ npm install -g @tarojs/cli
# OR 使用 yarn 安装 CLI
$ yarn global add @tarojs/cli
# OR 安装了 cnpm,使用 cnpm 安装 CLI
$ cnpm install -g @tarojs/cli
mirror-config-china后重试。
$ npm install -g mirror-config-china
微信开发者工具,然后选择项目根目录进行预览。
微信小程序编译预览及打包(去掉 --watch 将不会监听文件修改,并会对代码进行压缩打包)
# yarn
$ yarn dev:weapp
$ yarn build:weapp
# npm script
$ npm run dev:weapp
$ npm run build:weapp
# 仅限全局安装
$ taro build --type weapp --watch
$ taro build --type weapp
# npx 用户也可以使用
$ npx taro build --type weapp --watch
$ npx taro build --type weapp
百度开发者工具,然后在项目编译完后选择项目根目录下 dist 目录进行预览。
百度小程序编译预览及打包(去掉 --watch 将不会监听文件修改,并会对代码进行压缩打包)
# yarn
$ yarn dev:swan
$ yarn build:swan
# npm script
$ npm run dev:swan
$ npm run build:swan
# 仅限全局安装
$ taro build --type swan --watch
$ taro build --type swan
# npx 用户也可以使用
$ npx taro build --type swan --watch
$ npx taro build --type swan
支付宝小程序开发者工具,然后在项目编译完后选择项目根目录下 dist 目录进行预览。
支付宝小程序编译预览及打包(去掉 --watch 将不会监听文件修改,并会对代码进行压缩打包)
# yarn
$ yarn dev:alipay
$ yarn build:alipay
# npm script
$ npm run dev:alipay
$ npm run build:alipay
# 仅限全局安装
$ taro build --type alipay --watch
$ taro build --type alipay
# npx 用户也可以使用
$ npx taro build --type alipay --watch
$ npx taro build --type alipay
字节跳动小程序开发者工具,然后在项目编译完后选择项目根目录下 dist 目录进行预览。
字节跳动小程序编译预览及打包(去掉 --watch 将不会监听文件修改,并会对代码进行压缩打包)
# yarn
$ yarn dev:tt
$ yarn build:tt
# npm script
$ npm run dev:tt
$ npm run build:tt
# 仅限全局安装
$ taro build --type tt --watch
$ taro build --type tt
# npx 用户也可以使用
$ npx taro build --type tt --watch
$ npx taro build --type tt
QQ 小程序开发者工具,然后在项目编译完后选择项目根目录下 dist 目录进行预览。
QQ 小程序编译预览及打包(去掉 --watch 将不会监听文件修改,并会对代码进行压缩打包)
# yarn
$ yarn dev:qq
$ yarn build:qq
# npm script
$ npm run dev:qq
$ npm run build:qq
# 仅限全局安装
$ taro build --type qq --watch
$ taro build --type qq
# npx 用户也可以使用
$ npx taro build --type qq --watch
$ npx taro build --type qq
快应用开发者工具,然后在项目编译完后,在开发者工具中选择「打开文件夹」选择项目根目录下 dist 目录,点击左边的预览图标(那个眼睛图标)进行预览。
快应用编译预览及打包(去掉 --watch 将不会监听文件修改,并会对代码进行压缩打包)
# yarn
$ yarn dev:quickapp
$ yarn build:quickapp
# npm script
$ npm run dev:quickapp
$ npm run build:quickapp
# 仅限全局安装
$ taro build --type quickapp --watch
$ taro build --type quickapp
# npx 用户也可以使用
$ npx taro build --type quickapp --watch
$ npx taro build --type quickapp
快应用开发者工具如何使用?点击了解
快应用端开发流程
React Native 教程
# yarn
$ yarn dev:rn
# npm script
$ npm run dev:rn
# 仅限全局安装
$ taro build --type rn --watch
# npx 用户也可以使用
$ npx taro build --type rn --watch
Note:React Native 端和其他端样式兼容性差异较大,如果需要兼容 React Native 端,建议 React Native 端和其他端同步开发。
Note:如果要支持 React Native 端,必须采用 Flex 布局,并且样式选择器仅支持类选择器,且不 支持 组合器 Combinators and groups of selectors。
以下选择器的写法都是不支持的,在样式转换时会自动忽略。
.button.button_theme_islands{
font-style: bold;
}
img + p {
font-style: bold;
}
p ~ span {
color: red;
}
div > span {
background-color: DodgerBlue;
}
div span { background-color: DodgerBlue; }
样式上 H5 最为灵活,小程序次之,RN 最弱,统一多端样式即是对齐短板,也就是要以 RN 的约束来管理样式,同时兼顾小程序的限制,核心可以用三点来概括:
- 使用 Flex 布局
- 基于 BEM 写样式
- 采用 style 属性覆盖组件样式
RN 中 View 标签默认主轴方向是 column,如果不将其他端改成与 RN 一致,就需要
开源软件的依赖性
开源软件的依赖性
由于开源软件分散开发和相互依赖的特点,所以deb软件包也存在着的依赖关系。比如A开发了一个系统的大致框架,该框架的特点就是提供前端界面开发并且开源,但是界面很丑,B在用他的框架时改进了前端界面,并将前端界面的包开源。那么C如果在使用该软件时,不能只安装B发布的开源软件,而是需要将A的开源软件一起安装,否则就会出现依赖问题。常见的依赖关系:
- depends(依赖):想要安装B,就必须要安装A,不安装A没法使用
- conflicts(冲突):想要安装B,就不可以安装A
- recommends(推荐):安装完B后,为了凸显本软件的功能强大,推荐安装A,不安装A也可以正常使用
从源头安装系统
从源头安装入门指南
类别:Linux
导言
本文件适用于希望直接从原始作者安装软件的开源操作系统用户,而不仅仅是依赖其操作系统提供的软件(和版本)。它是为那些不熟悉以源代码形式下载软件概念的人编写的,提供有关相关命令和一般过程的背景资料。
讨论的概念
- 开发和分发:独立的软件开发人员、多操作系统支持、版本(档案)、版本控制
- 发行版:二进制包和包经理
- 下载:http、ftp、小部件、校验和和签名
- 存档文件:tar、zip、gzip
- 常见文件:README和INSTALL;必需依赖项
- 用sed/awk/patch补丁进行补丁
- 构建和安装:配置、制作、制作、perl和python
- 构建和安装文档
- 编译器设置和剥离;处理错误
- 安装后
开发和分配
一个典型的操作系统由数百个不同的应用程序组成。在专有操作系统中,该操作系统的生产者/销售商通常拥有和管理所有软件的开发。然而,开源系统通常是通过获取和集成许多独立团体——甚至单个独立开发人员发明和维护的应用程序来创建的。此外,开源软件项目通常用于各种不同的操作系统——例如基于Linux、基于BSD、Hurd,有时甚至集成到Solaris、Mac甚至Windows等专有操作系统中(如果许可证允许)。
分发维护人员和最终用户有时会将原始软件开发人员称为上游源或简单的上游源。同样,开发人员通常将使用代码的发行版或最终用户称为下游。
大多数开源项目将其源代码存储在可以通过互联网访问的版本控制系统中(仅供匿名用户阅读)。对于此类项目,可以下载最新的“进行中”文件,或下载带有一些发布ID(版本号)的“标记”文件集。然而,这样做通常效率不高;项目通常通过创建包含所有相关文件的存档文件并可供下载来定期发布。对于没有公共版本控制系统的项目,此类定期发布的存档文件是直接获取源代码的唯一方法。
分发、二进制包和从源编译
有许多操作系统发行版负责查找、下载和调整所有最常用的软件包。几个也编译了它,并提供了二进制形式的结果。有很多好处,包括更快的安装,一个查找相关软件的位置,特别是提供相关的安全补丁:分发维护人员关注安全更新,并使最终用户易于注意到和安装它们。
然而,此类发行版通常不包括最新版本的软件;如果您需要比发行版提供的版本更新的版本,那么可能需要自己构建它。软件在安装时通常也非常可定制,特别是能够省略不需要的功能。由于分发需要让广大用户满意,他们倾向于在分发的编译应用程序中包含每个功能;作为最终用户,您或许可以通过自己编译应用程序来更好地调整应用程序。
分发通常包括一个软件包管理器,该管理器保存安装了哪些软件的数据库。在软件包管理器的“背后”更改机器上的软件不是一个好主意;以后可能会发生各种奇怪的行为。如果您的分发有软件包管理器,请阅读此文档以获取背景信息——但请参阅分发的文档,以了解如何在不混淆软件包管理器的情况下安装软件。这通常涉及编写描述软件的软件包规范,然后使用本地软件包管理器编译和安装软件。这适用于所有具有软件包经理的发行版,无论应用程序是以二进制(预编译)还是源代码形式分发。
下载和安全性
下载存档文件的通常方法是使用网页浏览器并单击“下载”按钮,单击链接,或右键单击链接并选择“另存为”。这将使用“http”协议下载文件。相反,一些网站通过旧的“ftp”协议提供文件。许多网页浏览器也支持这一点(单击链接也可以在这里工作)。或者,还有ftp客户端应用程序。
当已知正确的URL时,“wget”或“curl”命令行应用程序也可以在类似unix的操作系统下通过http或ftp获取文件。
发布经常下载的软件的网站通常设置“镜像”网站(有用的人在世界各地保存文件副本)。原始网站通常有可用镜子的列表,您应该选择一个离您很近的镜子。这有助于降低原始发布者的网络带宽成本,通常还允许您更快地下载。
“http”和“ftp”网络协议都可以被犯罪分子或其他不良方拦截,然后他们可以在下载时修改数据。数据也可能在进行中意外损坏(尽管这并不常见)。使用镜像站点时,可能有人修改了那里的文件(即镜像上的文件与原始发布者的文件不同)。因此,验证您下载的内容是否是原始出版商的意图是一个好主意。
许多网站为每个存档文件提供一个md5sum文件,该文件包含文件内容的校验和;有时单个md5sums文件包含许多其他文件的校验和。您应该始终从原始站点获取md5sums文件,而不是镜像。如果可能,您应该通过安全的https协议下载它。然后可以使用unix md5sum命令行工具计算大存档文件的校验和,并将其与预期值进行比较,以确保内容正常。
要计算单个文件的总和:
md5sum file-to-check
并“手动”根据预期值验证此应用程序的输出。如果值在网页中,您可以在该页面上打开“查找”对话框,并复制粘贴md5sum程序输出的值。只有当值相同时,“查找”才会匹配。
如果软件提供商提供了一个md5sums文件,该文件包含(文件名、校验和)对列表,那么您可以运行:
md5sum -c md5sums-file
它将在您的本地系统中查看md5sums文件中列出的每个文件,计算其校验和,如果它不是预期值,则报告错误。
一些软件提供商签署存档文件,而不是(或)提供md5校验和。在这种情况下,您应该:
- 从他们的网站上下载提供商的公钥(尽可能使用https)
- 下载存档文件的“签名文件”;这将是一个小文件,其基名与下载的文件相同,后缀为“.sig”或“.asc”
- 执行以下步骤
# needed only once for each key, ie each "publisher"
gpg --import {public-key}
gpg --verify {signature-file-name}
验证步骤解密签名文件,显示校验和;然后,它在真实文件上运行校验和算法,并检查它们是否相同。显然,“gpg”应用程序需要在本地安装。
归档文件
归档是一个包含许多其他文件的单个文件。创建此类文件有几种不同的工具,但在所有情况下,该过程都是有效地将所有单个文件附加在一起,然后添加一个包含原始文件的偏移量、长度、名称和其他属性的“索引”,以便再次提取它们。
注:英语中的“存档”一词可能意味着“旧”、不再使用或“备份”副本。虽然存档文件可用于存储备份或很少使用的数据,但它们也便于在网络上传递数据。
“tar”应用程序将多个文件打包到单个“tar格式”存档文件中,这是开源中最常用的格式。Tar最初的意思是“磁带存档”,但格式在磁盘上也很好用。Tar档案不仅记住文件的原始名称,还记住其原始Unix“所有者ID”和文件权限。ownerid很少有用(除非tar归档是在它正在解压的同一台机器上创建的),但文件权限是有用的。按照惯例,tar格式文件通常以“.tar”结尾。包含源代码的tar格式文件有时被称为“tarballs”。
焦油应用程序不会压缩文件内容。然而,源代码文件确实压缩得很好,网络带宽总是太慢太贵,所以焦油文件通常在创建后使用通用压缩应用程序进行压缩。最常用的压缩类型是“gzip”,生成的文件通常后缀为“.tar.gz”或“.tgz”。使用bzip2压缩也很常见,此类文件通常后缀为“.tar.bz2”。偶尔会使用“xz”压缩;文件通常后缀为“.tar.xz”。
焦油应用程序的原始版本是很久以前创建的,并已多次重新实施。可悲的是,这意味着可用的命令行选项因您使用的应用程序版本而异。该功能也因版本而异;特别是一些版本可以在使用压缩时自动检测,并自动解压缩,而另一些版本则需要传递正确的命令行参数来处理压缩文件,还有一些版本要求首先解压缩文件。以下是从tar存档中提取文件的一些示例命令:
# Modern GNU tar options. This works for files compressed
# with gzip and bzip too
tar --extract --file filename
# Same as above
tar -xf filename
# Same as above. Leading "-" is optional
tar xf filename
# explicitly decompress gzip2-compressed file then
# pass uncompressed result directly into tar
gzip -cd filename.tgz | tar xf -
# same as above, but for bzip2-compressed files
bunzip2 -cd filename.tar.bz2 | tar xf -
请注意,如果省略“f”,焦油似乎就会挂起(等待用户输入)。
警告:解压焦油文件可以覆盖本地文件。默认情况下,文件被解压缩到当前目录的子目录中,只要当前目录合适,子目录就应该安全。然而,不要相信使用以下选项的任何说明;它们可能试图诱骗您修改重要的本地文件:
-C or --directory
-P or --absolute-names
--transform or --xform
大多数tar文件的创建是为了在当前目录中打开它们创建一个子目录,所有其他文件都放置到该目录中;例如解包名为“foo-1.2.tar.gz”的文件将创建一个名为“foo-1.2”的子目录,其中包含该目录中的文件。可悲的是,并非所有打包源代码供下载的人都遵循这一惯例;有时tarfile将其内容直接扩展到当前目录中——如果该目录中已经有文件,可能会造成大混乱。因此,最好在解压之前使用以下命令检查tarfile的内容:
# Modern GNU tar
tar --list --file filename
# Same as above
tar -tf filename
# Same as above. Leading "-" is optional
tar tf filename
gzip -cd filename | tar tf -
bunzip -cd filename | tar tf -
档案文件偶尔会以“zip格式”分发。Zip-archives在DOS和Windows世界中或与Java有关中最为常见,但偶尔会在其他地方遇到。Zip格式的工作原理类似于tar和gzip的组合(它使用与gzip相同的压缩,但也有自己的内部“索引”)。Zipfiles不保留原始unix所有者或文件权限。可以使用unzip命令提取此类文件的内容(假设它是本地安装的)。
在可能的情况下,以普通用户身份登录时,而不是“根”用户登录时,应解压归档文件。这是防止任何意外文件覆盖的额外安全措施。然而,只有当解压存档的用户是根用户时,tar文件中记录的文件所有者设置才会保留。如果这些很重要(这并不常见),那么档案必须“作为根”解封。
常用文件
未打包的源代码存档通常在顶级目录中包含名为README或INSTALL(或两者兼而有之)的文件。您应始终首先阅读这些文档,因为它们提供了有关如何编译、安装和配置下载存档中其余源代码的重要信息。
README或INSTALL中通常可以找到的一个重要信息是必须首先安装的其他软件的列表。您下载的任何程序都需要一些本地标头文件、库文件和/或帮助工具来构建或运行。如果您没有正确获得先决条件,那么应用程序可能无法编译,或可能编译但不运行,或者可能在没有您想要的某些可选功能的情况下构建。
另一个重要信息是可以传递给构建过程的参数集;稍后见。
补丁
有时,已知下载的软件在您的环境中不起作用,并且有人已经想出如何调整它来解决问题。解决问题的人可以sed或awk命令、包含多个sed/awk命令的shell脚本或补丁文件的形式发布他们的“调整”。显然,您需要对此类更改保持谨慎,只有在您信任源或能够再次检查更改时才应用它们。
sed工具对文本文件中的每一行应用正则表达式,并将匹配的文本替换为其他内容。这是一个相当有限的工具,但易于使用和广泛使用。
awk做类似的事情,但能够对文本文件进行更复杂的转换。
使用“差异”工具创建补丁文件,以比较同一文件的两个版本并输出差异。patch工具可以获取“差异”的输出,并将其应用于其中一个文件,以将其“转换为”到另一个版本。Patchfiles(即差异的输出)的好处是,它非常易于阅读(很容易看到将做出哪些更改)。
构建系统:配置、制造、制作等
创建您刚刚下载的软件的软件开发人员显然需要某种方法来在自己的机器上编译和安装该软件。无论他们使用的工具需要什么配置文件,几乎总是包含在存档文件中。由于开源开发人员希望尽可能多的人使用他们的软件,他们也做出了一些努力,以便在一系列不同的系统上轻松构建和安装软件。然而,他们无法支持世界上所有可能的配置。
最后,安装过程的重点是将原始源代码转换为本地计算机可以执行的形式,然后将所有必要的文件放入$PATH变量中列出的目录中,供所有用户使用(以便他们可以执行这些文件)。为解释语言安装模块略有不同;这些文件安装在解释器(例如python或perl)可以找到它们的地方,而不是直接在$PATH中。
配置和制作
用于管理源代码编译和安装的最广泛传播的工具是make。Make是一个应用程序,它使用包含规则列表的配置文件(称为makefile),其中大多数形式:
- 当TARGET-FILE比SOURCE-FILE旧时,SOME-ACTION
目标文件是最终产品,或某个中间阶段。源文件是手写的源代码或一些中间工件。该操作通常是调用重新创建目标文件的编译器、链接器或类似程序。本文档太短了,无法详细介绍非常复杂和强大的make命令;幸运的是,编译软件通常不需要理解makefiles——除非出错。附录A中对makefile语法和行为的简要说明。
不幸的是,尽管makefile语法非常强大,但它仍然不足以处理计算机配置的所有可能方式,以及安装软件的人可能希望编译应用程序的所有可能方式。因此,许多软件包都附带一个名为“配置”的shell脚本和一个名为“Makefile.in”的模板makefile。配置脚本在命令行上获取配置选项列表,并将模板makefile转换为为本地计算机和安装程序的愿望定制的真实makefile。因此,安装顺序通常如下:
# unpack and read documentation
tar xf filename
cd {directory created by above step}
less README
less INSTALL
# generate customised makefile
./configure {some options ...}
# compile everything in the local directory
make
# update global directories
sudo make install
顺便说一句:“配置”脚本由名为autotools的软件自动生成,但这对使用它的人来说无关紧要。
配置通常调用为“./configure”,以避免两个可能的问题:
- 一些用户的
$PATH变量中没有“.”。特别是,出于安全原因,根用户没有这个 - 一些用户没有“.”作为
$PATH中的第一个条目,这意味着错误的配置脚本可能会被运行
一般来说,最好作为普通系统用户执行除“安装”以外的所有步骤,而不是root。这避免了错误和一些攻击(尽管安装步骤是作为根完成的,保护程度不高)。然而,将软件安装到全局/bin或/usr目录通常需要管理特权(除非您使用“基于用户的软件包管理器”或类似的罕见设置)。
一些项目提供了一个makefile,但没有“配置”脚本;在这种情况下,可以省略上面的“配置”步骤。要么应用程序足够简单,不需要它,要么软件开发人员在手写的makefile中构建了更多的逻辑。
并非所有系统都启用了“sudo”。在这种情况下,请改为使用以下内容:
su # must then enter root password
make install
exit
对于大多数软件,配置和make命令可以在与源代码相同的目录中运行,如上所示。结果是,编译期间生成的新文件与原始文件混合在一起,这有点混乱,但“清理”命令可用于稍后整理。然而,对于某些软件,有必要创建一个临时目录,将当前工作目录更改为该目录,然后在那里执行构建步骤;项目文档应指示是否有必要。有些人认为总是从临时目录构建更好。使用原始源代码旁边的单独目录构建的示例,这是一个常见的约定:
# unpack into a directory {packagename}
tar xf filename
# create separate build directory
mkdir {packagename}-build
# compile everything in the separate build directory
cd {packagename}-build
../{packagename}/configure {some options}
make
# update global directories
sudo make install
其他构建工具
一些项目使用cmake作为构建工具。cmake的工作有点像configure(见上文);它生成一个makefile,其内容取决于传递给cmake命令的选项和本地系统的功能。构建基于cmake的软件包所需的步骤与上面的“配置/制作”示例相同,只是配置步骤被以下部分取代:
cmake . -DCMAKE_BUILD_TYPE=Release {some options ...}
像往常一样,查看项目的文档,了解有关如何构建的说明。
一些项目使用基于python或perl而不是make的构建工具。这些原则仍然相当相似。
不需要编译的软件通常有一个相当简单和快速的安装过程。特别是,只需将文件复制到相关位置,就可以安装用Perl或Python解释语言编写的应用程序。然而,这些项目在档案文件中包含执行此任务的程序或脚本,而不是要求安装程序手动执行。
环境变量
配置应用程序编译和安装的选项通常作为命令行参数传递给“配置”脚本或make程序。然而,有时配置选项会通过environment variables传递。这些可以通过将定义放在命令的开头来指定,例如
NAME=tom ENABLE_FOO=no ./configure
在运行命令之前,也可以定义环境变量:
export NAME=tom
export ENABLE_FOO=no
./configure
档案的README或INSTALL文件或项目网站上通常会描述哪些选项可用。有时可以通过运行./configure --help查看可用的选项。
构建和安装文档
一些项目提供的文档可以“安装”,以便通过普通系统文档查看器(如“man”或“info”)访问。有些以HTML形式提供文档,通常安装在/usr/share/doc下。有时此文档包含在“标准”存档文件中,有时是单独的(可选)下载。有时文档是作为标准make install命令的一部分安装的,有时如果您希望安装它,则必须使用单独的命令。有时文档以“即用”形式交付,但有时以一种“原始形式”交付,在安装前必须处理——就像需要编译源代码一样。
现在应该清楚的是,提供文件的各种方法如此广泛,在这里无法提供真正有用的建议。有关指导,请参阅下载档案中的README和INSTALL文件以及项目网站。
其他构建目标
除了编译所有内容(“make”)和安装之前编译的程序(“make install”)或文档的命令外,还有其他一些常见的可能性。
make clean通常删除所有生成的文件(像文件从存档中解包后那样离开目录)。
调用编译器
如上所述,“make”或“cmake”执行的最常见的步骤是调用编译器。本地系统必须安装适当的编译器。
这也是最有可能失败的步骤(与链接一起)。
如果编译步骤失败,出现无法找到头文件或找不到库文件的错误消息,那么您可能还没有安装所有先决条件——重新阅读README和INSTALL文件。在某些情况下,缺失的先决条件是可选的,在这种情况下,将有一个参数可以传递用于配置,或者一个环境变量可以设置为允许在没有该先决条件的情况下安装软件。仔细检查您指定的参数,如果它们看起来正确,那么项目文档是解决这些问题的最佳资源。
编译器有一系列可能提高性能的选项。然而,只有当你有丰富的经验时,你才应该搞砸这些。如果您需要此文档,只需将编译器选项保留在默认值!
编译和链接的输出(您实际想要的“可执行文件”)通常包含大量数据,这些数据对调试程序有用,但对“正常最终用户”没有用。可以通过在可执行文件上运行strip {filename}从其中删除此信息。较小的程序将节省磁盘空间,加载速度也略快。除非您打算调试程序,否则使用strip是一个好主意。
安装后配置
一些应用程序可以通过在应用程序启动时读取配置文件自定义其行为。应用程序通常会在/usr或/etc目录的某个地方安装配置文件的默认版本。检查make install命令的输出,看看安装了哪些配置文件。配置选项也应记录在程序的README或INSTALL或他们的网站上。
附录A:Makefile示例
不幸的是,从源代码构建软件包时,编译错误发生并不罕见。有时可以通过检查makefile来诊断和解决问题(对makefile语法的基本理解可能会有帮助)。以下是基本语法和功能的非常简短的例子;有关更多详细信息,请参阅make文档或在线提供的众多教程之一。
用于构建名为“prog”的可执行文件的示例makefile具有一个“c”源文件、一个头文件并使用一个库(它也从单个“c”源文件构建)可能如下所示:
prog: prog.c prog.h libmylib.a
gcc -o prog prog.c -L. -lmylib
libmylib.a: libmylib.o
ar -rcs libmylib.a libmylib.o
libmylib.o: libmylib.c libmylib.h
gcc -c -o libmylib.o libmylib.c
条目(规则)的形式是:
target: dependency1 [dependency-n ...]
<tab> command to execute
...
对于每个“规则”,如果目标缺失或超过任何依赖项(基于文件时间戳),则运行命令以(重新)创建目标。然而,首先测试每个依赖项,看看是否有规则将其作为目标。如果是这样,则递归评估该目标,即如果它缺失或超过其依赖项,则对其进行(重建)。
因此,在上述规则中,libmylib.c的更改将导致libmylib.o的重建。然后libmylib.a被再生,最后prog被重建。
Makefiles可能会变得非常复杂,许多文件是自动生成的,但上述原则始终适用。
确认
在线语法转换
管理数字
主机管理
cpu、内存、网络、硬盘IO、硬盘大小
虚拟机管理
Redhat Linux、CentOS Linux、FreeBSD、Windows各个版本的虚拟机
容器管理
创建、启动停止、销毁容器、保存镜像、日志、登录容器 Shell内部,容器的 CPU、内存、网络、磁盘数据
存储管理
共享存储、分布式存储、NFS、Gluster、Ceph、存储路径>特定容器、容器销毁>选择删除数据
镜像管理
镜像仓库、镜像删除、SSL、用户命名空间隔离、镜像仓库的多用户管理
配置配置
容器/虚机的各种参数设置、应用运行的参数和配置文件、检查策略定义、优先级配置、导入预先定义的模版
运行管理
应用编排模板>部署到指定的主机分组中形成>应用实例、应用在线升级和回滚、代码上下传、负载均衡的自动发现、扩容缩容管理、克隆运行中的应用
权限管理
用户管理的主机、虚拟机、容器、应用
代码管理
Github、GitLab
制品管理
依赖包完善的存储管理
构建管理
自动化构建中心
部署管理
简化运行环境搭建、发布应用到多个环境
备份
备份种类
- 全部备份(Full Backup),即把硬盘或数据库内的所有文件、文件夹或数据作一次性的复制。
- 增量备份(Incremental Backup),指对上一次全部备份或增量备份后更新的数据进行备份。
- 差异备份 (Differential backup) 差异备份提供运行完整备份后变更的文件的备份
- 选择式备份,对系统的一部分进行备份。
- 冷备份:系统处于停机或维护状态下的备份。这种情况下,备份的数据与系统中此时段的数据完全一致。
- 热备份:系统处于正常运转状态下的备份。这种情况下,由于系统中的数据可能随时在更新,备份的数据相对于系统的真实数据可有一定滞后。
备份类型
- 在线备份 (On-line Backup) : 需要及时还原的数据可以采用这种类型的备份,可以使用磁盘阵列、存储局域网、网络附加存储或者是网络硬盘来保护数据安全。
- 离线备份 (Off-line Backup ): 离线备份使用可离线媒体来备份,磁带、光盘或是硬盘盒备份完成后离开备份媒体。
数据处理技术
- 数据压缩技术(Compression):通过各种机制来降低备份数据的大小,以便占用更少的存储空间,压缩的方法在磁带存储中尤为常见。
- 数据重复删除技术(De-duplication){什么是重复数据删除?}:当多个相似系统的数据要备份到同一台存储设备上时,需要重复备份数据,这会产生大量的冗余。例如,有20个Windows工作站要备份到同一台存储设备上,备份数据就可以共享系统文件。存储设备上只需要一份系统文件,就可以用来恢复多个工作站。这项技术可以应用在文件级,也可以应用在未经处理的数据块级,通过避免冗余数据的重复复制,可以大大节省存储设备的存储空间。重复数据删除技术可以发生在服务器端,在数据备份到存储之前执行,这种方法可以在节省存储空间的同时节省备份数据的带宽需求,这种方式的重复数据删除叫做在线即时数据处理(inline);重复数据删除技术也可以发生在存储设备端,称之为后台重复数据删除技术。
- 数据复制技术(Duplication):在备份的过程中,数据有可能需要额外备份到第二组存储设备;通过将备份数据复制,可以调整备份镜像来优化恢复速度,而且可以将第二份备份数据存放在不同的备份地点,或不同的备份介质上。
- 数据加密技术(Encryption):对于大容量的可移动的备份存储介质,例如磁带,会面临丢失和被盗的风险。[1]通过对数据加密可以降低上述风险,但是也带来了另外的问题:首先,加密会占用大量的CPU进程,从而降低了备份速度;其次,数据被加密之后,就不能有效地压缩,例如某些磁带驱动器的数据压缩技术无法实施。基于上述原因,以及冗余数据导致解密分析供给更加容易,很多加密技术都在实施之前进行压缩;最后,加密技术要成功起作用,必须配合整体的安全策略通盘考虑。
- 数据缓冲技术(Staging):利用数据缓冲技术,备份数据在复制到磁带之前,会先复制到缓冲磁盘,这个操作称之为D2D2T,磁盘到磁盘到磁带。数据缓冲技术(虚拟带库技术)在基于网络的备份系统中尤为重要,因为D2D2T技术可以缓解系统对于备份带宽的需求。如果备份系统中需要执行其他的数据操作,缓冲磁盘还可以起到数据中心的作用。
操作系统词典
-
操作系统(Operating System,OS):是管理计算机硬件与软件资源的系统软件,同时也是计算机系统的内核与基石。操作系统需要处理管理与配置内存、决定系统资源供需的优先次序、控制输入与输出设备、操作网络与管理文件系统等基本事务。操作系统也提供一个让用户与系统交互的操作界面。 -
shell:它是一个程序,可从键盘获取命令并将其提供给操作系统以执行。 在过去,它是类似 Unix 的系统上唯一可用的用户界面。 如今,除了命令行界面(CLI)外,我们还具有图形用户界面(··)。 -
GUI (Graphical User Interface):是一种用户界面,允许用户通过图形图标和音频指示符与电子设备进行交互。、 -
内核模式(kernel mode): 通常也被称为超级模式(supervisor mode),在内核模式下,正在执行的代码具有对底层硬件的完整且不受限制的访问。 它可以执行任何 CPU 指令并引用任何内存地址。 内核模式通常保留给操作系统的最低级别,最受信任的功能。 内核模式下的崩溃是灾难性的; 他们将停止整个计算机。 超级用户模式是计算机开机时选择的自动模式。 -
用户模式(user node):当操作系统运行用户应用程序(例如处理文本编辑器)时,系统处于用户模式。 当应用程序请求操作系统的帮助或发生中断或系统调用时,就会发生从用户模式到内核模式的转换。在用户模式下,模式位设置为1。 从用户模式切换到内核模式时,它从1更改为0。 -
计算机架构(computer architecture): 在计算机工程中,计算机体系结构是描述计算机系统功能,组织和实现的一组规则和方法。它主要包括指令集、内存管理、I/O 和总线结构
-
SATA(Serial ATA):串行 ATA (Serial Advanced Technology Attachment),它是一种电脑总线,负责主板和大容量存储设备(如硬盘及光盘驱动器)之间的数据传输,主要用于个人电脑。 -
复用(multiplexing):也称为共享,在操作系统中主要指示了时间和空间的管理。对资源进行复用时,不同的程序或用户轮流使用它。 他们中的第一个开始使用资源,然后再使用另一个,依此类推。 -
大型机(mainframes):大型机是一类计算机,通常以其大尺寸,存储量,处理能力和高度的可靠性而著称。它们主要由大型组织用于需要大量数据处理的关键任务应用程序。 -
批处理(batch system): 批处理操作系统的用户不直接与计算机进行交互。 每个用户都在打孔卡等脱机设备上准备工作,并将其提交给计算机操作员。 为了加快处理速度,将具有类似需求的作业一起批处理并成组运行。 程序员将程序留给操作员,然后操作员将具有类似要求的程序分批处理。 -
OS/360: OS/360,正式称为IBM System / 360操作系统,是由 IBM 为 1964 年发布的其当时新的System/360 大型机开发的已停产的批处理操作系统。 -
多处理系统(Computer multitasking):是指计算机同时运行多个程序的能力。多任务的一般方法是运行第一个程序的一段代码,保存工作环境;再运行第二个程序的一段代码,保存环境;……恢复第一个程序的工作环境,执行第一个程序的下一段代码。 -
分时系统(Time-sharing):在计算中,分时是通过多程序和多任务同时在许多用户之间共享计算资源的一种系统 -
相容分时系统(Compatible Time-Sharing System):最早的分时操作系统,由美国麻省理工学院计算机中心设计与实作。 -
云计算(cloud computing):云计算是计算机系统资源(尤其是数据存储和计算能力)的按需可用性,而无需用户直接进行主动管理。这个术语通常用于描述 Internet 上可供许多用户使用的数据中心。 如今占主导地位的大型云通常具有从中央服务器分布在多个位置的功能。 如果与用户的连接相对较近,则可以将其指定为边缘服务器。 -
UNIX 操作系统:UNIX 操作系统,是一个强大的多用户、多任务操作系统,支持多种处理器架构,按照操作系统的分类,属于分时操作系统。 -
UNIX System V:是 UNIX 操作系统的一个分支。 -
BSD(Berkeley Software Distribution):UNIX 的衍生系统。 -
POSIX:可移植操作系统接口,是 IEEE 为要在各种 UNIX 操作系统上运行软件,而定义API的一系列互相关联的标准的总称。 -
MINIX:Minix,是一个迷你版本的类 UNIX 操作系统。 -
Linux:终于到了大名鼎鼎的 Linux 操作系统了,太强大了,不予以解释了,大家都懂。 -
DOS (Disk Operating System):磁盘操作系统(缩写为DOS)是可以使用磁盘存储设备(例如软盘,硬盘驱动器或光盘)的计算机操作系统。 -
MS-DOS(MicroSoft Disk Operating System):一个由美国微软公司发展的操作系统,运行在Intel x86个人电脑上。它是DOS操作系统家族中最著名的一个,在Windows 95以前,DOS是IBM PC及兼容机中的最基本配备,而MS-DOS则是个人电脑中最普遍使用的DOS操作系统。
MacOS X,怎能少的了苹果操作系统?macOS 是苹果公司推出的基于图形用户界面操作系统,为 Macintosh 的主操作系统
-
Windows NT(Windows New Technology):是美国微软公司 1993 年推出的纯 32 位操作系统核心。 -
Service Pack(SP):是程序的更新、修复和(或)增强的集合,以一个独立的安装包的形式发布。许多公司,如微软或Autodesk,通常在为某一程序而做的修补程序达到一定数量时,就发布一个Service Pack。 -
数字版权管理(DRM):他是工具或技术保护措施(TPM)是一组访问控制技术,用于限制对专有硬件和受版权保护的作品的使用。 -
x86:x86是一整套指令集体系结构,由 Intel 最初基于 Intel 8086 微处理器及其 8088 变体开发。采用内存分段作为解决方案,用于处理比普通 16 位地址可以覆盖的更多内存。32 位是 x86 默认的位数,除此之外,还有一个 x86-64 位,是x86架构的 64 位拓展,向后兼容于 16 位及 32 位的 x86架构。 -
FreeBSD:FreeBSD 是一个类 UNIX 的操作系统,也是 FreeBSD 项目的发展成果。 -
X Window System:X 窗口系统(X11,或简称X)是用于位图显示的窗口系统,在类 UNIX 操作系统上很常见。
Gnome:GNOME 是一个完全由自由软件组成的桌面环境。它的目标操作系统是Linux,但是大部分的 BSD 系统亦支持 GNOME。
网络操作系统(network operating systems):网络操作系统是用于网络设备(如路由器,交换机或防火墙)的专用操作系统。
分布式网络系统(distributed operating systems):分布式操作系统是在独立,网络,通信和物理上独立计算节点的集合上的软件。 它们处理由多个CPU服务的作业。每个单独的节点都拥有全局集合操作系统的特定软件的一部分。
-
程序计数器(Program counter):程序计数器 是一个 CPU 中的寄存器,用于指示计算机在其程序序列中的位置。 -
堆栈寄存器(stack pointer): 堆栈寄存器是计算机 CPU 中的寄存器,其目的是跟踪调用堆栈。 -
程序状态字(Program Status Word): 它是由操作系统维护的8个字节(或64位)长的数据的集合。它跟踪系统的当前状态。 -
流水线(Pipeline): 在计算世界中,管道是一组串联连接的数据处理元素,其中一个元素的输出是下一个元素的输入。 流水线的元素通常以并行或按时间分割的方式执行。 通常在元素之间插入一定数量的缓冲区存储。
超标量(superscalar): 超标量 CPU 架构是指在一颗处理器内核中实行了指令级并发的一类并发运算。这种技术能够在相同的CPU主频下实现更高的 CPU 流量。系统调用(system call): 指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。大多数系统交互式操作需求在内核态运行。如设备 IO 操作或者进程间通信。多线程(multithreading):是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因为有硬件支持而能够在同一时间执行多个线程,进而提升整体处理性能。CPU 核心(core):它是 CPU 的大脑,它接收指令,并执行计算或运算以满足这些指令。一个 CPU 可以有多个内核。图形处理器(Graphics Processing Unit):又称显示核心、视觉处理器、显示芯片或绘图芯片;它是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。
- 存储体系结构:顶层的存储器速度最高,但是容量最小,成本非常高,层级结构越向下,其访问效率越慢,容量越大,但是造价也就越便宜。
高速缓存行(cache lines):其实就是把高速缓存分割成了固定大小的块,其大小是以突发读或者突发写周期的大小为基础的。缓存命中(cache hit):当应用程序或软件请求数据时,会首先发生缓存命中。 首先,中央处理单元(CPU)在其最近的内存位置(通常是主缓存)中查找数据。 如果在缓存中找到请求的数据,则将其视为缓存命中。
-
L1 cache:一级缓存是 CPU 芯片中内置的存储库。 L1缓存也称为主缓存,是计算机中最快的内存,并且最接近处理器。 -
L2 cache: 二级缓存存储库,内置在 CPU 芯片中,包装在同一模块中,或者建在主板上。 L2 高速缓存提供给 L1 高速缓存,后者提供给处理器。 L2 内存比 L1 内存慢。 -
L2 cache: 三级缓存内置在主板上或CPU模块内的存储库。 L3 高速缓存为 L2 高速缓存提供数据,其内存通常比 L2 内存慢,但比主内存快。 L3 高速缓存提供给 L2 高速缓存,后者又提供给 L1 高速缓存,后者又提供给处理器。 -
RAM((Random Access Memory):随机存取存储器,也叫主存,是与 CPU直接交换数据的内部存储器。它可以随时读写,而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储介质。RAM工作时可以随时从任何一个指定的地址写入(存入)或读出(取出)信息。它与 ROM 的最大区别是数据的易失性,即一旦断电所存储的数据将随之丢失。RAM 在计算机和数字系统中用来暂时存储程序、数据和中间结果。 -
ROM (Read Only Memory):只读存储器是一种半导体存储器,其特性是一旦存储数据就无法改变或删除,且内容不会因为电源关闭而消失。在电子或电脑系统中,通常用以存储不需经常变更的程序或数据。 -
EEPROM (Electrically Erasable PROM):电可擦除可编程只读存储器,是一种可以通过电子方式多次复写的半导体存储设备。 -
闪存(flash memory): 是一种电子式可清除程序化只读存储器的形式,允许在操作中被多次擦或写的存储器。这种科技主要用于一般性数据存储,以及在电脑与其他数字产品间交换传输数据,如储存卡与U盘。 -
SSD(Solid State Disks):固态硬盘,是一种主要以闪存作为永久性存储器的电脑存储设备。
-
虚拟地址(virtual memory): 虚拟内存是计算机系统内存管理的一种机制。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。 -
MMU (Memory Management Unit):内存管理单元,有时称作分页内存管理单元。它是一种负责处理中央处理器(CPU)的内存访问请求的计算机硬件。它的功能包括虚拟地址到物理地址的转换(即虚拟内存管理)、内存保护、中央处理器高速缓存的控制等。 -
context switch:上下文切换,又称环境切换。是一个存储和重建 CPU 状态的机制。要交换 CPU 上的进程时,必需先行存储当前进程的状态,然后再将进程状态读回 CPU 中。 -
驱动程序(device driver):设备驱动程序,简称驱动程序(driver),是一个允许高级别电脑软件与硬件交互的程序,这种程序创建了一个硬件与硬件,或硬件与软件沟通的接口,经由主板上的总线或其它沟通子系统与硬件形成连接的机制,这样使得硬件设备上的数据交换成为可能。 -
忙等(busy waiting):在软件工程中,忙碌等待也称自旋,是一种以进程反复检查一个条件是否为真的条件,这种机制可能为检查键盘输入或某个锁是否可用。 -
中断(Interrupt):通常,在接收到来自外围硬件(相对于中央处理器和内存)的异步信号,或来自软件的同步信号之后,处理器将会进行相应的硬件/软件处理。发出这样的信号称为进行中断请求(interrupt request,IRQ)。硬件中断导致处理器通过一个运行信息切换(context switch)来保存执行状态(以程序计数器和程序状态字等寄存器信息为主);软件中断则通常作为 CPU 指令集中的一个指令,以可编程的方式直接指示这种运行信息切换,并将处理导向一段中断处理代码。中断在计算机多任务处理,尤其是即时系统中尤为有用。 -
中断向量(interrupt vector):中断向量位于中断向量表中。中断向量表(IVT)是将中断处理程序列表与中断向量表中的中断请求列表相关联的数据结构。 中断向量表的每个条目(称为中断向量)都是中断处理程序的地址。 -
DMA (Direct Memory Access):直接内存访问,直接内存访问是计算机科学中的一种内存访问技术。它允许某些电脑内部的硬件子系统(电脑外设),可以独立地直接读写系统内存,而不需中央处理器(CPU)介入处理 。 -
总线(Bus):总线(Bus)是指计算机组件间规范化的交换数据的方式,即以一种通用的方式为各组件提供数据传送和控制逻辑。 -
PCIe (Peripheral Component Interconnect Express):官方简称PCIe,是计算机总线的一个重要分支,它沿用现有的PCI编程概念及信号标准,并且构建了更加高速的串行通信系统标准。 -
DMI (Direct Media Interface):直接媒体接口,是英特尔专用的总线,用于电脑主板上南桥芯片和北桥芯片之间的连接。 -
USB(Universal Serial Bus):是连接计算机系统与外部设备的一种串口总线标准,也是一种输入输出接口的技术规范,被广泛地应用于个人电脑和移动设备等信息通讯产品,并扩展至摄影器材、数字电视(机顶盒)、游戏机等其它相关领域。
-
BIOS(Basic Input Output System):是在通电引导阶段运行硬件初始化,以及为操作系统提供运行时服务的固件。它是开机时运行的第一个软件。 -
硬实时系统(hard real-time system):硬实时性意味着你必须绝对在每个截止日期前完成任务。 很少有系统有此要求。 例如核系统,一些医疗应用(例如起搏器),大量国防应用,航空电子设备等。 -
软实时系统(soft real-time system):软实时系统可能会错过某些截止日期,但是如果错过太多,最终性能将下降。 一个很好的例子是计算机中的声音系统。 -
进程(Process):程序本身只是指令、数据及其组织形式的描述,进程才是程序(那些指令和数据)的真正运行实例。若进程有可能与同一个程序相关系,且每个进程皆可以同步(循序)或异步的方式独立运行。 -
地址空间(address space):地址空间是内存中可供程序或进程使用的有效地址范围。 也就是说,它是程序或进程可以访问的内存。 存储器可以是物理的也可以是虚拟的,用于执行指令和存储数据。 -
进程表(process table):进程表是操作系统维护的数据结构,该表中的每个条目(通常称为上下文块)均包含有关进程的信息,例如进程名称和状态,优先级,寄存器以及它可能正在等待的信号灯。 -
命令行界面(command-line interpreter):是在图形用户界面得到普及之前使用最为广泛的用户界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后,予以执行。
进程间通信(interprocess communication): 指至少两个进程或线程间传送数据或信号的一些技术或方法。超级用户(superuser): 也被称为管理员帐户,在计算机操作系统领域中指一种用于进行系统管理的特殊用户,其在系统中的实际名称也因系统而异,如 root、administrator 与supervisor。目录(directory): 在计算机或相关设备中,一个目录或文件夹就是一个装有数字文件系统的虚拟容器。在它里面保存着一组文件和其它一些目录。路径(path name): 路径是一种电脑文件或目录的名称的通用表现形式,它指向文件系统上的一个唯一位置。根目录(root directory):根目录指的就是计算机系统中的顶层目录,比如 Windows 中的 C 盘和 D 盘,Linux 中的/。工作目录(Working directory):它是一个计算机用语。用户在操作系统内所在的目录,用户可在此目录之下,用相对文件名访问文件。文件描述符(file descriptor): 文件描述符是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。inode:索引节点的缩写,索引节点是 UNIX 系统中包含的信息,其中包含有关每个文件的详细信息,例如节点,所有者,文件,文件位置等。共享库(shared library):共享库是一个包含目标代码的文件,执行过程中多个 a.out 文件可能会同时使用该目标代码。DLLs (Dynamic-Link Libraries):动态链接库,它是微软公司在操作系统中实现共享函数库概念的一种实现方式。这些库函数的扩展名是 .DLL、.OCX(包含ActiveX控制的库)或者.DRV(旧式的系统驱动程序)。客户端(clients):客户端是访问服务器提供的服务的计算机硬件或软件。服务端(servers): 在计算中,服务器是为其他程序或设备提供功能的计算机程序或设备,称为服务端主从架构(client-server): 主从式架构也称客户端/服务器架构、C/S架构,是一种网络架构,它把客户端与服务器区分开来。每一个客户端软件的实例都可以向一个服务器或应用程序服务器发出请求。有很多不同类型的服务器,例如文件服务器、游戏服务器等。
-
虚拟机(Virtual Machines):在计算机科学中的体系结构里,是指一种特殊的软件,可以在计算机平台和终端用户之间创建一种环境,而终端用户则是基于虚拟机这个软件所创建的环境来操作其它软件。 -
Java 虚拟机(Jaav virtual Machines):Java虚拟机有自己完善的硬体架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。JVM屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。 -
目标文件(object file):目标文件是包含目标代码的文件,这意味着通常无法直接执行的可重定位格式的机器代码。 目标文件有多种格式,相同的目标代码可以打包在不同的目标文件中。 目标文件也可以像共享库一样工作。 -
C preprocessor: C 预处理å器是 C 语言、C++ 语言的预处理器。用于在编译器处理程序之前预扫描源代码,完成头文件的包含, 宏扩展, 条件编译, 行控制等操作。 -
设备控制器(device controller): 设备控制器是处理 CPU 传入信号和传出信号的系统。设备通过插头和插座连接到计算机,并且插座连接到设备控制器。 -
ECC(Error-Correcting Code): 指能够实现错误检查和纠正错误技术的内存。 -
I/O port: 也被称为输入/输出端口,它是由软件用来与计算机上的硬件进行通信的内存地址。 -
内存映射I/O(memory mapped I/O,MMIO): 内存映射的 I/O 使用相同的地址空间来寻址内存和 I/O 设备,也就是说,内存映射I/O 设备共享同一内存地址。 -
端口映射I/O(Port-mapped I/O ,PMIO):在 PMIO中,内存和I/O设备有各自的地址空间。 端口映射I/O通常使用一种特殊的CPU指令,专门执行I/O操作。 -
DMA (Direct Memory Access): 直接内存访问,它是计算机系统的一项功能,它允许某些硬件系统能够独立于 CPU 访问内存。如果没有 DMA,当 CPU 执行输入/输出指令时,它通常在读取或写入操作的整个过程中都被完全占用,因此无法执行其他工作。使用 DMA 后,CPU 首先启动传输信号,然后在进行传输时执行其他操作,最后在完成操作后从 DMA 控制器(DMAC)接收中断。完成执行。
-
周期窃取(cycle stealing):许多总线能够以两种模式操作:每次一字模式和块模式。一些 DMA 控制器也能够使用这两种方式进行操作。在前一个模式中,DMA 控制器请求传送一个字并得到这个字。如果 CPU 想要使用总线,它必须进行等待。设备可能会偷偷进入并且从 CPU 偷走一个总线周期,从而轻微的延迟 CPU。它类似于直接内存访问(DMA),允许I / O控制器在无需 CPU 干预的情况下读取或写入RAM。 -
突发模式(burst mode): 指的是设备在不进行单独事务中重复传输每个数据所需的所有步骤的情况下,重复传输数据的情况。 -
中断向量表(interrupt vector table): 用来形成相应的中断服务程序的入口地址或存放中断服务程序的首地址称为中断向量。 中断向量表是中断向量的集合,中断向量是中断处理程序的地址。 -
精确中断(precise interrupt):精确中断是一种能够使机器处于良好状态下的中断,它具有如下特征
- PC (程序计数器)保存在一个已知的地方
- PC 所指向的指令之前所有的指令已经完全执行
- PC 所指向的指令之后所有的指令都没有执行
- PC 所指向的指令的执行状态是已知的
非精确中断(imprecise interrupt):不满足以上要求的中断,指令的执行时序和完成度具有不确定性,而且恢复起来也非常麻烦。设备独立性(device independence):我们编写访问任何设备的应用程序,不用事先指定特定的设备。比如你编写了一个能够从设备读入文件的应用程序,那么这个应用程序可以从硬盘、DVD 或者 USB 进行读入,不必再为每个设备定制应用程序。这其实就体现了设备独立性的概念。
UNC(Uniform Naming Convention):UNC 是统一命名约定或统一命名约定的缩写,是用于命名和访问网络资源(例如网络驱动器,打印机或服务器)的标准。 例如,在 MS-DOS 和 Microsoft Windows 中,用户可以通过键入或映射到类似于以下示例的共享名来访问共享资源。
\\computer\path
复制代码然而,在 UNIX 和 Linux 中,你会像如下这么写
//computer/path
复制代码挂载(mounting):挂载是指操作系统会让存储在硬盘、CD-ROM 等资源设备上的目录和文件,通过文件系统能够让用户访问的过程。错误处理(Error handling): 错误处理是指对软件应用程序中存在的错误情况的响应和恢复过程。同步阻塞(synchronous): 同步是阻塞式的,CPU 必须等待同步的处理结果。异步响应(asynchronous): 异步是由中断驱动的,CPU 不用等待每个操作的处理结果继而执行其他操作缓冲区(buffering): 缓冲区是内存的临时存储区域,它的出现是为了加快内存的访问速度而设计的。对于经常访问的数据和指令来说,CPU 应该访问的是缓冲区而非内存Programmed input–output,PIO:它指的是在 CPU 和外围设备(例如网络适配器或 ATA 存储设备)之间传输数据的一种方法。轮询(polling): 轮询是指通过客户端程序主动通过对每个设备进行访问来获得同步状态的过程。
忙等(busy waiting):当一个进程正处在某临界区内,任何试图进入其临界区的进程都必须等待,陷入忙等状态。连续测试一个变量直到某个值出现为止,称为忙等。可重入(reentrant): 如果一段程序或者代码在任意时刻被中断后由操作系统调用其他程序或者代码,这段代码调用子程序并能够正确运行,这种现象就称为可重入。也就是说当该子程序正在运行时,执行线程可以再次进入并执行它,仍然获得符合设计时预期的结果。主设备编号(major device number)、副设备编号(minor device number): 所有设备都有一个主,副号码。 主号码是更大,更通用的类别(例如硬盘,输入/输出设备等),而次号码则更具体(即告诉设备连接到哪条总线)。多重缓冲区(double buffering): 它指的是使用多个缓冲区来保存数据块,每个缓冲区都保留数据块的一部分,读取的时候通过读取多个缓冲区的数据进而拼凑成一个完整的数据。环形缓冲区(circular buffer): 它指的是首尾相连的缓冲区,常用来实现数据缓冲流。
假脱机(Spooling):假脱机是多程序的一种特殊形式,目的是在不同设备之间复制数据。 在现代系统中,通常用于计算机应用程序和慢速外围设备(例如打印机)之间的中介。守护进程(Daemon): 在计算机中,守护程序是作为后台进程运行的计算机程序,而不是在交互式用户的直接控制下运行的程序。逻辑块寻址(logical block addressing, LBA):逻辑块寻址是一种通用方案,用于指定存储在计算机存储设备上的数据块的位置。RAID:全称是 Redundant Array of Inexpensive Disks ,廉价磁盘或驱动器的冗余阵列,它是一种数据存储虚拟化的技术,将多个物理磁盘驱动器组件组合成一个或多个逻辑单元,以实现数据冗余,改善性能。
MBR(Master Boot Record):主引导记录(MBR)是任何硬盘或软盘的第一扇区中的信息,用于标识操作系统的放置方式和位置,以便可以将其加载到计算机的主存储器或随机存取存储器中。
FCFS (First-Come, First-Served): 先进先出的调度算法,也就是说,首先到达 CPU 的进程首先进行服务。SSF (Shortest Seek First)最短路径优先算法,这是对先进先出算法的改进,这种算法因为减少了总的磁臂运动,从而缩短了平均响应时间。稳定存储(stable storage): 它是计算机存储技术的一种分类,该技术可确保任何给定的写操作都具有原子性。时钟(Clocks):也被称为 timers。通常,时钟是指调节所有计算机功能的时序和速度的微芯片。芯片中是一个晶体,当通电时,晶体会以特定的频率振动。 任何一台计算机能够执行的最短时间是一个时钟或时钟芯片的一次振动。QR Code: 二维码的一种,它的全称是快速响应矩阵图码,能够快速响应。一般应用于手机读码操作,国内火车票上的二维码就是 QR 码
显卡(Video card),是个人电脑最基本组成部分之一,用途是将计算机系统所需要的显示信息进行转换驱动显示器,并向显示器提供逐行或隔行扫描信号,控制显示器的正确显示,是连接显示器和个人电脑主板的重要组件,是人机对话的重要设备之一。
GDI (Graphics Device Interface):图形接口,是微软视窗系统提供的应用程序接口,也是其用来表征图形对象、将图形对象传送给诸如显示器、打印机之类输出设备的核心组件。设备上下文(device context):设备上下文是 Windows 数据结构,其中包含有关设备(例如显示器或打印机)的图形属性的信息。 所有绘图调用都是通过设备上下文对象进行的,该对象封装了用于绘制线条,形状和文本的 Windows API。 设备上下文可用于绘制到屏幕,打印机或图元文件。位图(bitmap):在计算机中,位图是从某个域(例如,整数范围)到位的映射。也称为位数组或位图索引。电阻式触摸屏(Resistive touchscreens):电阻式触摸屏基于施加到屏幕上的压力来工作。 电阻屏由许多层组成。 当按下屏幕时,外部的后面板将被推到下一层,下一层会感觉到施加了压力并记录了输入。 电阻式触摸屏用途广泛,可以用手指,指甲,手写笔或任何其他物体进行操作。
电容式触摸屏(capacitive touchscreen):电容式触摸屏通过感应物体(通常是指尖上的皮肤)的导电特性来工作。 手机或智能手机上的电容屏通常具有玻璃表面,并且不依赖压力。 当涉及到手势(如滑动和捏合)时,它比电阻式屏幕更具响应性。 电容式触摸屏只能用手指触摸,而不能用普通的手写笔,手套或大多数其他物体来响应。
死锁(deadlock):死锁常用于并发情况下,死锁是一种状态,死锁中的每个成员都在等待另一个成员(包括其自身)采取行动。
相信你一定看过这个图
可抢占资源(preemptable resource):可以从拥有它的进程中抢占而并不会产生任何副作用。不可抢占资源(nonpreemptable resource):与可抢占资源相反,如果资源被抢占后,会导致进程或任务出错。系统检查点(system checkpointed):系统检查点是操作系统(OS)的可启动实例。检查点是计算机在特定时间点的快照。两阶段加锁(two-phase locking, 2PL):经常用于数据库的并发控制,以保证可串行化
这种方法使用数据库锁在两个阶段:
-
扩张阶段:不断上锁,没有锁被释放
-
收缩阶段:锁被陆续释放,没有新的加锁
-
活锁(Livelock):活锁类似于死锁,不同之处在于,活锁中仅涉及进程的状态彼此之间不断变化,没有进展。举一个现实世界的例子,当两个人在狭窄的走廊里相遇时,就会发生活锁,每个人都试图通过移动到一边让对方通过而礼貌,但最终却没有任何进展就左右摇摆,因为他们总是同时移动相同的方式。 -
饥饿(starvation):在死锁或者活锁的状态中,在任何时刻都可能请求资源,虽然一些调度策略能够决定一些进程在某一时刻获得资源,但是有一些进程永远无法获得资源。永远无法获得资源的进程很容易产生饥饿。 -
沙盒(sandboxing):沙盒是一种软件管理策略,可将应用程序与关键系统资源和其他程序隔离。它提供了一层额外的安全保护,可防止恶意软件或有害应用程序对你的系统造成负面影响。 -
VMM (Virtual Machine Monitor):也被称为 hypervisor,在同一个物理机器上创建出来多态虚拟机器的假象。
-
虚拟化技术(virtualization): 是一种资源管理技术,将计算机的各种实体资源(CPU、内存、磁盘空间、网络适配器等),进行抽象、转换后呈现出来并可供分割、组合为一个或多个电脑配置环境。 -
云(cloud):云是目前虚拟机最重要、最时髦的玩法。 -
解释器(interpreter): 解释器是一种程序,能够把编程语言一行一行解释运行。每次运行程序时都要先转成另一种语言再运行,因此解释器的程序运行速度比较缓慢。它不会一次把整个程序翻译出来,而是每翻译一行程序叙述就立刻运行,然后再翻译下一行,再运行,如此不停地进行下去。 -
半虚拟化(paravirtualization): 半虚拟化的目的不是呈现出一个和底层硬件一摸一样的虚拟机,而是提供一个软件接口,软件接口与硬件接口相似但又不完全一样。 -
全虚拟化(full virtualization):全虚拟化是硬件虚拟化的一种,允许未经修改的客操作系统隔离运行。对于全虚拟化,硬件特征会被映射到虚拟机上,这些特征包括完整的指令集、I/O操作、中断和内存管理等。 -
客户操作系统(guest operating system): 客户操作系统是安装在计算机上操作系统之后的操作系统,客户操作系统既可以是分区系统的一部分,也可以是虚拟机设置的一部分。客户操作系统为设备提供了备用操作系统。 -
主机操作系统(host operating system): 主机操作系统是计算机系统的硬盘驱动器上安装的主要操作系统。 在大多数情况下,只有一个主机操作系统。 -
应用编程接口(Application Programming Interface,API):应用程序编程接口(API)是软件组件或系统的编程接口,它定义其他组件或系统如何使用它。 -
虚拟机接口(Virtual Machine Interface, VMI):它是一个高速接口,同一主机上的虚拟机(VM)可用于相互之间以及主机内核模块之间进行通信。 -
输入输出内存管理单元(Input–output memory management unit, I/O MMU):在计算机中,输入输出内存管理单元(IOMMU)是将直接内存访问(DMA)I / O 总线连接到主存的内存管理单元(MMU)。 -
设备穿透(device pass through):它允许将物理设备直接分配给特定虚拟机。 -
设备隔离(device isolation): 保证设备可以直接访问其分配到的虚拟机的内存而不影响其他虚拟机的完整性。 -
基础设施即服务(IAAS (Infrastructure As A Service)):基础架构即服务(IaaS)是一种即时计算基础架构,可通过 Internet 进行配置和管理。 它是四种云服务类型之一,另外还有软件即服务(SaaS),平台即服务(PaaS)和无服务器。
平台即服务(PAAS (Platform As A Service)):平台即服务(PaaS)或应用程序平台即服务(aPaaS)或基于平台的服务是云计算服务的一种,它提供了一个平台,使客户可以开发,运行和管理应用程序,而无需构建和维护该应用程序。
软件即服务(SAAS(Software As A Service)): 它是一个提供特定软件服务访问的平台,是一种软件许可和交付模型,在该模型中,软件是基于订阅许可的,并且是集中托管的。
实时迁移(live migration): 实时迁移是指在不断开客户端或应用程序连接的情况下,在不同的物理机之间移动正在运行的虚拟机或应用程序的过程,一般经常采用的方式是内存预复制迁移写入时复制(copy on write):写入时复制是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变主从模型(master-slave):主/从是一种不对称通信或控制的模型,其中一个设备进程控制一个或多个其他设备或进程并充当其通信中心。 在某些系统中,从一组合格的设备中选择一个主设备,而其他设备则充当从设备的角色。
-
分布式系统(distributed system):分布式系统,也称为分布式计算,是一种具有位于不同机器上的多个组件的系统,这些组件可以通信和协调动作,以便对最终用户显示为单个一致的系统。 -
局域网(LANs, Local Area Networks):局域网(LAN)是一种计算机网络,可将住宅,学校,实验室,大学校园或办公大楼等有限区域内的计算机互连。 -
广域网(WAN,Wide Area Network):又称广域网、外网、公网。是连接不同地区局域网或城域网计算机通信的远程网。通常跨接很大的物理范围,所覆盖的范围从几十公里到几千公里,它能连接多个地区、城市和国家,或横跨几个洲并能提供远距离通信,形成国际性的远程网络。 -
以太网(Ethernet):以太网是一种计算机局域网的技术,它规定了包括物理层的连线、电子信号和介质访问层协议的内容。 -
桥接器(bridge):当指代计算机时,网桥是连接两个 LAN(局域网)或同一 LAN 的两个网段的设备。与路由器不同,网桥是独立于协议的。他们转发数据包时无需分析和重新路由消息。
主机(host):在网络硬件中,主机又被称为网络主机,网络主机是连接到计算机网络的计算机或其他设备。主机可以充当服务器,向网络上的用户或其他主机提供信息资源,服务和应用程序。主机被分配至少一个网络地址。路由器(router):路由器是在计算机网络之间转发数据包的联网设备。通过互联网发送的数据(例如网页或电子邮件)以数据包的形式出现。面向连接的服务(Connection-oriented service):面向连接的服务是一种在数据通信开始之前在通信实体之间建立专用连接的服务。要使用面向连接的服务,用户首先建立一个连接,使用它,然后释放它。TCP 就是一种面向连接的服务,在发送数据包之前需要经过握手操作。无连接的服务(Connectionless service):无连接服务是两个节点之间的数据通信,其中发送方在不确保接收方是否可以接收数据的情况下发送数据。此处,每个数据包都具有目标地址,并且与其他数据包无关地独立路由。UDP 就是一种无连接的服务,发送数据包不需要经过握手连接。服务质量(quality of service, QoS):服务质量是对服务整体性能的描述或度量,尤其是网络用户看到的性能。确认包(acknowledgement packet):在数据网络,电信和计算机总线中,确认(ACK)是作为通信协议一部分在通信过程,计算机或设备之间传递以表示确认或消息接收的信号。请求-响应服务(request-reply service):请求-响应是计算机彼此通信的基本方法之一,其中第一台计算机发送对某些数据的请求,第二台计算机对请求进行响应。
协议栈(protocol stack):所有现代网络都使用所谓的协议栈把不同的协议一层一层叠加起来。每一层解决不同的问题。
IP地址:标示互联网上每一台主机有两种方式,一种是 IPv4 ,一种是 IPv6。超链接(hyperlink):超链接是可以单击以跳到新文档或当前文档中新部分的单词,短语或图像。 几乎在所有网页中都可以找到超链接,从而允许用户单击页面之间的方式。 文本超链接通常为蓝色并带有下划线。Web 页面(Web page):网页是一个适用于万维网和网页浏览器的文件。Web浏览器:Web浏览器(通常称为浏览器)是一种用于访问 Internet 上的信息的软件应用程序。 当用户请求特定网站时,Web 浏览器从 Web 服务器检索必要的内容,然后在用户的设备上显示结果网页。漏洞(vulnerability):漏洞是一种系统不安全级别的错误。漏洞利用(exploit):漏洞利用是计算机安全术语,指的是利用程序中的某些漏洞,来得到计算机的控制权。病毒(virus):计算机病毒是一种计算机程序,在执行时会通过修改其他计算机程序并插入自己的代码来自我复制。复制成功后,可以说受影响的区域已被计算机病毒感染。
CIA(Confidentiality,Integrity,Availability):安全系统的三个指标,即机密性、完整性和可用性。黑客(cracker):黑客是指经常通过网络闯入他人计算机系统的人。 绕过计算机程序中的密码或许可证; 或以其他方式故意破坏计算机安全性。 黑客可能会出于恶意,出于某些利他目的或原因,或者是因为存在挑战而牟取暴利。 表面上已经进行了一些破解和输入,以指出站点安全系统中的弱点。端口扫描(portscan):端口扫描程序是一种旨在探测服务器或主机是否存在开放端口的应用程序。 管理员可以使用这种应用程序来验证其网络的安全策略,攻击者可以使用这种应用程序来识别主机上运行的网络服务并利用漏洞。僵尸网络(botnets):僵尸网络是指骇客利用自己编写的分布式拒绝服务攻击程序将数万个沦陷的机器,即骇客常说的傀儡机或肉鸡。域(domain):网域名称,简称域名、网域,是由一串用点分隔的字符组成的互联网上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位。
盐(salt):在密码学中,盐是随机数据,用作哈希数据,密码或密码的单向函数的附加输入。逻辑炸弹(logic bomb): 是一些嵌入在正常软件中并在特定情况下执行的恶意程式码。这些特定情况包括更改档案、特别的程式输入序列、特定的时间或日期等。恶意程式码可能会将档案删除、使电脑主机当机或是造成其他的损害。定时炸弹(time bomb):在计算机软件中,定时炸弹是已编写的计算机程序的一部分,因此它会在达到预定的日期或时间后开始或停止运行。登陆欺骗(login spoofing):登录欺骗是用于窃取用户密码的技术。它会向用户显示一个普通的登录提示,提示用户名和密码,这实际上是一个恶意程序,通常在攻击者的控制下称为特洛伊木马。后门程序(backdoor):软件后门指绕过软件的安全性控制,从比较隐秘的通道获取对程序或系统访问权的黑客方法。防火墙(firewall):防火墙在计算机科学领域中是一个架设在互联网与企业内网之间的信息安全系统,根据企业预定的策略来监控往来的传输。
存储系统——基本概念
现代计算机结构
存储器的层次化结构
存储器的各个层次结构图: 注意:辅存中的数据要调入主存后才能被CPU访问
*cache读音如下:fanyi.baidu.com/?aldtype=85…
关系间解决的问题
- 主存—辅存:实现虚拟存储系统,解决了主存容量不够的问题
- Cache—主存:解决了主存与CPU速度不匹配的问题
各层存储器速度容量价格对比
注:有的教材把安装在电脑内部的磁盘称为“辅存”,把U盘、光盘等称为“外存”。 也有的教材把磁盘、U盘、光盘等统称为“辅存”或“外存”
存储器的分类
层次
按层次对存储器进行划分
介质
按存储介质分类
1.半导体存储器(以半导体器件存储信息) (主存、Cache)
2.磁表面存储器:磁盘、磁带(以磁性材料存储信息)
3.光存储器(以磁性材料存储信息)
存取方式
-
相联存储器(Associative Memory),即可以按内容访问的存储器(ContentAddressed Memory,CAM)可以按照内容检索到存储位置进行读写,“快表”就是一种相联存储器
-
随机存取存储器(RandomAccess Memory, RAM):读写任何一个存储单元所需时间都相同,与存储单元所在的物理位置无关
-
顺序存取存储器(SequentialAccess Memory, SAM):读写一个存储单元所需时间取决于存储单元所在的物理位置
-
直接存取存储器(DirectAccessMemory,DAM):既有随机存取特性,也有顺序存取特性。先直接选取信息所在区域,然后按顺序方式存取。
-
串行访问存储器:读写某个存储单元所需时间与存储单元的物理位置有关
信息的可更改性
- 读写存储器(Read/Write Memory)——即可读、也可写(如:磁盘、内存、Cache)
- 只读存储器(Read Only Memory)——只能读,不能写(如:实体音乐专辑通常采用 CD-ROM,实体电影采用蓝光光碟,BIOS通常写在ROM中)==事实上很多ROM也可多次读写,只是比较麻烦。==
信息的可保存性
-
断电后,存储信息消失的存储器——==易失性存储器==(主存、Cache)
-
断电后,存储信息依然保持的存储器——==非易失性存储器==(磁盘、光盘)
- 信息读出后,原存储信息被破坏——破坏性读出(如DRAM芯片,读出数据后要进行重写)
- 信息读出后,原存储信息不被破坏——非破坏性读出(如SRAM芯片、磁盘、光盘)
存储器的性能指标
- 存储容量:存储字数×字长(如1M×8位)。==(MDR位数反 映存储字长)==
- 单位成本:每位价格=总成本/总容量。
- 存储速度:数据传输率=数据的宽度/存储周期。==(数据的宽度即存储字长)==、==(主存带宽(Bm)==:主存带宽又称==数据传输率==,表示每秒从主存进出信息的最大数量,单位为字/秒、字节/秒(B/s)或位/秒(b/s)。)
存储时间,存储周期:
① ==存取时间(Ta)==:存取时间是指从启动一次存储器操作到完成该操作所经历的时间,分为读出时间和写入时间。 ②==存取周期(Tm)==:存取周期又称为读写周期或访问周期。它是指存储器进行一次完整的读写操作所需的全部时间,即连续两次独立地访问存储器操作(读或写操作)之间所需的最小时间间隔。
如下图是一个存储时间与存储周期的关系图:
数据存储
数据存储是对数字信息(隐匿在应用、网络协议、文档、媒体、通讯录、用户首选项等背后的位和字节)的实际收集和留存。数据存储是大数据的核心环节。
举例来说,计算机就像大脑一样。两者都有短期记忆和长期记忆。大脑通过前额叶皮层来处理短期记忆,而计算机则利用随机存取存储器(RAM)来处理短期记忆。
大脑和 RAM 都要在清醒的状态下处理并记住事务,并且在工作一会儿后会感到疲倦。大脑在睡眠时会将工作记忆转换为长期记忆,而计算机则在睡眠时将活动记忆转换为存储卷。计算机还会按类型来分配数据,就像大脑按语义、空间、情感或规程来分配记忆一样。
挂载
挂载(mounting)是指由操作系统使一个存储设备(诸如硬盘、CD-ROM或共享资源)上的计算机文件和目录可供用户通过计算机的文件系统访问的一个过程。
挂载条件
系统格式
挂载命令
示例
分区
Linux 下分区标识
- y 这个字母标明分区所在的设备
-
- /dev/hda(第一个 IDE 磁盘)
- /dev/sdb(第二个 SCSI 磁盘)
-
- N 这个数字代表分区的编号
增加 /home容量
Linux系统把/home重新挂载到其他硬盘或分区
一开始没有做好规划,导致/home空间不足,再加上分区表不是GPT,导致无法扩展超过2T,因此需要重新划分一块更大的硬盘给/home。
1.把新挂载的4T硬盘进行分区和格式化
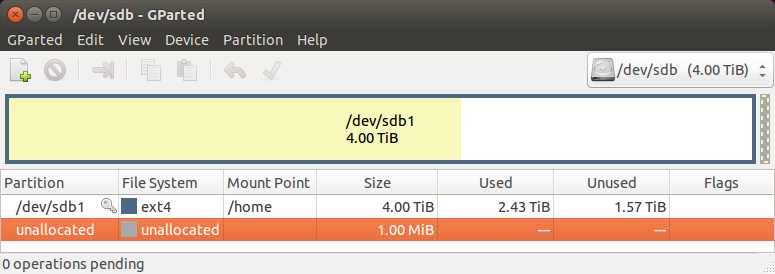
2.创建目录
sudo mkdir /media/home
3.把/dev/sdb1挂载到/media/home
sudo mount /dev/sdb1 /media/home
4.同步/home到/media/home,同步时间根据数据量大小决定,建议在系统空闲时操作
sudo rsync -aXS /home/. /media/home/.
5.同步完成后重命名/home
sudo mv /home /home_old
6.新建/home
sudo mkdir /home
7.取消/dev/sdb1挂载
sudo umount /dev/sdb1
8.重新挂载/dev/sdb1到home
sudo mount /dev/sdb1 /home
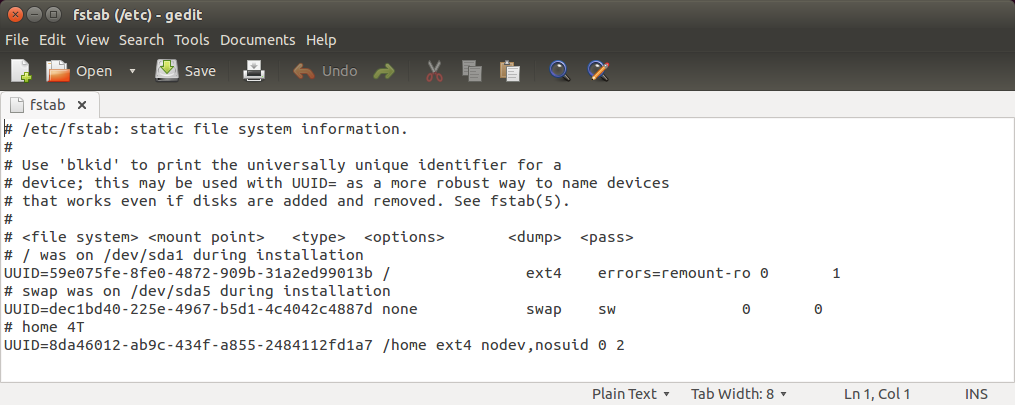
9.查看/dev/sdb1的UUID
blkid

10.把UUID复制下来,修改/etc/fstab文件,实现开机自动挂载
sudo gedit /etc/fstab
在文件最后添加如下内容:
# home 4T
UUID=8da46012-ab9c-434f-a855-2484112fd1a7 /home ext4 nodev,nosuid 0 2
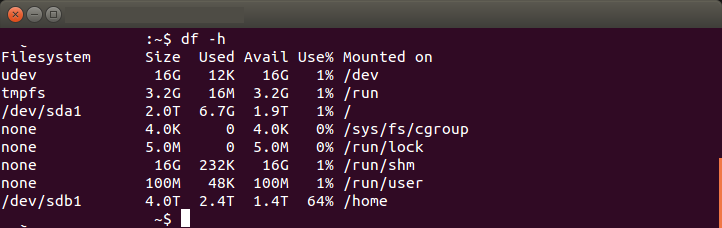
11.保存之后重启系统,查看分区的挂载情况
df –h
12.确认一切正常后删除/home_old
sudo rm -rf /home_old
至此,给/home增加空间的工作就完成了。
Node.js
是一使用 Chrome JavaScript runtime 所建立的网络应用程序。Node.js 使用事件驱动设计与非阻塞 I\/O 模块使其更轻量化且有效率。适用于实时高密度数据应用程序。
Apache HTTP Server
是开源的 HTTP 服务器用以架设网站,目标是提供一个安全,高效且可扩展的服务器,此服务器可以提供与当前 HTTP 标准同步的 HTTP 服务。\nApache HTTP 服务器 2.4.43 版本才能与 OpenSSL 1.1.1 进行安全连接。您可以在 Web Center 中选择 Apache 作为后端网站服务器。
Python
是一个非常强大的动态程序语言,用于各种各样的应用。 Python经常与TCL,Perl,Ruby,Scheme 或Java相提并论。它让你的工作更迅速,整合系统更有效。你可以使用Python来看到生产力和更低维护成本的立即效果。
PHP
是一种专为网站开发设计的通用脚本语言。安装 PHP 7 后,ADM 的默认 PHP 版本将会连结到 PHP 7。下载并安装 PHP 7 以在 NAS 上使用更安全的动态网页及网站服务器。 PHP 可让您快速安全的架设博客、论坛或其他受欢迎的内容管理系统网站。
设备
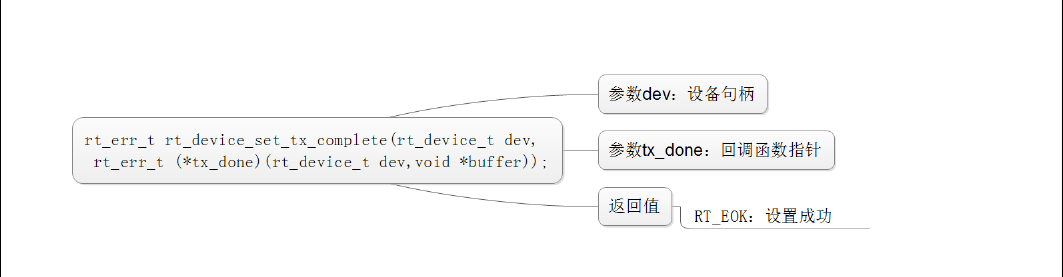
RTT内核对象——设备
RT-Thread有多种内核对象,其中设备device就是其中一种。
内核继承关系图如下:
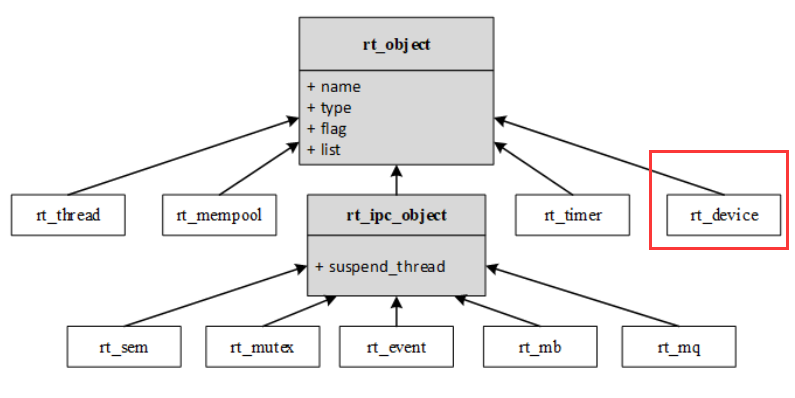
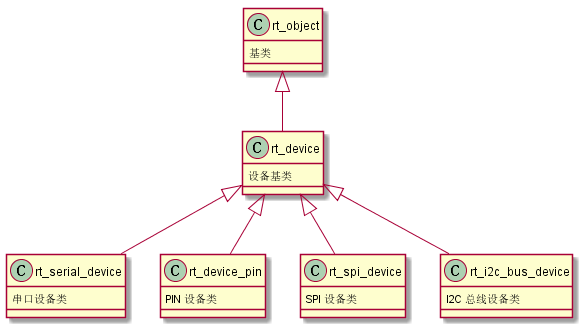
设备继承关系图如下:
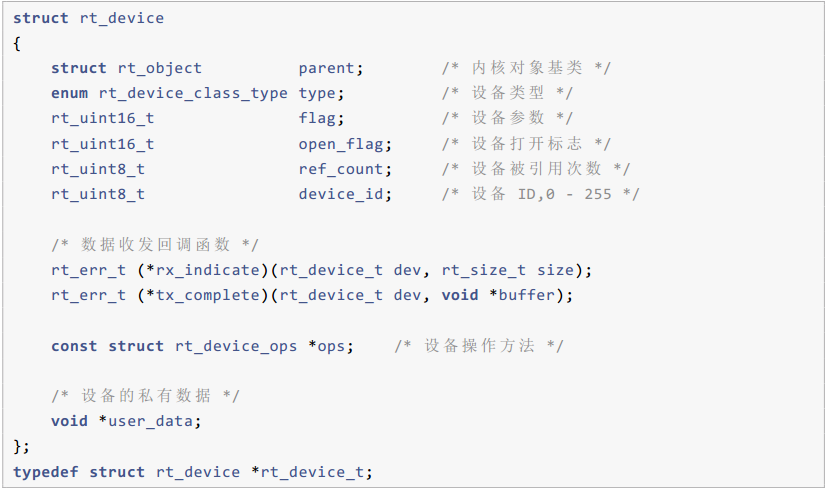
device对象对应的结构体如下:
其中,设备类型type有如下几类:

设备的操作方法结构体:

I/O设备模型框架
RT-Thread 提供了一套简单的 I/O 设备模型框架 :
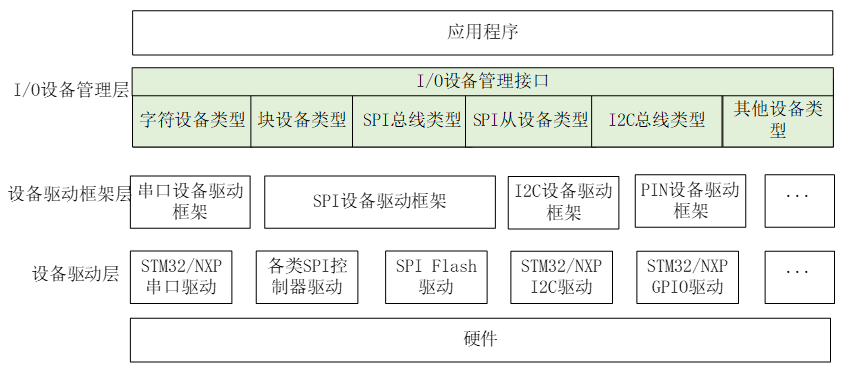
应用程序通过 I/O 设备管理接口获得正确的设备驱动,然后通过这个设备驱动与底层 I/O 硬件设备进行数据(或控制)交互。
I/O 设备管理层:实现了对设备驱动程序的封装。 设备驱动程序的升级、更替不会对上层应用产生影响, 从而降低了代码的耦合性、复杂性,提高了系统的可靠性。
设备驱动框架层: 对同类硬件设备驱动的抽象, 将不同厂家的同类硬件设备驱动中相同的部分抽取出来。
设备驱动层: 是一组驱使硬件设备工作的程序,实现访问硬件设备的功能。 这一层是与硬件有关的,不同的芯片的同种外设驱动是不同的,STM32的GPIO驱动与NXP的GPIO驱动是不同的。这一层负责创建与注册I/O设备,对于操作逻辑简单的设备,可以不经过设备驱动框架层。
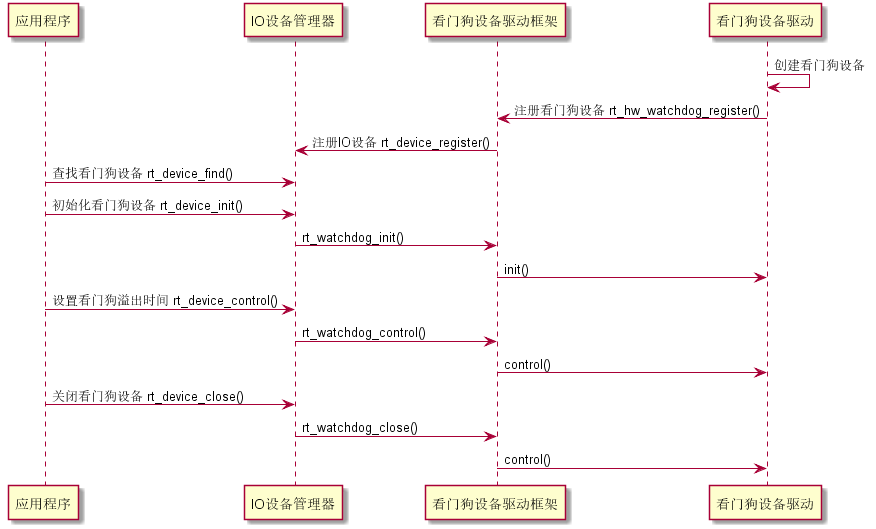
设备的两种注册方式
1、 对于操作逻辑简单的设备,可以不经过设备驱动框架层,直接将设备注册到 I/O 设备管理器中:
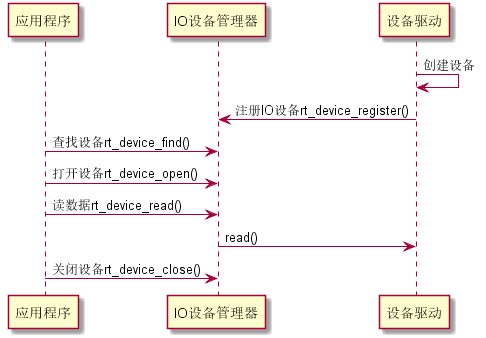
2、 对于另一些设备,如看门狗等,则会将创建的设备实例先注册到对应的设备驱动框架中,再由设备驱动框架向 I/O 设备管理器进行注册 :
I/O设备接口
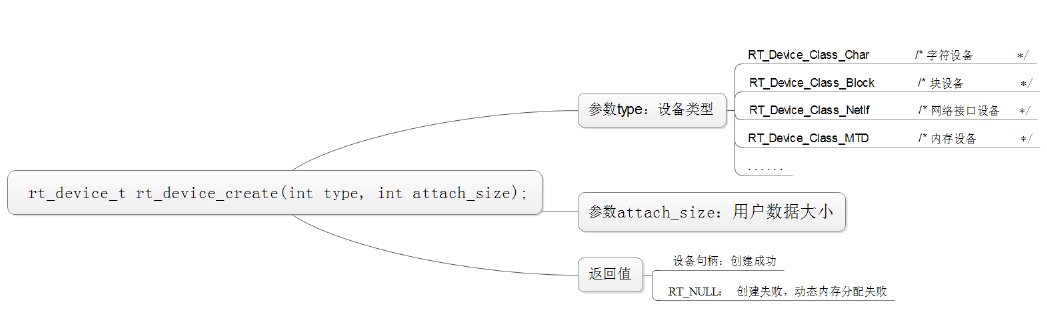
1、创建及注册I/O设备
设备创建:
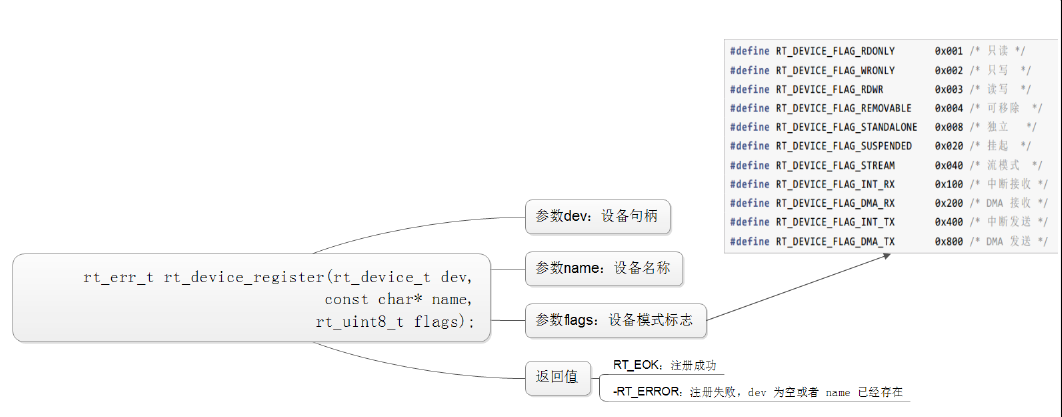
设备注册:
2、访问I/O设备
应用程序通过 I/O 设备管理接口来访问硬件设备,当设备驱动实现后,应用程序就可以访问该硬件。 I/O 设备管理接口与 I/O 设备的操作方法的映射关系下图所示:
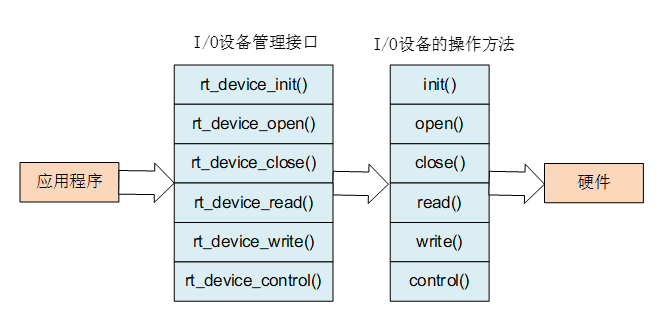
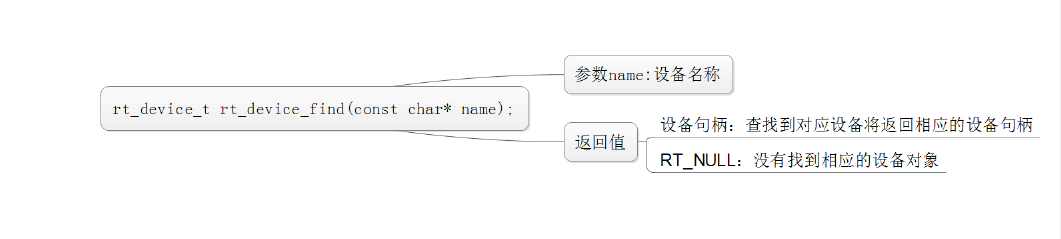
查找设备:
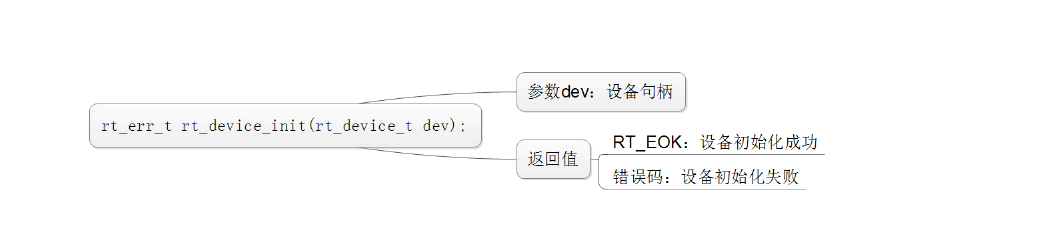
初始化设备:
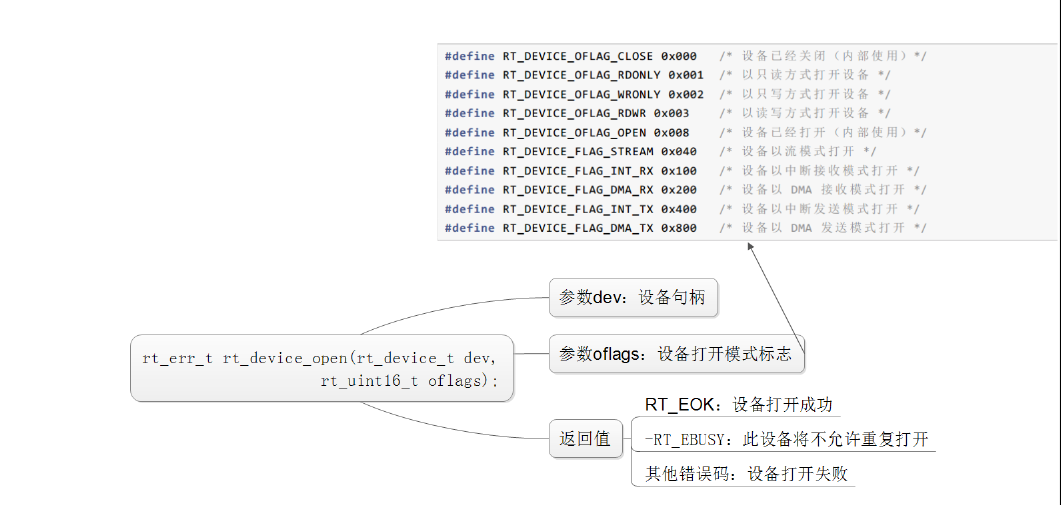
打开和关闭设备:
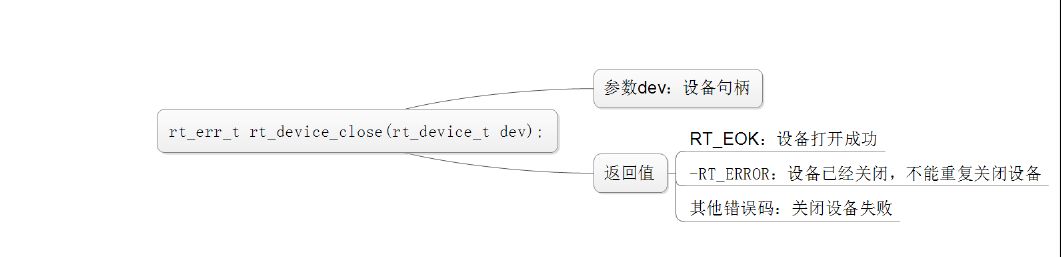
控制设备:

读写设备:
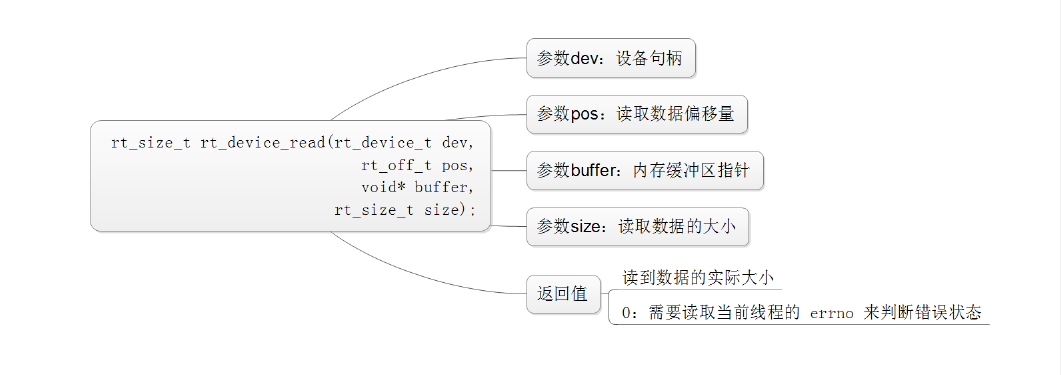
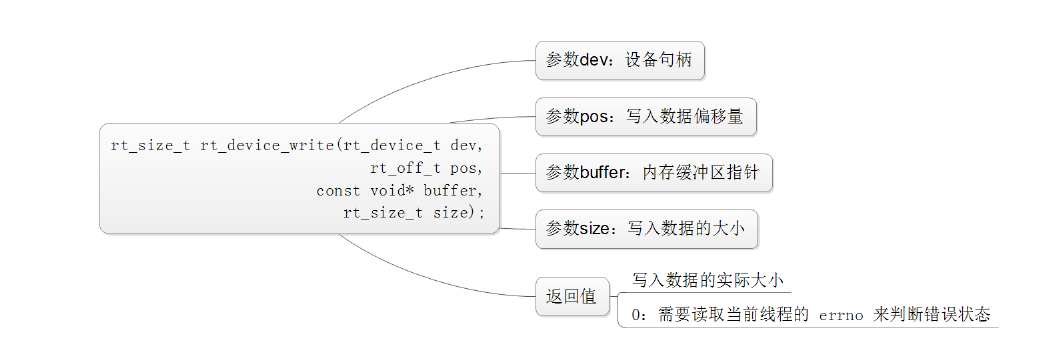
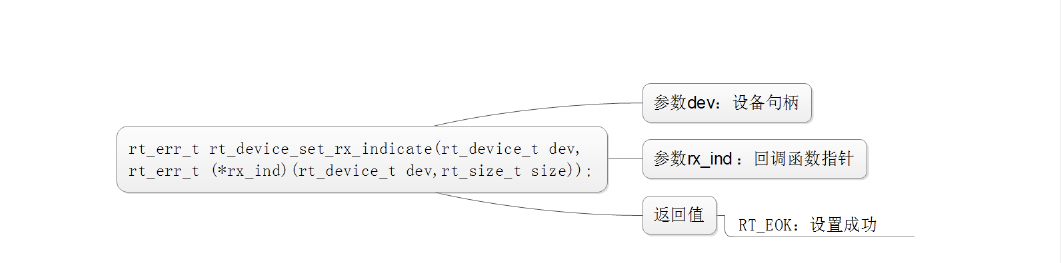
数据收发回调:
GPIO(PIN)设备模型
上面说的设备驱动层有两种注册设备的方式,对应的应用程序也有两种访问设备的方式。一种是通过设备操作接口访问,另一种是通过通用的设备驱动来访问。这里我们使用通用的GPIO设备驱动(对应源码:pin.c)来访问GPIO设备。其中通用的设备驱动在RT-Thread代码中作为一个组件,对应的路径为:
rt-thread\components\drivers这个文件夹下有很多驱动框架:
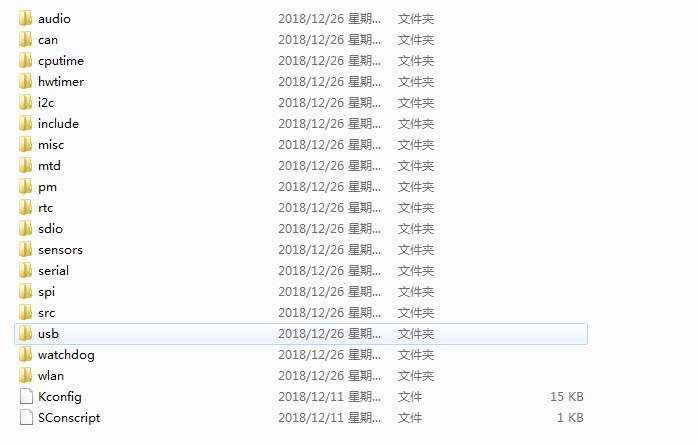
我们用的GPIO(PIN)设备驱动pin.c存在于文件夹misc下。
GPIO输入输出实验(按键点灯):
创建一个pin线程:
按键按下LED被点亮,按键松开LED熄灭。
static void pin_thread_entry(void *parameter)
{
unsigned int count = 1;
/* 设置LED引脚为输出模式 */
rt_pin_mode(PIN_LED_R, PIN_MODE_OUTPUT);
/* 设置KEY0引脚为输入模式 */
rt_pin_mode(PIN_KEY0, PIN_MODE_INPUT);
while (count > 0)
{
/* 读取KEY0引脚状态 */
if (rt_pin_read(PIN_KEY0) == PIN_LOW)
{
rt_thread_mdelay(50);
if (rt_pin_read(PIN_KEY0) == PIN_LOW)
{
count++;
rt_kprintf("KEY0 pressed! LED ON! count = %d\n", count);
rt_pin_write(PIN_LED_R, PIN_LOW);
}
}
else
{
rt_pin_write(PIN_LED_R, PIN_HIGH);
}
rt_thread_mdelay(10);
}
}
int main(void)
{
/* 线程句柄定义 */
rt_thread_t tid;
/* 创建动态pin线程 :优先级 25 ,时间片 5个系统滴答,线程栈512字节 */
tid = rt_thread_create("pin_thread",
pin_thread_entry,
RT_NULL,
STACK_SIZE,
THREAD_PRIORITY,
TIMESLICE);
/* 创建成功则启动动态线程 */
if (tid != RT_NULL)
{
rt_thread_startup(tid);
}
return 0;
}下载程序,在终端输入list_device命令:
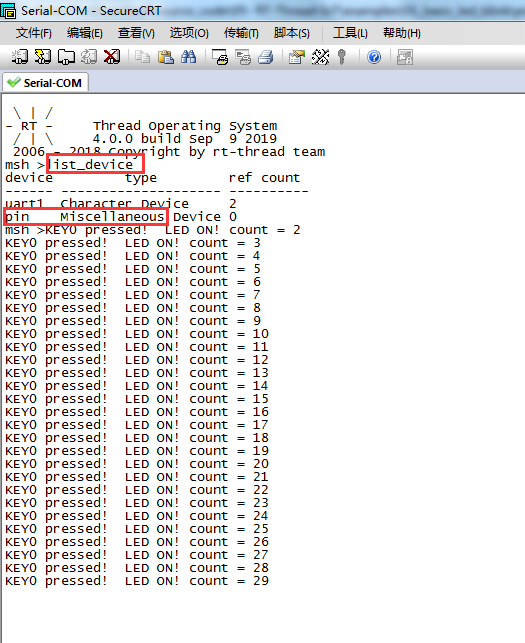
可以看到device是pin,类型是Miscellaneous Device,说明我们正在使用通用的GPIO设备驱动。这个实验中有三个文件值得关注,分别是
device.c:设备管理层
pin.c:设备驱动框架层
drv_gpio.c:设备驱动层其中device.c与pin.c属于RT-Thread的范畴,drv_gpio.c与具体的硬件有关,这个文件里操控的就是与硬件有关的东西,如:
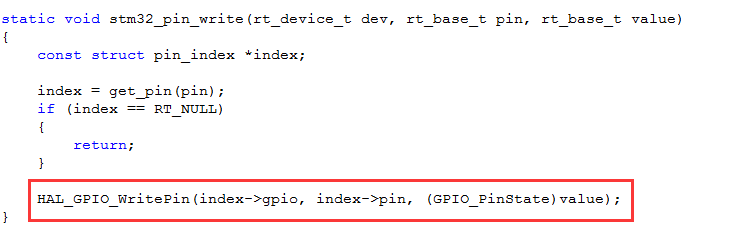
程序中用到的rt_pin_mode及rt_pin_write等都是PIN设备管理接口。PIN设备管理有如下几个接口:
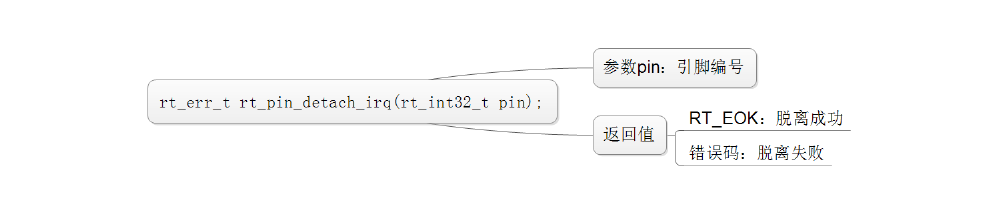
设置引脚模式:

RT-Thread 提供的引脚编号需要和芯片的引脚号区分开来,它们并不是同一个概念,引脚编号由 PIN设备驱动程序定义,和具体的芯片相关。
设置引脚电平:

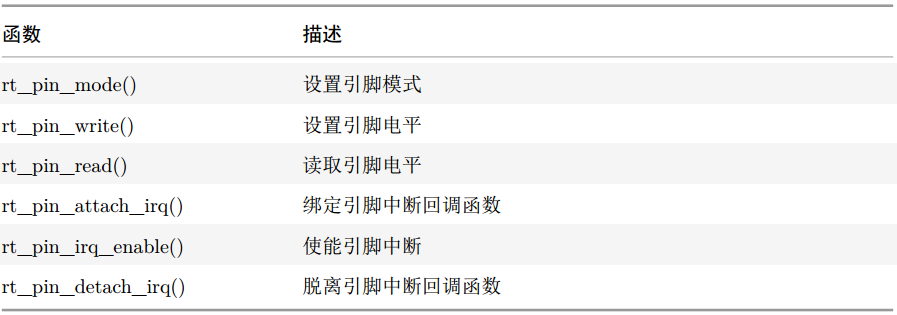
读取引脚电平:
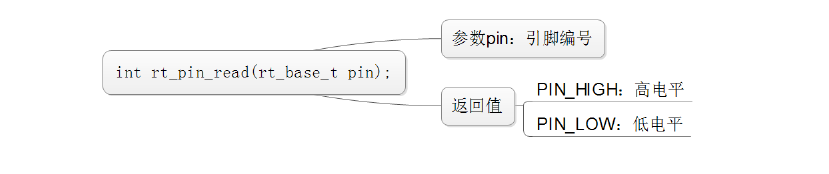
绑定引脚中断回调函数:
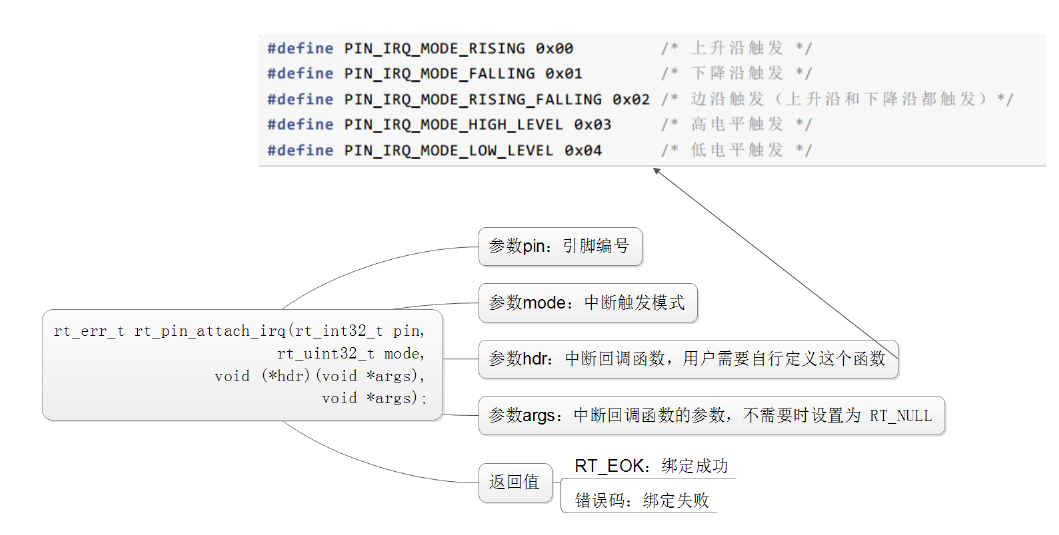
使能引脚中断:
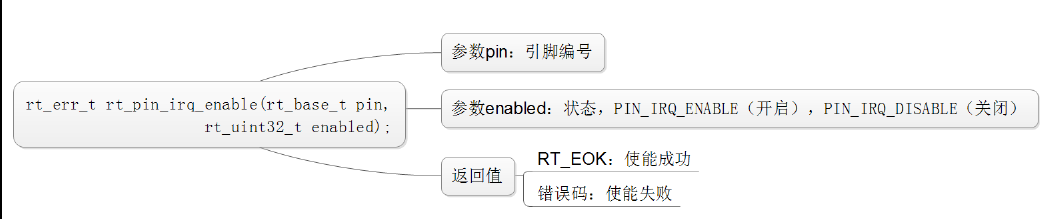
脱离引脚中断回调函数:
RAID 技术
硬RAID
|
名称 |
读写性能 |
容错/校验位 |
磁盘利用率 |
最小磁盘数 |
|---|---|---|---|---|
|
raid0 |
读写性能提升 |
无 |
100% |
1 |
|
raid1 |
读提升,写下降 |
有冗余 1 |
1/2 |
2 |
|
raid5 |
读写性能提升 |
容错1 校验1 |
n-1/n |
3 |
|
raid6 |
读写性能提升 |
容错2 校验2 |
n-2/n |
4 |
|
raid10 |
读写性能提升 |
每组镜像1个 |
1/2 |
4 |
|
raid01 |
读写性能提升 |
比不上raid10 |
1/2 |
4 |
|
raid50 |
读写性能提升 |
非常高 |
1/3 |
9 |
spare disk 备用盘
软RAID
mdadm:为软RAID提供管理界面
生成的设备为:/dev/md0、/dev/md1、/dev/md2等
md:multi devices
磁盘结构
磁盘(Disk)是由表面涂有磁性物质的金属或塑料构成的圆形盘片,通过一个称为磁头 的导体线圈从磁盘中存取数据。在读/写操作期间,磁头固定,磁盘在下面高速旋转。如图 4-23所示,磁盘的盘面上的数据存储在一组同心圆中,称为磁道。每个磁道与磁头一样宽, 一个盘面有上千个磁道。磁道又划分为几百个扇区,每个扇区固定存储大小(通常为512B), 一个扇区称为一个盘块。相邻磁道及相邻扇区间通过一定的间隙分隔开,以避免精度错误。
注意,由于扇区按固定圆心角度划分,所以密度从最外道向里道增加,磁盘的存储能力受限于最内道的最大记录密度。
磁盘安装在一个磁盘驱动器中,它由磁头臂、用于旋转磁盘的主轴和用于数据输入/输 出的电子设备组成。如图4-24所示,多个盘片垂直堆叠,组成磁盘组,每个盘面对应一个 磁头,所有磁头固定在一起,与磁盘中心的距离相同且一起移动。所有盘片上相对位置相同 的磁道组成柱面。按照这种物理结构组织,扇区就是磁盘可寻址的最小存储单位,磁盘地址 用“柱面号 • 盘面号 • 扇区号(或块号)”表示。

磁盘按不同方式可以分为若干类型:磁头相对于盘片的径向方向固定的称为固定头磁 盘,每个磁道一个磁头;磁头可移动的称为活动头磁盘,磁头臂可以来回伸缩定位磁道。磁 盘永久固定在磁盘驱动器内的称为固定盘磁盘;可移动和替换的称为可换盘磁盘。
网络术语、端口、协议
导言
对网络的基本了解对于任何管理服务器的人来说都很重要。这不仅对让您的服务在线和平稳运行至关重要,而且还为您提供了诊断问题的洞察力。
本文件将提供一些常见网络概念的基本概述。我们将讨论基本术语、通用协议以及不同层次网络的责任和特点。
本指南与操作系统无关,但在实现利用服务器上网络的功能和服务时,应该非常有帮助。
网络术语表
在我们开始深入讨论网络之前,我们必须定义一些常见的术语,您将在本指南以及其他有关网络的指南和文档中看到。
这些术语将在以下适当章节中扩展:
-
连接:在网络中,连接是指通过网络传输的相关信息。这通常推断,连接是在数据传输之前构建的(通过遵循协议中规定的程序),然后在数据传输结束时解构。
-
数据包:一般来说,数据包是通过网络传输的最基本的单元。通过网络通信时,数据包是将您的数据(成块)从一个端点到另一个端点的信封。
数据包有一个标题部分,其中包含有关数据包的信息,包括源和目标、时间戳、网络跳动等。数据包的主要部分包含要传输的实际数据。它有时被称为身体或有效载荷。
-
网络接口:网络接口可以指网络硬件的任何类型的软件接口。例如,如果您的计算机中有两张网卡,您可以单独控制和配置与它们关联的每个网络接口。
网络接口可以与物理设备相关联,也可以是虚拟接口的表示。“环回”设备是本地机器的虚拟接口,就是一个例子。
-
局域网:局域网代表“局域网”。它指的是更大的互联网无法公开访问的网络或网络的一部分。家庭或办公室网络是局域网的一个例子。
-
广域网:广域网代表“广域网”。它意味着一个比局域网广泛得多的网络。虽然广域网是用来描述大型分散网络的相关术语,但它通常意味着整个互联网。
如果说接口连接到广域网,通常假设它可以通过互联网访问。
-
协议:协议是一套规则和标准,基本上定义了设备可用于通信的语言。网络中广泛使用了大量协议,它们通常在不同层实现。
一些低级协议是TCP、UDP、IP和ICMP。基于这些较低协议的应用程序层协议的一些熟悉示例是HTTP(用于访问Web内容)、SSH、TLS/SSL和FTP。
-
端口:端口是一台机器上可以绑定到特定软件的地址。它不是一个物理接口或位置,但它允许您的服务器能够使用多个应用程序进行通信。
-
防火墙:防火墙是一个程序,它决定是否允许进入服务器或进出服务器的流量。防火墙通常通过创建哪些类型的流量可以在哪些端口上接受来工作。一般来说,防火墙会阻止服务器上特定应用程序不使用的端口。
-
NAT:NAT代表网络地址转换。这是一种将传入路由服务器的请求转换为它在局域网中知道的相关设备或服务器的方法。这通常在物理局域网中实现,作为通过一个IP地址将请求路由到必要的后端服务器的一种方式。
-
VPN:VPN代表虚拟专用网络。它是一种通过互联网连接独立局域网的手段,同时保持隐私。这通常出于安全原因,被用作连接远程系统的手段,就像它们在本地网络上一样。
你可能会遇到许多其他术语,这个列表不能详尽无遗。我们会根据需要解释其他术语。此时,您应该了解一些基本的、高级的概念,这将使我们能够更好地讨论即将到来的主题。
网络层
虽然网络经常以横向拓扑的方式讨论,但在主机之间,其实现在整个计算机或网络中以垂直方式分层。
这意味着有多种技术和协议相互建立,以便通信更轻松地运行。每个连续的更高层都更多地抽象原始数据,使其更容易用于应用程序和用户。
它还允许您以新的方式利用较低层,而无需投入时间和精力来开发处理这些类型流量的协议和应用程序。
我们用来谈论每种分层方案的语言因您使用的模型而异。无论用于讨论图层的模型如何,数据路径都是一样的。
当数据从一台机器发送时,它从堆栈顶部开始,向下过滤。在最低层,实际传输到另一台机器。此时,数据通过另一台计算机的层层返回。
每个层都能够在从相邻层收到的数据周围添加自己的“wrapper”,这将有助于之后的层决定在数据传递时如何处理数据。
OSI模型
从历史上看,谈论不同层网络通信的一种方法是OSI模型。OSI代表Open Systems Interconnect。
该模型定义了七个独立的层。该模型中的图层是:
-
应用程序:应用程序层是用户和用户应用程序最常与之交互的层。从资源可用性、与之通信的合作伙伴和数据同步方面讨论了网络通信。
-
演示文稿:演示文稿层负责映射资源和创建上下文。它用于将较低级别的网络数据转换为应用程序期望看到的数据。
-
会话:会话层是一个连接处理程序。它以持久的方式创建、维护和破坏节点之间的连接。
-
传输:传输层负责为上面的层提供可靠的连接。在这种情况下,可靠是指验证连接另一端是否完整接收数据的能力。
此层可以重新发送已删除或损坏的信息,并可以确认接收到远程计算机的数据。
-
网络:网络层用于在网络上的不同节点之间路由数据。它使用地址来判断要向哪台计算机发送信息。该层还可以将较大的消息分解成更小的块,以便在另一端重新组装。
-
数据链路:该层是作为使用现有物理连接在网络上不同节点或设备之间建立和维护可靠链接的一种方法。
-
物理:物理层负责处理用于连接的实际物理设备。该层涉及管理物理连接的裸机软件以及硬件本身(如以太网)。
如您所见,根据它们与裸机硬件的接近程度及其提供的功能,可以讨论许多不同的层。
TCP/IP模型
TCP/IP模型,通常称为互联网协议套件,是另一个更简单且已被广泛采用的分层模型。它定义了四个独立的层,其中一些与OSI模型重叠:
-
应用程序:在此模型中,应用程序层负责在应用程序之间创建和传输用户数据。这些应用程序可以在远程系统上运行,并且应该看起来像是本地对最终用户一样运行。
据说沟通发生在同行之间。
-
传输:传输层负责流程之间的通信。这种级别的网络利用端口来处理不同的服务。根据所使用的协议类型,它可以建立不可靠或可靠的连接。
-
互联网:互联网层用于在网络中将数据从一个节点传输到另一个节点。该层了解连接的端点,但不担心从一个地方到另一个地方所需的实际连接。IP地址在此层中被定义为以可寻址方式访问远程系统的一种方式。
-
链接:链接层实现了本地网络的实际拓扑结构,允许互联网层呈现可寻址的接口。它在相邻节点之间建立连接以发送数据。
如您所见,TCP/IP模型更加抽象和流畅。这使它更容易实现,并使其成为网络层分类的主要方式。
接口
接口是您计算机的网络通信点。每个接口都与物理或虚拟网络设备相关联。
通常,您的服务器将为您的每张以太网或无线互联网卡配备一个可配置的网络接口。
此外,它将定义一个名为“环回”或本地主机接口的虚拟网络接口。这被用作将一台计算机上的应用程序和进程连接到其他应用程序和进程的接口。您可以在许多工具中看到这被引用为“lo”界面。
很多时候,管理员配置一个接口来服务互联网流量,另一个接口为局域网或专用网络提供服务。
在DigitalOcean中,在启用专用网络的数据中心,您的VPS将有两个网络接口(除了本地接口)。“eth0”接口将配置为处理来自互联网的流量,而“eth1”接口将用于与专用网络通信。
协议
网络的工作原理是背着许多不同的协议。通过这种方式,可以使用相互封装的多个协议传输一段数据。
我们将讨论您可能遇到的一些更常见的协议,并试图解释其区别,并给出它们涉及流程的哪个部分的上下文。
我们将从在较低的网络层上实现的协议开始,并一直致力于具有更高抽象的协议。
中等访问控制
中型访问控制是一种用于区分特定设备的通信协议。在制造过程中,每台设备都应该获得一个唯一的媒体访问控制地址(MAC地址),将其与互联网上的所有其他设备区分开来。
通过MAC地址寻址硬件允许您通过唯一值引用设备,即使顶部的软件可能会在运行期间更改该特定设备的名称。
中等访问控制是链接层中唯一可能定期交互的协议之一。
IP
IP协议是允许互联网工作的基本协议之一。IP地址在每个网络上都是唯一的,它们允许机器在网络上相互寻址。它在IP/TCP模型的互联网层上实现。
网络可以连接在一起,但跨越网络边界时必须路由流量。该协议假设网络不可靠,并有多个路径前往同一目的地,可以在两者之间动态更改。
该协议有许多不同的实现。今天最常见的实现是IPv4,尽管由于IPv4地址稀缺和协议功能的改进,IPv6作为替代品越来越受欢迎。
ICMP
ICMP代表互联网控制消息协议。它用于在设备之间发送消息,以指示可用性或错误条件。这些数据包用于各种网络诊断工具,如ping和traceroute。
通常,当不同类型的数据包遇到某种问题时,会传输ICMP数据包。基本上,它们被用作网络通信的反馈机制。
TCP
TCP代表传输控制协议。它在IP/TCP模型的传输层中实现,并用于建立可靠的连接。
TCP是将数据封装到数据包中的协议之一。然后,它使用下层可用的方法将这些传输到连接的远程端。在另一端,它可以检查错误,请求重新发送某些部分,并将信息重新组装成一个逻辑部分以发送到应用程序层。
该协议在数据传输之前使用称为三向握手的系统建立连接。这是通信两端确认请求并商定确保数据可靠性的方法的一种方式。
数据发送后,使用类似的四向握手将断开连接。
TCP是互联网许多最流行用途的首选协议,包括WWW、FTP、SSH和电子邮件。可以肯定地说,如果没有TCP,我们今天知道的互联网就不会在这里。
UDP
UDP代表用户数据报协议。它是TCP的流行配套协议,也在传输层中实现。
UDP和TCP之间的根本区别在于UDP提供不可靠的数据传输。它没有验证连接的另一端是否已收到数据。这听起来可能是一件坏事,出于许多目的,它是坏事。然而,这对某些功能也极其重要。
由于不需要等待数据已收到并被迫重新发送数据的确认,UDP比TCP快得多。它不会与远程主机建立连接,它只是将数据发射到该主机,并且不在乎它是否被接受。
因为它是一个简单的事务,所以对于查询网络资源等简单通信非常有用。它也不保持状态,这使得它非常适合将数据从一台机器传输到许多实时客户端。这使得它非常适合VOIP、游戏和其他负担不起延迟的应用程序。
HTTP
HTTP代表超文本传输协议。它是应用程序层中定义的协议,构成了网络通信的基础。
HTTP定义了许多函数,告诉远程系统您正在请求的内容。例如,GET、POST和DELETE都以不同的方式与请求的数据交互。
FTP
FTP代表文件传输协议。它也在应用程序层中,提供了一种将完整文件从一个主机传输到另一个主机的方法。
它本质上不安全,因此不建议用于任何面向外部的网络,除非它作为公共、仅下载的资源实现。
DNS
DNS代表域名系统。它是一种应用程序层协议,用于为互联网资源提供人性化的命名机制。它将域名与IP地址联系起来,并允许您在浏览器中按名称访问网站。
SSH
SSH代表安全外壳。它是在应用程序层中实现的加密协议,可用于以安全的方式与远程服务器通信。由于其端到端加密和无处不在,围绕该协议构建了许多其他技术。
还有许多其他我们尚未涵盖的协议同样重要。然而,这应该能很好地概述一些使互联网和网络成为可能的基本技术。
结论
此时,您应该熟悉一些基本的网络术语,并能够了解不同组件如何相互通信。这应该有助于您了解其他文章和系统文档。
数据位
电子设备之间的通信就像人类之间的交流,双方都需要说相同的语言。在电子产品中,这些语言称为通信协议。
之前有单独地分享了SPI、UART、I2C通信的文章,这篇对它们做一些对比。
串行 VS 并行
电子设备通过发送数据位从而实现相互交谈。位是二进制的,只能是1或0。通过电压的快速变化,位从一个设备传输到另一个设备。在以5V工作的系统中,“0”通过0V的短脉冲进行通信,而“1”通过5V的短脉冲进行通信。
数据位可以通过并行或串行的形式进行传输。 在并行通信中,数据位在导线上同时传输。下图显示了二进制(01000011)中字母“C”的并行传输:

在串行通信中,位通过单根线一一发送。下图显示了二进制(01000011)中字母“C”的串行传输:

SPI通信
SPI是一种常见的设备通用通信协议。它有一个独特优势就是可以无中断传输数据,可以连续地发送或接收任意数量的位。而在I2C和UART中,数据以数据包的形式发送,有着限定位数。
在SPI设备中,设备分为主机与从机系统。主机是控制设备(通常是微控制器),而从机(通常是传感器,显示器或存储芯片)从主机那获取指令。
一套SPI通讯共包含四种信号线:MOSI (Master Output/Slave Input) – 信号线,主机输出,从机输入。MISO (Master Input/Slave Output) – 信号线,主机输入,从机输出。SCLK (Clock) – 时钟信号。SS/CS (Slave Select/Chip Select) – 片选信号。

SPI协议特点
实际上,从机的数量受系统负载电容的限制,它会降低主机在电压电平之间准确切换的能力。
工作原理
时钟信号
每个时钟周期传输一位数据,因此数据传输的速度取决于时钟信号的频率。 时钟信号由于是主机配置生成的,因此SPI通信始终由主机启动。
设备共享时钟信号的任何通信协议都称为同步。SPI是一种同步通信协议,还有一些异步通信不使用时钟信号。 例如在UART通信中,双方都设置为预先配置的波特率,该波特率决定了数据传输的速度和时序。
片选信号
主机通过拉低从机的CS/SS来使能通信。 在空闲/非传输状态下,片选线保持高电平。在主机上可以存在多个CS/SS引脚,允许主机与多个不同的从机进行通讯。

如果主机只有一个片选引脚可用,则可以通过以下方式连接这些从器件:

MOSI和MISO
主机通过MOSI以串行方式将数据发送给从机,从机也可以通过MISO将数据发送给主机,两者可以同时进行。所以理论上,SPI是一种全双工的通讯协议。
传输步骤
1. 主机输出时钟信号

2. 主机拉低SS / CS引脚,激活从机

3. 主机通过MOSI将数据发送给从机

4. 如果需要响应,则从机通过MISO将数据返回给主机

使用SPI有一些优点和缺点,如果在不同的通信协议之间进行选择,则应根据项目要求进行充分考量。
优劣
优点
SPI通讯无起始位和停止位,因此数据可以连续流传输而不会中断;没有像I2C这样的复杂的从站寻址系统,数据传输速率比I2C更高(几乎快两倍)。独立的MISO和MOSI线路,可以同时发送和接收数据。
缺点
SPI使用四根线(I2C和UART使用两根线),没有信号接收成功的确认(I2C拥有此功能),没有任何形式的错误检查(如UART中的奇偶校验位等)。

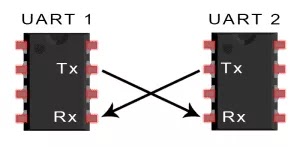
UART代表通用异步接收器/发送器也称为串口通讯,它不像SPI和I2C这样的通信协议,而是微控制器中的物理电路或独立的IC。
UART的主要目的是发送和接收串行数据,其最好的优点是它仅使用两条线在设备之间传输数据。UART的原理很容易理解,但是如果您还没有阅读SPI 通讯协议,那可能是一个不错的起点。
UART通信
在UART通信中,两个UART直接相互通信。 发送UART将控制设备(如CPU)的并行数据转换为串行形式,以串行方式将其发送到接收UART。只需要两条线即可在两个UART之间传输数据,数据从发送UART的Tx引脚流到接收UART的Rx引脚:
UART属于异步通讯,这意味着没有时钟信号,取而代之的是在数据包中添加开始和停止位。这些位定义了数据包的开始和结束,因此接收UART知道何时读取这些数据。
当接收UART检测到起始位时,它将以特定波特率的频率读取。波特率是数据传输速度的度量,以每秒比特数(bps)表示。两个UART必须以大约相同的波特率工作,发送和接收UART之间的波特率只能相差约10%。

工作原理
发送UART从数据总线获取并行数据后,它会添加一个起始位,一个奇偶校验位和一个停止位来组成数据包并从Tx引脚上逐位串行输出,接收UART在其Rx引脚上逐位读取数据包。

UART数据包含有1个起始位,5至9个数据位(取决于UART),一个可选的奇偶校验位以及1个或2个停止位:

起始位:
UART数据传输线通常在不传输数据时保持在高电压电平。开始传输时发送UART在一个时钟周期内将传输线从高电平拉低到低电平,当接收UART检测到高电压到低电压转换时,它开始以波特率的频率读取数据帧中的位。
数据帧:
数据帧内包含正在传输的实际数据。如果使用奇偶校验位,则可以是5位,最多8位。如果不使用奇偶校验位,则数据帧的长度可以为9位。
校验位:
奇偶校验位是接收UART判断传输期间是否有任何数据更改的方式。接收UART读取数据帧后,它将对值为1的位数进行计数,并检查总数是偶数还是奇数,是否与数据相匹配。
停止位:
为了向数据包的结尾发出信号,发送UART将数据传输线从低电压驱动到高电压至少持续两位时间。
传输步骤
1. 发送UART从数据总线并行接收数据:

2.发送UART将起始位,奇偶校验位和停止位添加到数据帧:

3.整个数据包从发送UART串行发送到接收UART。接收UART以预先配置的波特率对数据线进行采样:

4.接收UART丢弃数据帧中的起始位,奇偶校验位和停止位:

5.接收UART将串行数据转换回并行数据,并将其传输到接收端的数据总线:

优劣
没有任何通信协议是完美的,但是UART非常擅长于其工作。以下是一些利弊,可帮助您确定它们是否适合您的项目需求:
优点
- 仅使用两根电线
- 无需时钟信号
- 具有奇偶校验位以允许进行错误检查
- 只要双方都设置好数据包的结构
- 有据可查并得到广泛使用的方法
缺点
- 数据帧的大小最大为9位
- 不支持多个从属系统或多个主系统
- 每个UART的波特率必须在彼此的10%之内
I2C通信
I2C总线是由Philips公司开发的一种简单、双向二线制同步串行总线。它只需要两根线即可传送信息。它结合了 SPI 和 UART 的优点,您可以将多个从机连接到单个主机(如SPI那样),也可以使用多个主机控制一个或多个从机。当您想让多个微控制器将数据记录到单个存储卡或将文本显示到单个LCD时,这将非常有用。

SDA (Serial Data) – 数据线。
SCL (Serial Clock) – 时钟线。
I2C是串行通信协议,因此数据沿着SDA一点一点地传输。与SPI一样,I2C也需要时钟同步信号且时钟始终由主机控制。

工作原理
I2C的数据传输是以多个msg的形式进行,每个msg都包含从机的二进制地址帧,以及一个或多个数据帧,还包括开始条件和停止条件,读/写位和数据帧之间的ACK / NACK位:

启动条件:当SCL是高电平时,SDA从高电平向低电平切换。
停止条件:当SCL是高电平时,SDA由低电平向高电平切换。
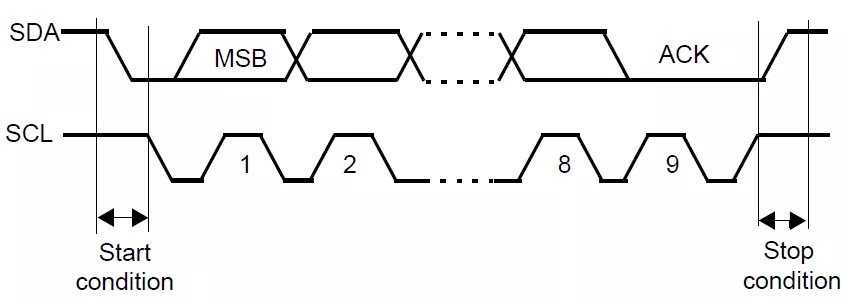
地址帧:每个从属设备唯一的7位或10位序列,用于主从设备之间的地址识别。
读/写位:一位,如果主机是向从机发送数据则为低电平,请求数据则为高电平。
ACK/NACK:消息中的每个帧后均带有一个ACK/NACK位。如果成功接收到地址帧或数据帧,接收设备会返回一个ACK位用于表示确认。
寻址
由于I2C没有像SPI那样的片选线,因此它需要使用另一种方式来确认某一个从设备,而这个方式就是 —— 寻址 。
主机将要通信的从机地址发送给每个从机,然后每个从机将其与自己的地址进行比较。如果地址匹配,它将向主机发送一个低电平ACK位。如果不匹配,则不执行任何操作,SDA线保持高电平。
读/写位
地址帧的末尾包含一个读/写位。如果主机要向从机发送数据,则为低电平。如果是主机向从机请求数据,则为高电平。
数据帧
当主机检测到从机的ACK位后,就可以发送第一个数据帧了。数据帧始终为8位,每个数据帧后紧跟一个ACK / NACK位,来验证接收状态。当发送完所有数据帧后,主机可以向从机发送停止条件来终止通信。
传输步骤
1. 在SCL线为高电平时,主机通过将SDA线从高电平切换到低电平来启动总线通信。
2. 主机向总线发送要与之通信的从机的7位或10位地址,以及读/写位:
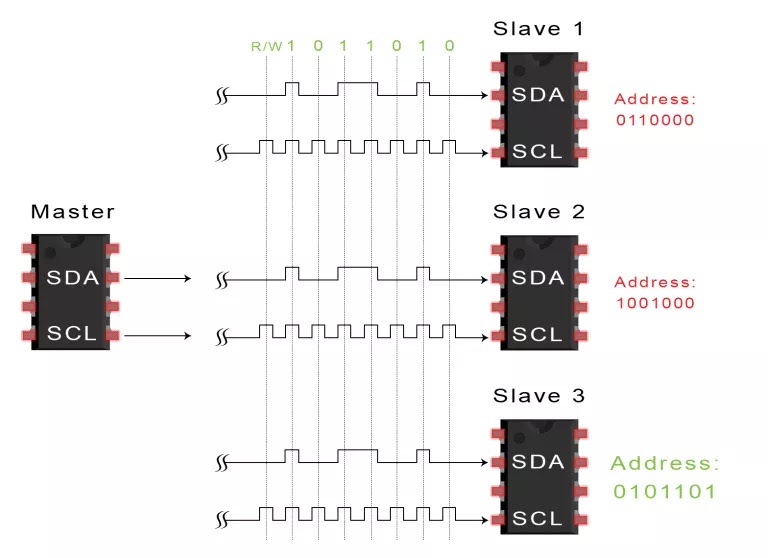
3. 每个从机将主机发送的地址与其自己的地址进行比较。如果地址匹配,则从机通过将SDA线拉低一位返回一个ACK位。如果主机的地址与从机的地址不匹配,则从机将SDA线拉高。

4. 主机发送或接收数据帧:

5. 传输完每个数据帧后,接收设备将另一个ACK位返回给发送方,以确认已成功接收到该帧:

6. 随后主机将SCL切换为高电平,然后再将SDA切换为高电平,从而向从机发送停止条件。
单个主机VS多个从机
由于I2C使用寻址功能,可以通过一个主机控制多个从机。使用7位地址时,最多可以使用128(27)个唯一地址。使用10位地址并不常见,但可以提供1,024(210)个唯一地址。如果要将多个从机连接到单个主机时,请使用4.7K欧的上拉电阻将它们连接,例如将SDA和SCL线连接到Vcc:
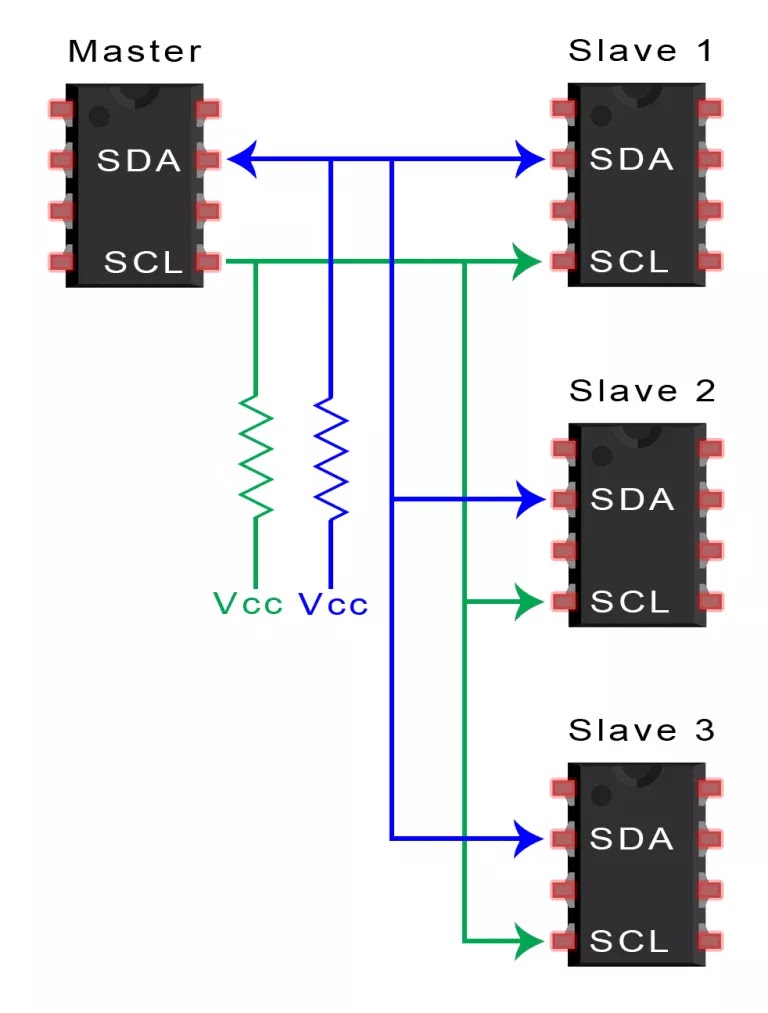
多个主机VS多个从机
I2C支持多个主机同时与多个从机相连,当两个主机试图通过SDA线路同时发送或接收数据时,就会出现问题。因此每个主机都需要在发送消息之前检测SDA线是低电平还是高电平。如果SDA线为低电平,则意味着另一个主机正在控制总线。如果SDA线高,则可以安全地发送数据。如果要将多个主机连接到多个从机,请使用4.7K欧的上拉电阻将SDA和SCL线连接到Vcc:
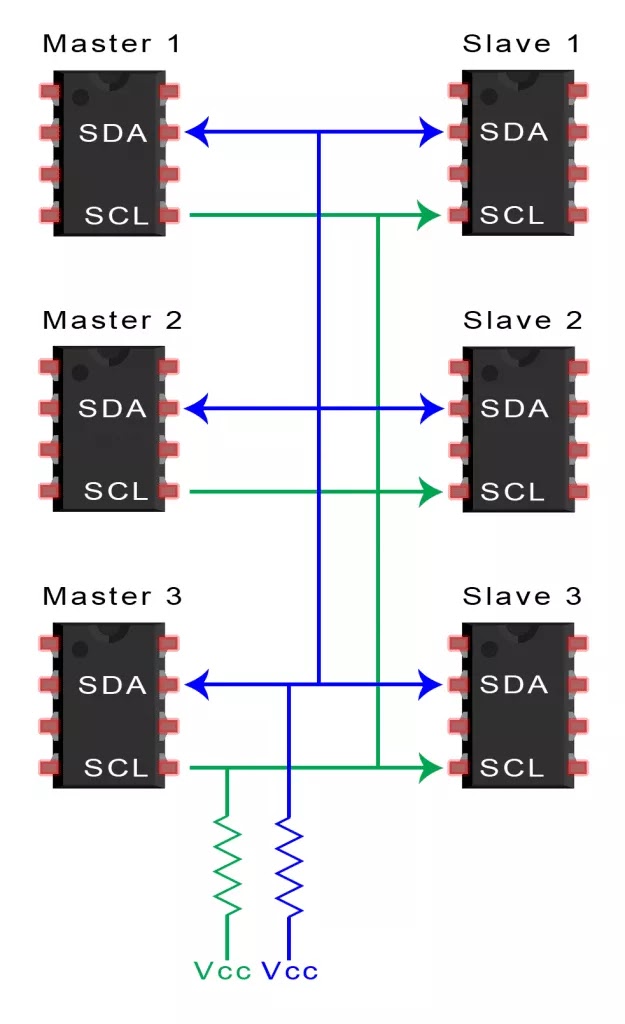
优劣
与其他协议相比,I2C可能听起来很复杂。以下是一些利弊,可帮助您确定它们是否适合您的项目需求:
优点
- 仅使用两根电线
- 支持多个主机和多个从机
- 每个UART的波特率必须在彼此的10%之内
- 硬件比UART更简单
- 众所周知且被广泛使用的协议
缺点
- 数据传输速率比SPI慢
- 数据帧的大小限制为8位
操作系统
从这一篇开始,您就将跟着我一起进入这操作系统的梦幻之旅!
别担心,每一章的内容会非常的少,而且你也不要抱着很大的负担去学习,只需要像读小说一样,跟着我一章一章读下去就好。
话不多说,直奔主题。当你按下开机键的那一刻,在主板上提前写死的固件程序 BIOS 会将硬盘中启动区的 512 字节的数据,原封不动复制到内存中的 0x7c00 这个位置,并跳转到那个位置进行执行。

启动区的定义非常简单,只要硬盘中的 0 盘 0 道 1 扇区的 512 个字节的最后两个字节分别是 0x55 和 0xaa,那么 BIOS 就会认为它是个启动区。
所以对于我们理解操作系统而言,此时的 BIOS 仅仅就是个代码搬运工,把 512 字节的二进制数据从硬盘搬运到了内存中而已。所以作为操作系统的开发人员,仅仅需要把操作系统最开始的那段代码,编译并存储在硬盘的 0 盘 0 道 1 扇区即可。之后 BIOS 会帮我们把它放到内存里,并且跳过去执行。
而 Linux-0.11 的最开始的代码,就是这个用汇编语言写的 bootsect.s,位于 boot 文件夹下。

通过编译,这个 bootsect.s 会被编译成二进制文件,存放在启动区的第一扇区。

随后就会如刚刚所说,由 BIOS 搬运到内存的 0x7c00 这个位置,而 CPU 也会从这个位置开始,不断往后一条一条语句无脑地执行下去。
那我们的梦幻之旅,就从这个文件的第一行代码开始啦!
mov ax,0x07c0 mov ds,ax
好吧,先连续看两行。
这段代码是用汇编语言写的,含义是把 0x07c0 这个值复制到 ax 寄存器里,再将 ax 寄存器里的值复制到 ds 寄存器里。那其实这一番折腾的结果就是,让 ds 这个寄存器里的值变成了 0x07c0。

ds 是一个 16 位的段寄存器,具体表示数据段寄存器,在内存寻址时充当段基址的作用。啥意思呢?就是当我们之后用汇编语言写一个内存地址时,实际上仅仅是写了偏移地址,比如:
mov ax, [0x0001]
实际上相当于
mov ax, [ds:0x0001]
ds 是默认加上的,表示在 ds 这个段基址处,往后再偏移 0x0001 单位,将这个位置的内存数据,复制到 ax 寄存器中。
形象地比喻一下就是,你和朋友商量去哪玩比较好,你说天安门、南锣鼓巷、颐和园等等,实际上都是偏移地址,省略了北京市这个基址。
当然你完全可以说北京天安门、北京南锣鼓巷这样,每次都加上北京这个前缀。不过如果你事先和朋友说好,以下我说的地方都是北京市里的哈,之后你就不用每次都带着北京市这个词了,是不是很方便?
那 ds 这个数据段寄存器的作用就是如此,方便了描述一个内存地址时,可以省略一个基址,没什么神奇之处。
ds : 0x0001
北京市 : 南锣鼓巷
再看,这个 ds 被赋值为了 0x07c0,由于 x86 为了让自己在 16 位这个实模式下能访问到 20 位的地址线这个历史因素(不了解这个的就先别纠结为啥了),所以段基址要先左移四位。那 0x07c0 左移四位就是 0x7c00,那这就刚好和这段代码被 BIOS 加载到的内存地址 0x7c00 一样了。
也就是说,之后再写的代码,里面访问的数据的内存地址,都先默认加上 0x7c00,再去内存中寻址。
为啥统一加上 0x7c00 这个数呢?这很好解释,BIOS 规定死了把操作系统代码加载到内存 0x7c00,那么里面的各种数据自然就全都被偏移了这么多,所以把数据段寄存器 ds 设置为这个值,方便了以后通过这种基址的方式访问内存里的数据。

OK,赶紧消化掉前面的知识,那本篇就到此为止,只讲了两行代码,知识量很少,我没骗你吧。
希望你能做到,对 BIOS 将操作系统代码加载到内存 0x7c00,以及我们通过 mov 指令将默认的数据段寄存器 ds 寄存器的值改为 0x07c0 方便以后的基址寻址方式,这两件事在心里认可,并且没有疑惑,这才方便后面继续进行。
后面的世界越来越精彩,欲知后事如何,且听下回分解。
------- 本回扩展资料 -------
有关寄存器的详细信息,可以参考 Intel 手册:
Volume 1 Chapter 3.2 OVERVIEW OF THE BASIC EXECUTION ENVIRONMEN
有关计算机启动部分的原理如果还不清楚,可以看我之前的一篇文章了解一下:
如果想了解计算机启动时详细的初始化过程,还是得参考 Intel 手册:
Volume 3A Chapter 9 PROCESSOR MANAGEMENT AND INITIALIZATION
------- 关于本系列 -------
本系列的开篇词看这
本系列的扩展资料看这,这里有很多有趣的资料、答疑、互动参与项目,持续更新中,希望有你的参与。
https://github.com/sunym1993/flash-linux0.11-talk
本系列全局视角

最后,祝大家都能追更到系列结束,只要你敢持续追更,并且把每一回的内容搞懂,我就敢让你在系列结束后说一句,我对 Linux 0.11 很熟悉。
另外,本系列完全免费,希望大家能多多传播给同样喜欢的人,同时给我的 GitHub 项目点个 star,这些就足够让我坚持写下去了!我们下回见。
哪些端口无法访问?
出于安全因素考虑,部分运营商会对下列端口进行拦截,导致无法访问。建议避免使用下列端口:
|
协议 |
不支持端口 |
|---|---|
|
TCP |
42 135 137 138 139 444 445 593 1025 1068 1434 3127 3128 3129 3130 4444 4789 4790 5554 5800 5900 9996 |
|
UDP |
命名空间
命名空间(英语:Namespace),也称名字空间、名称空间等,它表示着一个标识符(identifier)的可见范围。一个标识符可在多个名字空间中定义,它在不同名字空间中的含义是互不相干的。这样,在一个新的名字空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其他名字空间中。
例如,设Bill是X公司的员工,工号为123,而John是Y公司的员工,工号也是123。由于两人在不同的公司工作,可以使用相同的工号来标识而不会造成混乱,这里每个公司就表示一个独立的名字空间。如果两人在同一家公司工作,其工号就不能相同了,否则在支付工资时便会发生混乱。
这一特点是使用名字空间的主要理由。在大型的计算机程序或文档中,往往会出现数百或数千个标识符。名字空间提供一隐藏区域标识符的机制。[1]通过将逻辑上相关的标识符组织成相应的名字空间,可使整个系统更加模块化。
在编程语言中,名字空间是对作用域的一种特殊的抽象,它包含了处于该作用域内的标识符,且本身也用一个标识符来表示,这样便将一系列在逻辑上相关的标识符用一个标识符组织了起来。许多现代编程语言都支持名字空间。在一些编程语言(例如C++和Python)中,名字空间本身的标识符也属于一个外层的名字空间,也即名字空间可以嵌套,构成一个名字空间树,树根则是无名的全局名字空间。
函数和类的作用域可被视作隐式名字空间,它们和可见性、可访问性和对象生命周期不可分割的联系在一起。
基带和宽带之间的差异
本教程详细解释了基带和宽带传输之间的区别。了解基带和宽带传输是什么,以及它们之间的差异。
基带和宽带都描述了数据如何在两个节点之间传输。基带技术一次传输单个数据信号/流/通道,而宽带技术同时传输多个数据信号/流/通道。
下图显示了这两种技术的示例。

要了解这两种技术之间的基本区别,请将基带视为铁路轨道,将宽带视为高速公路。比如,一次只有一列火车可以在铁路轨道上行驶,在基带传输中,一次只能传输一个数据信号。
与高速公路上的铁路轨道不同,多辆车可以同时行驶。例如,在3车道高速公路上,3辆车可以同时行驶。与高速公路一样,在宽带传输中,多个数据信号可以同时传输。

基带和宽带传输之间的技术差异
基带技术在数据传输中使用数字信号。它直接将二进制值作为不同电压水平的脉冲发送。数字信号可以使用中继器重新生成,以便在减弱之前传播更长的距离,并且由于衰减而无法使用。
基带支持双向通信。这意味着,这项技术可以同时发送和接收数据。为了支持双向通信,该技术同时使用两个独立的电路;一个用于发送,另一个用于接收。
下图显示了这方面的一个例子。

虽然基带一次只传输单个数据流,但可以同时传输多个节点的信号。这是通过将所有信号组合成一个数据流来完成的。为了组合多个节点的信号,使用了一种称为多路复用的技术。基带支持时间划分多路复用(TDM)。
要了解多路复用的类型以及多路复用是如何完成的,您可以查看本教程。
基带技术主要用于以太网网络,用于节点之间的数据交换。这项技术可用于所有三种流行的以太网电缆介质类型:同轴、双绞线、光纤。
宽带传输
宽带技术在数据传输中使用模拟信号。这项技术使用一种称为载波的特殊模拟波。载波不包含任何数据,但包含模拟信号的所有属性。这项技术将数据/数字信号/二进制值混合到载波中,并将载波发送跨信道/介电波。
为了同时传输多个节点的数据,该技术支持频分复用。FDM(频率分复用)将通道(介制或路径)划分为多个子通道,并为每个节点分配一个子通道。每个子通道可以携带单独的载波。
下图显示了这个过程的一个示例。

模拟信号可以使用放大器重新生成,以便长途旅行。
宽带仅支持单向通信。这意味着,在介质两端连接的节点可以发送或接收数据,但不能同时执行这两个操作。一次只允许一个操作。
例如,两个节点A和B通过使用宽带技术传输信号的电缆连接。当节点A传输信号时,节点B接收传输的信号,当节点B传输信号时,节点A接收传输的信号。
下图显示了这个示例。

宽带通常用于同时传输音频、视频和数据的环境中。例如,有线电视网络、广播电台和电话公司。通常,无线电波、同轴电缆、光纤电缆用于宽带传输。
基带和宽带传输的主要区别
| 基带传输 | 宽带传输 |
| 传输数字信号 | 传输模拟信号 |
| 要增强信号强度,请使用中继器 | 要提高信号强度,请使用放大器 |
| 一次只能传输单个数据流 | 一次可以传输多个信号波 |
| 同时支持双向通信 | 仅支持单向通信 |
| 支持基于TDM的多路复用 | 支持基于FDM的多路复用 |
| 使用同轴电缆、双绞线电缆和光纤电缆 | 使用无线电波、同轴电缆和光纤电缆 |
| 主要用于以太网局域网网络 | 主要用于有线和电话网络 |
本教程就到此。在本教程中,我们讨论了基带和宽带传输之间的区别。
吞吐量和带宽之间的差异
本教程详细解释了吞吐量和带宽之间的差异。了解吞吐量和带宽是什么,以及它们之间的差异。
吞吐量和带宽都描述了传输速度。带宽描述介质的信息承载能力,而吞吐量描述该容量的实际使用。
要了解吞吐量和带宽之间的基本区别,请考虑高速公路。如果24辆车可以在一秒钟内在高速公路上通过,那么该高速公路的带宽为每秒24辆车。
但是,在实践中,这种情况从未发生过。汽车不能以保险杠对保险杠模式驾驶。实际可以经过的汽车数量取决于天气、道路状况和灯光等多种情况。如果在给定条件下,一秒钟只能通过20辆车,那么这条高速公路的吞吐量是每秒20辆车。
下图显示了这个示例。

让我们再举一个例子。
文件大小:46兆位
以太网开销(每个数据包包含的额外信息的总和,如标头和拖车):10兆位。
要传输的数据总数:56兆位(46兆位+10兆位)
带宽(最大数据传输速度):56 Mbps
因错误和确认而丢失的数据量:28 Mbps
吞吐量:56 Mbps - 28 Mbps = 28 Mbps
传输整个文件所需的时间:56兆位/28 Mbps = 2秒
吞吐量始终低于带宽。因此,通常以高达100 Mbps、高达1 Gbps等形式提供广告连接速度。
下次,当您订阅新的互联网连接时,请订阅比您要求更高的带宽的连接。例如,如果您需要1Gbps带宽,请订阅提供1.25 Gbps或更高带宽速率的连接。
测量吞吐量和带宽
计算机网络使用两种类型的信号:模拟信号和数字信号传输。数字信号的吞吐量和带宽以比特率衡量。比特率是每秒传输的位数,例如每秒1000位或1Kbps。
下表列出了计算机网络中使用的数字信号的常见比特率。
| 比特率 | 描述 |
| 1bps | 每秒1位 |
| 1Kbps | 每秒1000位 |
| 1Mbps | 每秒1,000,000位 |
| 1Gbps | 每秒1000,000,000位 |
| 1Tbps | 1,000,000,000,000位每秒 |
模拟信号的吞吐量和带宽以波特率测量。波特率是每秒传输的符号数量。符号是模拟传输中的电压、频率、脉冲或相位变化。
计算模拟信号的带宽
模拟信号的带宽是通过从较高的频率中减去较低的频率来计算的。例如,如果电缆可以携带300赫兹到3300赫兹的频率,那么该电缆的带宽为3000赫兹(3300-300)。
让我们再举一个例子,人类可以听到频率范围为300到3000的信号。因此,人类声音的带宽为2700赫兹(3000-300)。
| 频率范围 | 使用者 |
| 535 kHz 为 1605 kHz | AM广播电台 |
| 88至108MHz | FM广播电台 |
| 108至174MHz | 甚高频电缆站 |
| 174 到 216 MHz | 甚高频电视台 |
| 216至470MHz | 超高频电缆站 |
| 470 到 890 MHz | 超高频电视台 |
| 230MHz至3 THz | 雷达 |
更高的频率表示更大的带宽。更大的带宽可以提供更快的传输。
影响带宽和吞吐量的常见因素
传输设备
传输设备将数据转换为信号,并在介质上加载信号。缓慢的传输设备可以降低吞吐率。例如,假设100Mbps带宽的电缆与NIC连接,NIC可以以10Mbps的速度传输数据。在这种情况下,即使电缆的带宽为100Mbbps,传输的带宽也为10 Mbps,实际数据传输速率(吞吐量)将更低。
距离
信号在介质上传播时会失去强度。因此,介质的吞吐量随着距离的增加而下降。放大器(用于模拟信号)和中继器(用于数字信号)用于增加信号的强度。
环境
当信号通过介质传播时,它们的环境会影响它们。例如,EMI(电磁接口)场和串扰影响数字信号,噪声和衰减影响模拟信号,天气和障碍影响无线电波。
本教程就到此。在本教程中,我们讨论了吞吐量和带宽之间的差异。
CSMA/CD和CSMA/CA
本教程详细解释了CSMA/CD和CSMA/CA。了解什么是CSMA/CD和CSMA/CA,它们是如何工作的,以及为什么它们在计算机网络中使用。
什么是CSMA/CD和CSMA/CA?
CSMA/CD和CSMA/CA是管理设备如何将数据传输到网络的媒体访问方法。CSMA/CD代表载波感应多址/碰撞检测。CSMA/CA代表运营商感知多址/避免碰撞。
这两种方法都用于单个碰撞域。单个碰撞域是一组共享碰撞的设备。由于所有设备共享碰撞,因此它们使用一种方法来避免和消除碰撞。根据网络中使用的媒体类型,这种方法被称为CSMA/CD或CSMA/CA。
如果网络使用有线媒体,则此方法称为CSMA/CD。如果网络使用无线介质,则此方法称为CSMA/CA。
CSMA/CD的工作原理
在单个碰撞域中,一次只能发送一个帧。然而,所有NIC都可以同时收听电线上的框架。在NIC将框架放在电线上之前,它首先感应电线,以确保电线上目前没有其他框架。如果是铜线,NIC可以通过检查电线上的电压水平来检测框架。如果是光纤线,NIC可以通过检查电线上的光频率来检测框架。这个过程被称为载人意义。
如果NIC检测到电线上的帧,它会等到帧被传输。NIC只有在检测到电线上没有帧时才会传输帧。有时,两个或多个NIC可能会意外地同时检测到没有帧。例如,两个NIC想要传输帧,而电线上没有框架。由于电线上没有框架,两个NIC都同时将框架放在电线上。这个过程被称为多次访问。
如果两个或多个NIC同时感应到电线,没有看到框架,并且每个NIC都将其框架放在电线上,则会发生碰撞。在这种情况下,铜线的电压水平和光纤线上的光频率会变得混乱。例如,如果两个NIC在电线的电气部分施加相同的电压,电压水平将与只有一个设备不同。两个原始帧变得无法辨认。这个过程被称为碰撞检测。
让我们举一个简单的例子。单个碰撞域中有四台PC。PC-1将数据发送到PC-3。与此同时,PC-2还将数据发送到PC-3。由于PC-1和PC-3同时将框架放在电线上,因此会发生碰撞。
下图显示了这个过程。

如果NIC看到其传输帧的碰撞,他们必须重新发送帧。在这种情况下,碰撞发生时传输帧的每个NIC都会创建一个特殊的信号,称为电线上的堵塞信号。然后,它等待一小段随机时间,并再次感应电线。如果电线上目前没有帧,NIC将重新传输其原始帧。NIC等待的时间以微秒为单位,这是人类无法检测到的延迟。同样,NIC等待的时间也是随机的,以帮助确保当这些NIC重新传输其帧时不会再发生碰撞。您放置在以太网段上的设备越多,您就越有可能遇到碰撞。如果您在细分市场放置太多设备,将发生太多的碰撞,严重影响您的吞吐量。因此,您需要监控每个网络段的碰撞次数。你经历的碰撞越多,你得到的吞吐量就越少。
要点
- 这种机制仅用于单个碰撞域。
- 所有设备都具有同等优先级。
- 在这个过程中,一次只能发送一台设备的数据。
- 在设备发送数据之前,它将首先感应电线,以确保目前没有其他设备在发送数据。如果另一台设备当前正在使用媒体,则必须等到传输结束。如果目前没有设备使用电线,它可以发送数据。
- 如果两个或多个设备同时感应到电线,并且看不到其中的数据,他们可以同时将数据放在电线上。
- 在这种情况下,会发生碰撞。
- 当发生碰撞时,电线会产生特殊的堵塞信号。
- 果酱信号有等待时间。
- 所有设备都必须等到堵塞信号时间结束。
- 一旦结束,设备可以再次感应到电线。
- 如果设备的数据在碰撞中丢失,设备将再次发送相同的数据。
CSMA/CA
无线局域网使用一种称为运营商感应、多次访问/避免碰撞(CSMA/CA)的机制。与以太网不同,无法检测到无线介质中的碰撞。在无线局域网中,设备无法同时发送或接收数据。它只能做其中之一。因此,它无法检测到碰撞。为了避免碰撞,设备将使用随时可发送(RTS)和清除到发送(CTS)信号。当设备准备传输时,它首先感应到电流信号的电波。如果没有,它会生成RTS信号,指示数据即将发送。然后,它通过发送CTS信号发送数据并完成,这表明现在可以传输另一台无线设备。
信息定义
信息可以被宽泛地定义为某些系统(例如生物体、电子系统或机械设备)可以识别的任何模式和/或可能影响其他模式的形成或转换。
该图案可以有多种形式,例如口语或印刷文字、温度、视觉图像、疼痛、放射性、DNA、晶体结构、颜色或电子流动。它可以从极其简单的单个二进制值(例如,是或否,或零或一个)到如此复杂的东西,以至于只有少数人类头脑能够理解它(例如爱因斯坦的相对论)。
信息依赖于用于存储或表达信息的媒体或媒体,但通常与之无关。例如,数学公式或Gilgamesh1的史诗可以编码在烤粘土片2中,打印在一本书中,存储在半导体内存芯片中,或保留在人类的大脑中。信息的定义既不假设其准确性,也不假设模式与感知或使用它的对象或系统之间的任何直接通信。
生物体生来就有编码在基因中的信息,并在不同程度上已经在大脑中编码的信息。然后通过感官输入和与其他生物体交换基因来获得更多信息3。当生物体通过感觉器官接收信息时,它会将输入转化为一系列电气和化学信号,这些信号可能导致存储或使用该信息。
问题是,如果模式不被任何生物或其他系统感知或不影响,它们是否是信息。一个明智的回应是,任何有可能被系统感知或影响系统的东西都可以被视为信息。没有必要有意识的头脑来理解甚至意识到这种模式。例如,DNA是一种影响生物体形成和发展的模式,不需要有意识的头脑(尽管它肯定会影响有意识的头脑)。
物理学中有一种趋势,将物理世界定义为由信息本身组成。这是因为普遍的看法是,宇宙中的一切都最终只是几种基本粒子和/或振动的模式。这些模式(即信息)决定了人类和其他生物体感知的现实。
信息的一个更狭窄但更直接有用的定义是从发件人传递给接收者的信息。这与噪音形成鲜明对比,噪音可以定义为扭曲或抑制信息流动的东西。除了假设发送者和接收者都存在外,这个定义忽略了信息是可以从环境中提取的东西(例如通过观察或测量)的想法,并且对消息的准确性没有假设。
在传奇贝尔实验室的研究员克劳德·香农1948年发表了一篇题为《通信数学理论》的论文后,这种信息概念成为一种信息。这项开创性的工作为信息理解增加了一个定量方面,并为现代信息理论的发展提供了起点。信息理论是一门主要涉及信息量及其传输准确性的数学学科。它具有广泛的应用,特别是在密码学、数据压缩、语言学和电信等领域。
计算机和信息密切相关。事实上,计算机科学本质上只是对信息存储、转换和传输的研究。此外,计算机显然大大增加了处理信息的易用性,包括访问、复制和通信信息,并且他们特别擅长以视觉和音频形式呈现4。
通过用户界面(现在通常包括键盘、鼠标和显示设备)向计算机发出命令正在向计算机提供信息。信息包括一个或多个程序的名称,以及它们的任何选项和参数(即输入数据)一起运行。计算机还从其他来源获取信息,包括存储(例如磁盘和磁带)、其他计算机通过网络以及各种类型的传感器(如扫描仪、相机和麦克风)。
近几个世纪以来,特别是在过去几十年里,人类获得的信息量一直在以越来越快的速度增长,因此,信息时代和信息社会等术语得到了广泛使用。这一加速是(1)世界人口增长以及参与创建和处理信息的人数和组织(如作家、大学和专门研究设施)的增加的结果,以及(2)信息处理、存储和通信技术的快速进步,特别是计算机和电信。幸运的是,这些进步也有助于人类更容易应对这种信息爆炸。
知识是一个经常与信息相关的词。它可以定义为一个人脑海中或社会集体拥有通过经验或学习获得的信息。此外,它还可以包括欣赏许多小信息单元之间的关系,这些信息单位本身效用较小。
文档是用于解释人造物体、系统或程序的某些属性,特别是其组装、安装、维护、维修和处置的任何可传播材料(如文本、视频、音频等或其组合)。然而,信息是一个更具包容性的概念,不仅可以是关于产品(即商品或服务),还可以涉及任何主题。当信息是关于产品的时,除了文件涵盖的方面外,它还可以涵盖其各个方面,包括其历史、政治、哲学、科学、社会学、商业、经济和环境方面。
信息的制作、处理、存储和分发成本可能很高。它越来越多地被视为一种商品,像其他商品和服务一样在竞争激烈的市场上买卖,而不是被牧师阶级囤积(这在人类历史上的大部分时间里都很常见)或免费赠送。事实上,它已成为世界上最大的行业之一5。
虽然信息成本通常被定义为获取有关产品价格、数量和质量的信息(包括制造商的生产投入)的成本,但它也可以更广泛地解释为包括属于文件类别的信息成本。降低这些成本显然可以使消费者和生产商在购买中获得最佳价值,并使产品更容易使用。近年来,在降低信息成本方面取得的最大进展之一是互联网的发展。
信息科学主要是一种应用工程,涉及信息的结构、创建、管理、存储、检索和传输,特别是对于大型组织。它可以被认为是计算机科学结果的一个更直接的实用分支,计算机科学是一门更具理论性的学科。
端口号常识
TCP 端口是分配给不同应用程序的唯一编号。例如,我们在计算机上打开了电子邮件和游戏应用程序;通过邮件申请,我们想给主机发邮件,通过游戏申请,我们想玩网络游戏。为了完成所有这些任务,为这些应用程序分配了不同的唯一编号。每个协议和地址都有一个称为端口号的端口。TCP(传输控制协议)和UDP(用户数据报协议)协议主要使用端口号。
端口号是与 IP 地址一起使用的唯一标识符。一个端口是一个 16 位无符号整数,TCP/IP 模型中可用的端口总数为 65,535 个端口。因此,端口号的范围是 0 到 65535。在 TCP 的情况下,零端口号是保留的,不能使用,而在 UDP 中,零端口号是不可用的。IANA(互联网编号分配机构)是分配端口号的标准机构。
端口号示例:
192.168.1.100:7
在上述情况下,192.168.1.100是 IP 地址,7是端口号。
要访问特定服务,端口号与 IP 地址一起使用。0 到 1023 的端口号范围是为标准协议保留的,其他端口号是用户自定义的。
为什么我们需要端口号?
单个客户端可以与同一台服务器或多台服务器建立多个连接。客户端可能同时运行多个应用程序。当客户端尝试访问某些服务时,IP 地址不足以访问该服务。要从服务器访问服务,需要端口号。因此,传输层通过为应用程序分配端口号,在这些应用程序之间提供多种通信方面发挥着重要作用。
端口号分类
端口号分为三类:
- 知名港口
- 注册端口
- 动态端口
知名港口
知名端口的范围是 0 到 1023。知名端口与服务于常见应用程序和服务的协议一起使用,例如 HTTP(超文本传输协议)、IMAP(Internet 消息访问协议)、SMTP(简单邮件传输)协议)等。例如,我们要访问互联网上的一些网站;然后,我们使用http协议;http 可用端口号 80,这意味着当我们将 http 协议与应用程序一起使用时,它会获得端口号 80。它定义了每当使用 http 协议时,将使用端口号 80。同样,与其他协议如 SMTP、IMAP;定义了众所周知的端口。其余端口号用于随机应用程序。
注册端口
注册端口的范围是 1024 到 49151。注册端口用于用户进程。这些进程是单独的应用程序,而不是具有众所周知的端口的通用应用程序。
动态端口
动态端口的范围是 49152 到 65535。动态端口的另一个名称是临时端口。当客户端创建连接时,这些端口号会动态分配给客户端应用程序。动态端口在客户端发起连接时被识别,而客户端在连接之前就知道众所周知的端口。当客户端连接到服务时,客户端不知道此端口。
TCP 和 UDP 标头
众所周知,TCP 和 UDP 都包含源端口号和目标端口号,这些端口号用于标识源端和目标端的应用程序或服务器。TCP 和 UDP 都使用端口号将信息传递给上层。
让我们了解一下这种情况。
假设客户正在访问一个网页。TCP 标头包含源端口和目标端口。
客户端
在上图中,
源端口:源端口定义了TCP段所属的应用程序,该端口号由客户端动态分配。这基本上是分配端口号的进程。
目的端口:目的端口标识了服务在服务器上的位置,以便服务器可以服务于客户端的请求。
服务器端
在上图中,
源端口:它定义了 TCP 段来自的应用程序。
目标端口:它定义了 TCP 段要到达的应用程序。
在上述情况下,使用了两个过程:
封装:发送方使用端口号告诉接收方应该使用哪个应用程序来处理数据。
解封装:接收方使用端口号来识别应该将数据发送到哪个应用程序。
让我们通过使用所有三个端口,即知名端口、注册端口和动态端口来理解上面的示例。
首先,我们来看一个著名的港口。
众所周知的端口是服务于常见服务和应用程序的端口,如 http、ftp、smtp 等。这里,客户端使用众所周知的端口作为目标端口,而服务器使用众所周知的端口作为源端口港口。例如,客户端发送一个 http 请求,那么在这种情况下,目标端口将是 80,而 http 服务器正在为请求提供服务,因此其源端口号将是 80。
现在,我们看一下注册的端口。
注册的端口被分配给非通用应用程序。许多供应商应用程序使用此端口。与众所周知的端口一样,客户端将此端口用作目标端口,而服务器将此端口用作源端口。
最后,我们看看动态端口在这个场景中是如何工作的。
动态端口是在启动连接时动态分配给客户端应用程序的端口。在这种情况下,客户端使用动态端口作为源端口,而服务器使用动态端口作为目标端口。比如客户端发送一个http请求;那么在这种情况下,目标端口将是 80,因为它是一个 http 请求,源端口将仅由客户端分配。当服务器为请求提供服务时,源端口将是 80,因为它是一个 http 服务器,目标端口将与客户端的源端口相同。注册端口也可以用来代替动态端口。
让我们看看下面的例子。
假设客户端正在与服务器通信,并发送 http 请求。因此,客户端将 TCP 段发送到众所周知的端口,即 HTTP 协议的 80。在这种情况下,目的端口为 80,假设客户端动态分配的源端口为 1028。当服务器响应时,目的端口为 1028,因为客户端定义的源端口为 1028,源端口在服务器端将是 80,因为 HTTP 服务器正在响应客户端的请求。
端口号规范
端口
- 10010- 62490
结构
- A BCD E管理控制台 443:X001
内外网
内网端口号:实际协议表
什么是内网IP地址?
内网,也叫局域网,从范围上来讲,内网就是小部分的网络,一般指特定环境下组成的网络。比如一个家庭多台计算机互联成的网络,也可以是学校和公司内部的大型局域网。内网如果需要访问外网,可以通过路由器连接。内网的IP地址一般都是192.168.1.100,172.18.8.101,10.8.10.10……是在IPv4地址协议中预留了3个IP地址段,作为私有地址,供组织机构内部使用。
IPv4内网地址:
| 网络类别 | ip地址范围 | ip地址数 |
|---|
|
端口号
|
协议
|
网络服务
|
来源
|
目的地
|
用途
|
|
53
|
UDP
|
DNS
|
本软件
|
DNS 服务器
|
设备发现
|
|
80
|
TCP
|
HTTP
|
本软件
|
设备
|
显示远程用户界面
|
|
137
|
UDP
|
NetBIOS 名称解析
|
本软件
|
DNS 服务器
|
设备发现
|
|
161
|
UDP
|
SNMP
|
本软件
|
设备
|
设备发现
检索设备功能信息
检索设备配置信息
检索 MIB 计数器信息
检索标记(碳粉/墨水)信息
|
|
443*1
|
TCP
|
HTTPS
|
客户端计算机
|
本软件
|
从 Web 浏览器访问本软件(加密通信)
|
|
443
|
TCP
|
HTTPS
|
本软件
|
远程监控服务器
|
发送各种数据
|
|
5355
|
LLMNR
|
DNS(相当于 mDNS)
|
本软件
|
外部计算机
|
设备发现
|
|
8000
|
TCP
|
HTTP
|
本软件
|
设备
|
显示远程用户界面
|
|
8080
|
TCP
|
HTTP
|
本软件
|
设备
|
显示远程用户界面
|
|
9007
|
TCP
|
Canon Original
|
本软件
|
设备
|
检索记录信息
(报警记录/服务呼叫记录/卡纸记录/条件记录)
|
|
11427
|
UDP
|
Canon Original
|
设备
|
本软件
|
电源状态通知
|
|
47545*1
|
UDP
|
Canon Original
|
设备
|
本软件
|
状态变化
时间通知
记录写入事件通知
|
|
47545
|
UDP
|
Canon Original
|
本软件
|
设备
|
检索计数器信息
(服务模式计数器、所有资源计数器、部门计数器、模式计数器和部件计数器)
检索设备功能信息
检索序列号/扩展序列号信息、标记(碳粉/墨水)信息、固件信息和碳粉瓶 ID
将设备从睡眠模式中恢复的通知
|
|
47546
|
TCP
|
Canon Original
|
本软件
|
设备
|
检索记录信息
(报警记录/服务呼叫记录/卡纸记录/条件记录)
|
|
自动指定*2
|
TCP
|
Canon Original
|
设备
|
本软件
|
使用 Canon 原始协议/TCP 响应请求
|
|
自动指定*2
|
UDP
|
Canon Original
|
设备
|
本软件
|
使用 Canon 原始协议/UDP 响应请求
|
|
自动指定*2
|
UDP
|
SNMP
|
设备
|
本软件
|
使用 SNMP/UDP 响应请求
|
域名系统
域名可作为Internet 上网站和其他服务的可记忆名称。但是,计算机通过其 IP 地址访问 Internet 设备。DNS 将域名转换为IP 地址,允许您通过域名访问 Internet 位置。
多亏了 DNS,您可以通过输入域名而不是 IP 地址来访问网站。例如,要访问技术术语计算机词典,您只需在Web 浏览器的地址栏中输入“techterms.com”,而不是 IP 地址 (67.43.14.98)。它还简化了电子邮件地址,因为 DNS 将域名(在“@”符号之后)转换为适当的 IP 地址。
要了解 DNS 的工作原理,您可以将其视为智能手机上的联系人应用程序。当您打电话给朋友时,您只需从列表中选择他或她的名字。电话实际上并没有按姓名呼叫该人,而是呼叫该人的电话号码。DNS 通过将唯一的 IP 地址与每个域名相关联以相同的方式工作。
与您的地址簿不同,DNS 转换表不存储在单个位置。相反,数据存储在全球数百万台服务器上。域名注册时,必须至少分配两个域名服务器(可以随时通过域名注册商进行编辑)。名称服务器地址指向具有域名目录及其相关 IP 地址的服务器。当计算机通过 Internet 访问网站时,它会找到相应的名称服务器并获取该网站的正确 IP 地址。
由于 DNS 转换在连接到网站时会产生额外的开销,因此ISP会缓存DNS 记录并在本地托管数据。一旦域名的 IP 地址被缓存,ISP 可以自动将后续请求定向到相应的 IP 地址。这在 IP 地址更改之前非常有效,在这种情况下,请求可能会发送到错误的服务器,或者服务器根本不会响应。因此,DNS 缓存会定期更新,通常在几小时到几天之间。
Domain Name
域名是标识网站的唯一名称。例如,技术术语计算机词典的域名是“techterms.com”。每个网站都有一个域名作为地址,用于访问网站。
每当您访问网站时,域名都会出现在网络浏览器的地址栏中。一些域名以“www”开头(这不是域名的一部分),而另一些则省略了“www”前缀。所有域名都有一个域名后缀,例如 .com、.net 或 .org。域名后缀有助于识别域名所代表的网站类型。例如,“.com”域名通常由商业网站使用,而“.org”网站通常由非营利组织使用。一些域名以国家代码结尾,例如“.dk”(丹麦)或“.se”(瑞典),这有助于识别网站的位置和受众。
域名注册成本相对较低,但必须每年或每隔几年更新一次。好消息是任何人都可以注册域名,因此您可以为您的博客或网站购买一个唯一的域名。坏消息是,几乎所有具有常用词的域名都已注册。因此,如果您想注册一个自定义域名,您可能需要考虑一个创造性的变体。一旦您决定一个域名并注册它,该名称就是您的,直到您停止更新它。当续订期到期时,该域名可供其他人购买。
注意:当您访问一个网站时,域名实际上被转换为一个IP 地址,它定义了该网站所在的服务器。此转换由名为DNS的服务动态执行。
IP Address
IP 地址或简称“IP”是标识Internet或本地网络上的设备的唯一地址。它允许一个系统被通过Internet 协议连接的其他系统识别。目前使用的 IP 地址格式主要有两种类型 - IPv4和IPv6。
IPv4
IPv4 地址由从 0 到 255 的四组数字组成,由三个点分隔。例如,TechTerms.com 的 IP 地址是 67.43.14.98。此号码用于识别 Internet 上的 TechTerms 网站。当您在网络浏览器中访问 http://techterms.com 时,DNS系统会自动将域名“techterms.com”翻译成 IP 地址“67.43.14.98”。
可以通过InterNIC注册三类 IPv4 地址集。最小的是 C 类,它由 256 个 IP 地址组成(例如,123.123.123.xxx — 其中 xxx 是 0 到 255)。其次是 B 类,它包含 65,536 个 IP 地址(例如 123.123.xxx.xxx)。最大的块是 A 类,它包含 16,777,216 个 IP 地址(例如 123.xxx.xxx.xxx)。
IPv4 地址的总数范围从 000.000.000.000 到 255.255.255.255。因为 256 = 2 8,所以有 2 8 x 4或 4,294,967,296 个可能的 IP 地址。虽然这可能看起来很大,但它已不足以涵盖全球所有连接到 Internet 的设备。因此,现在很多设备都使用 IPv6 地址。
IPv6
IPv6 地址格式与 IPv4 格式有很大不同。它包含八组四个十六进制数字,并使用冒号分隔每个块。IPv6 地址的一个示例是:2602:0445:0000:0000:a93e:5ca7:81e2:5f9d。有 3.4 x 10 38或 340 undecillion) 可能的 IPv6 地址,这意味着我们不应该很快用完 IPv6 地址。
InterNIC
代表“互联网网络信息中心”。InterNIC 是美国国家科学基金会创建的提供互联网信息和域名注册服务的组织。虽然 InterNIC 是由 Network Solutions 和 AT&T 共同发起的,但它现在由 Internet Corporation For Assigned Names and Numbers (ICANN) 运营。
虽然 InterNIC 仍在监控域名并提供WHOIS数据,但域名注册过程已交给商业域名注册商。可以在InterNIC 网站上访问有关域名、注册商和其他 Internet 相关数据的公共信息。
WHOIS
一种用于查找有关域名信息的 Internet 服务。虽然该术语大写,但“WHOIS”不是首字母缩略词。相反,它是“谁负责这个域名?”这个问题的缩写。
域名是通过称为注册商的公司注册的。示例包括 GoDaddy、Tucows、Namecheap 和 MarkMonitor。这些公司已获得ICANN的批准和认可,可以注册新域名。每当个人或组织注册新域名时,注册服务机构都必须公开注册信息。可以使用 WHOIS 服务在线查找此信息。
由于没有域注册信息的中央数据库,WHOIS搜索引擎会跨多个注册商查找数据。许多注册商都提供自己的 WHOIS 查询服务,但也存在一些第三方WHOIS 网站。ICANN 也提供自己的 WHOIS 查询服务(见图)。
什么是 WHOIS 记录?
WHOIS 记录因注册商而异,但都包含强制性信息。这包括注册商的名称、创建日期、更新日期和域名的到期日期。还列出了名称服务器。包括三个联系人——注册人、管理员和技术联系人。此信息在注册期间提供,包括姓名、组织(如果适用)、地址、电话号码和电子邮件地址。在许多情况下,所有三个联系人的信息都是重复的,尽管每个联系人可能有不同的信息。
注意:可以使用某些注册商提供的“私人注册”服务将 WHOIS 记录中的联系信息设为私人信息。该服务可能需要额外付费才能使用,它会使用非个人身份信息掩盖注册人的联系信息。使用域隐私注册的域仍会显示在 WHOIS 搜索中,但该组织可能会显示为“Whois 隐私服务”和电子邮件地址“ abcd1234@whoisprivacyservices.com ” 。
Name Server
名称服务器将域名转换为IP 地址。这使得用户可以通过输入域名而不是网站的实际 IP 地址来访问网站。例如,当您键入“www.microsoft.com”时,请求将被发送到 Microsoft 的名称服务器,该服务器返回 Microsoft 网站的 IP 地址。
在注册域时,每个域名必须至少列出两个名称服务器。这些名称服务器通常命名为 ns1.servername.com 和 ns2.servername.com,其中“servername”是服务器的名称。列出的第一台服务器是主服务器,而如果第一台服务器没有响应,则第二台服务器用作备用服务器。
名称服务器是域名系统 ( DNS ) 的基本组成部分。它们允许网站使用域名而不是 IP 地址,这将更难记住。为了找出某个域名的名称服务器是什么,您可以使用WHOIS 查询工具。
ICANN
代表“Internet Corporation For Assigned Names and Numbers”。ICANN 是一家非营利性公司,负责分配IP 地址和管理域名系统。
每台连接到 Internet 的计算机,从服务器到家用 PC,都有一个 IP 地址。但是,ICANN 直接为每台计算机分配一个单独的 IP 地址是不现实的。相反, ICANN 将 IP 地址块分配给公司、教育机构和互联网服务提供商。然后,这些组织将 IP 地址分配给使用其 Internet 连接的计算机。
虽然 ICANN 是一家总部位于美国的组织,但它也是一个全球互联网社区。根据 ICANN 的网站,该组织“致力于维护互联网的运营稳定性;促进竞争;实现全球互联网社区的广泛代表性;并通过自下而上、基于共识的流程制定适合其使命的政策” ( icann.org )。
Domain Suffix
域后缀是域名的最后一部分,通常被称为“顶级域”或 TLD。流行的域后缀包括“.com”、“.net”和“.org”,但ICANN批准的域后缀有几十个。
每个域后缀旨在定义域名所代表的网站类型。例如,“.com”域用于商业网站,而“.org”域用于组织。但是,由于任何实体都可以使用这些后缀注册域名,因此域名后缀并不总是代表使用该域名的网站类型。例如,许多个人和组织出于非商业目的注册“.com”域名,因为“.com”域名是最受认可的。
每个国家/地区还有一个唯一的域后缀,用于该国境内的网站。例如,巴西网站可能使用“.br”域名后缀,中国网站可能使用“.cn”后缀,澳大利亚网站可能使用“.au”后缀。这些基于国家/地区的 TLD,有时称为“国家代码”,也用于指定国际网站的不同版本。例如,Google 的德语主页是“www.google.de”而不是“www.google.com”。
Web Host
网络主机存储您网站的所有页面,并使它们可供连接到 Internet 的计算机使用。域名(例如“sony.com”)实际上链接到指向特定计算机的IP 地址。当有人在其浏览器的地址字段中输入您的域名时,IP 地址就会被定位并从您的 Web 主机加载网站。
Web 主机可以在任何地方拥有从一台到数千台运行 Web 托管软件的计算机,例如 Apache、OS X Server 或 Windows Server。您在 Web 上看到的大多数网站都是从“共享主机”访问的,这是一台可以托管数百个网站的计算机。较大的网站通常使用“专用主机”,这是一台仅托管一个网站的机器。具有极高流量的站点(例如 apple.com 或 microsoft.com)使用多台计算机来托管一个站点。
如果您想发布自己的网站,则需要注册“网络托管服务”。找到一个好的 Web 主机应该不会太难,因为它们有数千种可用。只需确保您选择的 Web 主机提供良好的技术支持并确保很少或没有停机时间。您通常需要按月支付费用,具体取决于您的站点将使用多少磁盘空间和带宽。因此,在注册 Web 托管服务之前估计您的网站有多大以及您期望的流量是一个好主意。
Backbone
骨干就像人类的骨干将信号传送到体内许多较小的神经一样,网络骨干将数据传送到较小的传输线路。本地骨干网是指将多个局域网 ( LAN ) 连接在一起的主要网络线路。结果是由主干连接链接的广域网 ( WAN )。
互联网是终极的广域网,依靠骨干网长距离传输数据。互联网骨干网由几个超高带宽连接组成,这些连接将世界各地的许多不同节点连接在一起。这些节点将传入数据路由到本地区域中的较小网络。您的数据在到达主干之前需要进行的“跳跃”越少,它就会越快发送到目的地。这就是为什么许多Web 主机和ISP直接连接到 Internet 骨干网的原因。
ISP
代表“互联网服务提供商”。ISP 提供对 Internet 的访问。无论您是在家还是在工作,每次连接到 Internet 时,您的连接都会通过 ISP 进行路由。
早期的 ISP 通过拨号调制解调器提供 Internet 访问。这种类型的连接通过普通电话线进行,并且限制为 56 Kbps。1990 年代后期,ISP 开始通过DSL和电缆调制解调器提供更快的宽带互联网接入。一些 ISP 现在提供高速光纤连接,通过光缆提供 Internet 访问。Comcast 和 Cox 等公司提供有线连接,而 AT&T 和 Verizon 等公司提供 DSL 互联网接入。
要连接到 ISP,您需要一个调制解调器和一个活动帐户。当您将调制解调器连接到您家中的电话或电缆插座时,它会与您的 ISP 进行通信。ISP 验证您的帐户并为您的调制解调器分配一个IP 地址。获得 IP 地址后,您就可以连接到 Internet。您可以使用路由器(可能是单独的设备或内置在调制解调器中)将多个设备连接到 Internet。由于每台设备都通过同一个调制解调器进行路由,因此它们都将共享由 ISP 分配的同一个公共 IP 地址。
ISP 充当 Internet 上的集线器,因为它们通常直接连接到 Internet主干。由于 ISP 处理大量流量,它们需要到 Internet 的高带宽连接。为了向客户提供更快的速度,ISP 必须为其骨干连接增加更多带宽,以防止出现瓶颈。这可以通过升级现有生产线或添加新生产线来完成。
Bandwidth
带宽描述了网络或Internet连接的最大数据传输率。它测量在给定时间内可以通过特定连接发送多少数据。例如,千兆以太网连接的带宽为 1,000 Mbps(每秒 125 兆字节)。通过电缆调制解调器的 Internet 连接可以提供 25 Mbps 的带宽。
虽然带宽用于描述网络速度,但它并不能衡量数据位从一个位置移动到另一个位置的速度。由于数据包通过电子或光纤电缆传输,因此传输的每个比特的速度可以忽略不计。相反,带宽衡量的是一次可以流过特定连接的数据量。
在可视化带宽时,将网络连接视为管道,将每一位数据视为一粒沙子可能会有所帮助。如果将大量沙子倒入细管中,沙子需要很长时间才能流过。如果将相同数量的沙子倒入宽管中,沙子将更快地流过管子。同样,当您拥有高带宽连接而不是低带宽连接时,下载将更快地完成。
数据经常流经多个网络连接,这意味着带宽最小的连接会成为瓶颈。通常,Internet主干和服务器之间的连接具有最大的带宽,因此它们很少成为瓶颈。相反,最常见的 Internet 瓶颈是您与ISP的连接。
注意:带宽也指用于传输信号的频率范围。这种类型的带宽以赫兹为单位,在信号处理应用中经常被引用。
Mbps
代表“每秒兆比特”。一兆比特等于一百万比特或 1,000 千比特。虽然“兆位”听起来类似于“兆字节”,但兆位大约是兆字节大小的八分之一(因为一个字节中有八位)。Mbps 用于测量高带宽连接的数据传输速度,例如以太网和电缆调制解调器
External Hard Drive
外置硬盘几乎所有的个人电脑都带有内置硬盘。此驱动器存储计算机的操作系统、程序和其他文件。对于大多数用户来说,内部硬盘驱动器提供了足够的磁盘空间来存储所有程序和文件。但是,如果内部硬盘驱动器已满或用户想要备份内部硬盘驱动器上的数据,外部硬盘驱动器可能会有用。
外部硬盘驱动器通常具有两个接口之一 - USB或Firewire。USB 硬盘驱动器通常使用 USB 2.0 接口,因为它支持高达 480 Mbps 的数据传输速率。USB 1.1 仅支持最高 12 Mbps 的传输,即使是最有耐心的人也会觉得硬盘驱动器很慢。Firewire 驱动器可以使用 Firewire 400 或 Firewire 800,它们分别支持高达 400 和 800 Mbps的数据传输率。
最有可能需要外部硬盘驱动器的用户是那些进行音频和视频编辑的用户。这是因为高质量的媒体文件甚至可以填满最大的硬盘。幸运的是,外部硬盘驱动器可以菊花链式连接,这意味着它们可以一个接一个地连接并同时使用。这允许几乎无限量的存储。
不需要额外存储空间的用户可能仍会发现外部硬盘驱动器可用于备份其主硬盘驱动器。外部硬盘驱动器是一个很好的备份解决方案,因为它们可以存储另一个硬盘驱动器的精确副本,并且可以存储在安全的位置。使用该驱动器恢复数据或执行另一次备份就像将其连接到计算机并将必要的文件从一个驱动器拖到另一个驱动器一样简单。
虽然大多数外部硬盘驱动器都装在沉重的保护套中,但有些硬盘驱动器主要是为便携而设计的。这些驱动器的数据量通常不如大型台式机驱动器,但它们具有时尚的外形,可以轻松地与笔记本电脑一起运输。一些便携式驱动器还包括安全功能,例如指纹识别,可防止其他人访问驱动器上的数据,以防万一丢失。
IEEE
代表“电气和电子工程师协会”,生产“I Triple E”。IEEE 是一个开发、定义和审查电子和计算机科学标准的专业协会。其使命是“促进技术创新和卓越,造福人类”。
IEEE 的历史可以追溯到 1800 年代电力开始影响社会的时候。1884 年,成立了 AIEE(美国电气工程师学会)以支持电气创新。1912 年,IRE(无线电工程师协会)成立,旨在制定无线电报标准。1963 年,这两个组织合并成为一个单一的实体——IEEE。从那时起,该组织已经为消费电子、计算机和电信建立了数千个标准。
虽然电气和电子工程师协会位于美国,但 IEEE 标准通常会成为国际标准。以下是 IEEE 标准化的一些技术示例。
- IEEE 1284(并行端口)——早期台式 PC 使用的 I/O 接口
- IEEE 1394 (Firewire) – 专为外部硬盘驱动器、数码摄像机和其他 A/V 外围设备设计的高速接口
- IEEE 802.11 (Wi-Fi) – 一系列用于无线网络的Wi-Fi标准
- IEEE 802.16 (WiMAX) – 用于传输蜂窝数据的无线通信标准
IEEE 为个人、团体和公司提供广泛的成员资格选择。IEEE 知识小组是由成员和志愿者推动的社区,可帮助个人增加对各种主题的了解。成员还可以提供想法和反馈,以帮助 IEEE 起草和建立新的技术标准。
VLAN
代表“虚拟局域网”或“虚拟局域网”。VLAN 是从一个或多个现有LAN创建的自定义网络。它使来自多个网络(有线和无线)的设备组能够组合成一个逻辑网络。结果是可以像物理局域网一样管理的虚拟 LAN。
为了创建虚拟局域网,路由器和交换机等网络设备必须支持 VLAN 配置。硬件通常使用允许网络管理员自定义虚拟网络的软件管理工具进行配置。管理软件可用于将交换机上的单个端口或端口组分配给特定的 VLAN。例如,交换机 #1 上的端口 1-12 和交换机 #2 上的端口 13-24 可以分配给同一个 VLAN。
假设一家公司在一栋大楼内拥有三个部门——财务、营销和开发。即使这些组分布在多个位置,也可以为每个位置配置 VLAN。例如,财务团队的每个成员都可以分配到“财务”网络,营销或开发团队无法访问该网络。这种类型的配置限制了对机密信息的不必要访问,并在局域网内提供了额外的安全性。
VLAN 协议
由于来自多个 VLAN 的流量可能通过同一物理网络传输,因此数据必须映射到特定网络。这是使用 VLAN协议完成的,例如 IEEE 802.1Q、Cisco 的 ISL 或 3Com 的 VLT。大多数现代 VLAN 使用IEEE 802.1Q 协议,该协议在每个以太网帧中插入一个额外的标头或“标签” 。该标签标识发送设备所属的 VLAN,防止数据被路由到虚拟网络之外的系统。数据使用称为“主干”的物理链路在交换机之间发送,该物理链路将交换机连接在一起。必须启用中继,以便一台交换机将 VLAN 信息传递给另一台交换机。
使用 802.1Q 协议可以在以太网中创建 4,904 个 VLAN,但在大多数网络配置中,只需要几个 VLAN。无线设备可以包含在 VLAN 中,但它们必须通过连接到 LAN 的无线路由器进行路由。
LAN
代表“局域网”,发音为“局域网”。LAN 是存在于特定位置的连接设备的网络。LAN 可以在家庭、办公室、教育机构和其他区域中找到。
LAN 可以是有线的、无线的或两者的组合。标准有线 LAN 使用以太网将设备连接在一起。无线 LAN 通常是使用Wi-Fi信号创建的。如果路由器同时支持以太网和 Wi-Fi 连接,则它可用于创建具有有线和无线设备的 LAN。
局域网的类型
大多数住宅 LAN 使用单个路由器来创建网络并管理所有连接的设备。路由器充当中央连接点,使计算机、平板电脑和智能手机等设备能够相互通信。通常,路由器连接到电缆或DSL调制解调器,它为连接的设备提供 Internet 访问。
计算机也可以是 LAN 的中央接入点。在此设置中,计算机充当服务器,为连接的机器提供对位于服务器上的文件和程序的访问权限。它还包括用于管理网络和连接设备的 LAN 软件。LAN 服务器在商业和教育网络中更为常见,因为大多数家庭用户不需要额外的功能。在基于服务器的 LAN 中,设备可以直接连接到服务器,也可以通过路由器或交换机间接连接。
注意:可以组合多个 LAN 以创建更大的 LAN。这种类型的网络可以定制为包括来自各种网络的特定设备,称为虚拟 LAN 或VLAN。
Ad Hoc Network
“Ad Hoc”实际上是一个拉丁短语,意思是“为此目的”。它通常用于描述为特定目的即时开发的解决方案。在计算机网络中,自组织网络是指为单个会话建立的网络连接,不需要路由器或无线基站。
例如,如果您需要将文件传输到朋友的笔记本电脑,您可能会在您的计算机和他的笔记本电脑之间创建一个 ad hoc 网络来传输文件。这可以使用以太网交叉电缆或计算机的无线卡相互通信来完成。如果您需要与多台计算机共享文件,您可以设置一个多跳自组网络,该网络可以在多个节点上传输数据。
基本上,自组织网络是为特定目的(例如将数据从一台计算机传输到另一台计算机)而创建的临时网络连接。如果网络设置时间较长,则它只是一个普通的旧局域网 ( LAN )。
File Format
文件格式定义了存储在文件中的数据的结构和类型。典型文件的结构可能包括标题、元数据、保存的内容和文件结束 (EOF) 标记。存储在文件中的数据取决于文件格式的用途。一些文件(例如XML文件)用于存储项目列表,而其他文件(例如JPEG图像文件)仅包含数据块。
文件格式还定义了数据是以纯文本格式还是二进制格式存储。纯文本文件可以在标准文本编辑器中打开和查看。虽然基于文本的文件很容易创建,但它们通常比可比较的二进制文件占用更多的空间。它们也缺乏安全性,因为可以通过将文件拖到文本编辑器来轻松查看内容。二进制文件格式可以压缩,非常适合存储图形、音频和视频数据。如果您尝试在文本编辑器中查看二进制文件,大多数数据将出现乱码和难以理解,但您可能会看到一些标识文件内容的标题文本。
一些文件格式是专有的,而另一些是通用的或开放格式。专有文件格式只能由一个或多个相关程序打开。例如,压缩的 StuffIt X ( .SITX ) 存档只能由 StuffIt Deluxe 或 StuffIt Expander 打开。如果您尝试使用 WinZip 或其他文件解压缩工具打开 StuffIt X 存档,将无法识别该文件。相反,开放文件格式是公开可用的,并且可以被多个程序识别。例如,StuffIt Deluxe 还可以将压缩档案保存为标准压缩 ( .ZIP ) 格式,几乎所有解压缩实用程序都可以打开该格式。
当软件开发人员创建保存文件的应用程序时,选择合适的文件格式很重要。对于某些程序,使用与其他应用程序兼容的开放格式可能是有意义的。在其他情况下,使用专有格式可能会给开发人员带来竞争优势,因为使用程序创建的文件只能使用开发人员的软件打开。但是,大多数人更喜欢拥有多种软件选项,因此许多开发人员已经放弃了专有文件格式,现在改用开放格式。例如,以前以专有.DOC格式保存文字处理文档的 Microsoft Word现在以打开的.DOCX格式保存文档格式,由多个应用程序支持。
注意:虽然术语“文件格式”在技术上指的是文件的结构和内容,但该术语也可与“文件类型”互换使用,“文件类型”定义了特定类型的文件,例如富文本文件或 Photoshop 文档.
Component
组件 计算机由许多不同的部分组成,例如主板、CPU、RAM和硬盘驱动器。这些部分中的每一个都由称为组件的较小部分组成。
例如,主板包括电连接器、印刷电路板 ( PCB )、电容器、电阻器和变压器。所有这些组件一起工作,使主板与计算机的其他部分一起工作。CPU 包括集成电路、开关和极小的晶体管等组件。这些组件处理信息并执行计算。
一般而言,组件是更大组的元素。因此,计算机的较大部分,例如 CPU 和硬盘驱动器,也可以称为计算机组件。然而,从技术上讲,组件是构成这些设备的较小部件。
分量也可以指分量视频,它是一种高质量的视频连接。组件连接通过三根单独的电缆发送视频信号——一根用于红色、绿色和蓝色。这比复合视频(通常是黄色连接器)提供更好的色彩准确度,复合视频将所有色彩信号组合到一根电缆中。
Port
在计算机世界中,“端口”一词具有三种不同的含义。它可以指 1)硬件端口,2) Internet端口号,或 3) 将软件程序从一个平台移植到另一个平台的过程。
1.硬件端口
硬件端口是计算机或其他电子设备上的物理连接。现代台式计算机上的常见端口包括USB、Thunderbolt、以太网和 DisplayPort。前几代计算机使用不同的端口,例如串行端口、并行端口和VGA端口。移动设备通常只有一个端口。例如,iPhone 或 iPad 可能只有一个Lightning接口。Android 设备通常具有USB-C端口。
硬件端口的目的是为设备提供连接和/或电力。例如,计算机上的 USB 端口可用于连接键盘、鼠标、打印机或其他外围设备。智能手机上的 USB-C 端口可用于为设备充电并与PC同步。
注意:硬件端口也可以称为接口、插孔或连接器。
2. Internet 端口号
通过 Internet 传输的所有数据都是使用一组特定的命令(也称为协议)发送和接收的。每个协议都分配有一个特定的端口号。例如,所有通过HTTP传输的网站数据使用端口 80。通过HTTPS传输的数据使用端口 443。其他常见端口包括:
- 端口 20 - FTP(文件传输协议)
- 端口 22 - SSH和 SFTP
- 端口 25 - SMTP(外发电子邮件)
- 端口 465 - SSL 上的 SMTP
- 端口 143 - IMAP(传入电子邮件)
- 端口 993 - 基于 SSL 的 IMAP
端口号类似于无线信道,因为它们可以防止不同协议之间的冲突。它们还提供了一种实现网络安全措施的简单方法,因为可以允许或阻止特定协议。
3. 移植软件
“端口”也可以用作动词。移植软件意味着采用为一个平台编写的应用程序并使其在另一个平台上运行。例如,可以将Windows程序移植到macOS 上。iOS应用程序可能会移植到Android上。
为了将程序从一个平台移植到另一个平台,必须针对相应的硬件和操作系统编写它。使用通用开发环境构建的程序可能相对容易移植,而严重依赖操作系统API的程序可能必须完全重写。
ASCII
代表“美国信息交换标准代码”。ASCII 是一种字符编码,它使用数字代码来表示字符。其中包括大写和小写英文字母、数字和标点符号。
标准 ASCII
标准 ASCII 可以表示 128 个字符。它使用 7位来表示每个字符,因为字节的第一位始终为 0。例如,大写“T”由 84 表示,或二进制中的 01010100 。小写的“t”用二进制的 116 或 01110100 表示。其他键盘键也映射到标准 ASCII 值。例如,ASCII 中的Escape 键(ESC) 是 27,而Delete 键(DEL) 是 127。
扩展的 ASCII
标准 ASCII 支持的 128 (2 7 ) 个字符足以表示所有标准英文字母、数字和标点符号。但是,仅表示所有特殊字符和来自其他语言的字符是不够的。扩展 ASCII 通过添加额外的 128 个值(总共 256 (2 8 ) 个字符)来帮助解决此问题。附加的二进制值以 1 而不是 0 开头。例如,在扩展的 ASCII 中,字符“é”由 233 或二进制的 11101001 表示。大写字母“Ö”用 214 表示,或二进制的 11010110。
虽然扩展 ASCII 是标准 ASCII 字符集的两倍,但它包含的字符几乎不足以支持所有语言。例如,某些亚洲语言需要数千个字符。因此,其他字符编码,例如 Latin-1 (ISO-8859-1) 和UTF-8,现在比 ASCII 更常用于文档和网页。UTF-8 支持超过一百万个字符。
ARP
地址解析协议 是一种用于将IP 地址映射到连接到本地网络LAN的计算机的协议。由于每台计算机都有一个唯一的物理地址,称为MAC 地址,因此 ARP 将 IP 地址转换为 MAC 地址。这可确保每台计算机都有唯一的网络标识。
当发送到网络的信息到达网关时,使用地址解析协议,网关充当网络的入口点。网关使用 ARP 根据数据发送到的 IP 地址定位计算机的 MAC 地址。ARP 通常在称为“ARP 缓存”的表中查找此信息。如果找到地址,信息将被转发到网关,网关会将传入的数据发送到适当的机器。如有必要,它还可以将数据转换为正确的网络格式。
如果找不到地址,ARP 会向网络上的其他机器广播一个“请求包”,以查看该 IP 地址是否属于未在 ARP 缓存中列出的机器。如果找到了一个有效的系统,信息将被转发到网关,并且 ARP 缓存将使用新信息进行更新。通过更新 ARP 缓存,将来对该 IP 地址的请求会更快。虽然这似乎是一个复杂的过程,但通常只需几分之一秒即可完成。如果在您需要旧收据时也能轻松找到它们就好了。
Gateway
网关是充当两个网络之间的“门”的硬件设备。它可能是路由器、防火墙、服务器或其他使流量能够流入和流出网络的设备。
虽然网关保护网络中的节点,但它本身也是一个节点。网关节点被认为位于网络的“边缘”,因为所有数据在进出网络之前都必须经过它。它还可以将从外部网络接收到的数据转换为内部网络内的设备可识别的格式或协议。
路由器是家庭网络中使用的一种常见网关。它允许本地网络中的计算机通过Internet发送和接收数据。防火墙是一种更高级的网关,它过滤入站和出站流量,禁止来自可疑或未经授权的来源的传入数据。代理服务器是另一种类型的网关,它使用硬件和软件的组合来过滤两个网络之间的流量。例如,代理服务器可能只允许本地计算机访问授权网站列表。
注意: Gateway 也是 1985 年在美国成立的计算机硬件公司的名称。该公司于 2007 年被 Acer 收购,但仍以 Gateway 的名义销售计算机。
Default
默认是描述标准设置或配置的形容词。虽然它并不特定于计算机,但它通常用于IT术语。在计算中,“默认”可以描述几件事,包括硬件、软件和网络配置。
默认硬件配置(或“默认配置”)是具有标准规范的预构建系统。这包括标准组件,例如CPU、RAM、存储设备和视频卡。零售店通常带有默认硬件配置,而在线商店更有可能提供定制选项。
在软件中,“默认”描述了预设设置。例如,当您第一次安装程序时,它将加载默认首选项。如果要更改这些设置,可以打开“首选项”窗口并修改默认选项以满足您的需要。例如,您的网络浏览器可能会默认在选项卡中打开新页面。如果您更喜欢窗口而不是选项卡,则可以更改“首选项”窗口中的默认选择。某些应用程序提供“恢复默认设置”命令,允许您随时恢复到原始设置。
在网络中,“默认”通常用于引用协议。例如,默认情况下,Web 服务器可能通过HTTP提供网页,但它也可能提供安全的HTTPS选项。常见协议(如FTP和SMTP)通常分配有默认端口号,但出于安全原因可以更改它们。
注意:虽然 default 最常用作形容词,但它也可以用作动词。例如,当某个选项不可用时(例如特定字体),程序可能会“默认”为预设设置。
Router
路由器是一种将数据(因此得名)从局域网 (LAN) 路由到另一个网络连接的硬件设备。路由器就像硬币分拣机,只允许授权机器连接到其他计算机系统。大多数路由器还保留有关本地网络活动的日志文件。
Access Point
接入点是允许无线设备连接到网络的设备,例如无线路由器。大多数接入点都有内置路由器,而其他接入点必须连接到路由器才能提供网络访问。在任何一种情况下,接入点通常都与其他设备硬连线,例如网络交换机或宽带调制解调器。
接入点可以在许多地方找到,包括房屋、企业和公共场所。在大多数房屋中,接入点是连接到DSL或电缆调制解调器的无线路由器。但是,某些调制解调器可能包括无线功能,使调制解调器本身成为接入点。大型企业通常会提供多个接入点,允许员工从多个位置无线连接到中央网络。公共接入点可以在商店、咖啡店、餐馆、图书馆和其他位置找到。一些城市以无线发射器的形式提供公共接入点,这些发射器连接到路灯、标志和其他公共物体。
虽然接入点通常提供对 Internet 的无线接入,但有些接入点仅用于提供对封闭网络的接入。例如,企业可能会为其员工提供安全访问点,以便他们可以从网络服务器无线访问文件。此外,大多数接入点都提供Wi-Fi接入,但接入点可能指的是蓝牙设备或其他类型的无线连接。但是,大多数接入点的目的是为连接的用户提供 Internet 访问。
术语“接入点”通常与基站同义使用,尽管基站在技术上只是 Wi-Fi 设备。它也可以缩写为 AP 或 WAP(表示无线接入点)。但是,WAP 不像 AP 那样常用,因为 WAP 是无线接入协议的标准首字母缩写词。
Switch
交换机用于将多台计算机联网在一起。为消费市场制造的交换机通常是带有 4 到 8 个以太网端口的小型扁平盒。这些端口可以连接到计算机、电缆或 DSL 调制解调器以及其他交换机。高端交换机可以有 50 多个端口,并且通常安装在机架上。
交换机比集线器更先进,但不如路由器功能强大。与集线器不同,交换机可以限制进出每个端口的流量,以便连接到交换机的每个设备都有足够的带宽。因此,您可以将交换机视为“智能集线器”。但是,交换机不提供路由器提供的防火墙和日志记录功能。路由器通常可以通过软件进行配置(通常通过 Web 界面),而交换机只能按照硬件设计的方式工作。
术语“开关”也可用于指代计算机硬件上的小杠杆或按钮。虽然它与计算机无关,但“骑行开关”意味着在滑板和滑雪板中倒退。
Firewall
物理防火墙是由砖、钢或其他易燃材料制成的墙,可防止火灾在建筑物中蔓延。在计算中,防火墙也有类似的用途。它充当受信任的系统或网络与外部连接(例如Internet )之间的屏障。然而,计算机防火墙更像是一个过滤器而不是一堵墙,它允许受信任的数据流过它。
可以使用硬件或软件来创建防火墙。许多企业和组织使用硬件防火墙保护其内部网络。可以使用单防火墙或双防火墙来创建非军事区 ( DMZ ),以防止不受信任的数据到达LAN。软件防火墙对于个人用户来说更为常见,并且可以通过软件界面进行自定义配置。Windows 和 OS X 都包含内置防火墙,但可以使用 Internet 安全软件安装更高级的防火墙实用程序。
防火墙可以通过几种不同的方式进行配置。例如,基本防火墙可能允许来自所有IP 地址的流量,但那些标记在黑名单中的地址除外。更安全的防火墙可能只允许来自白名单中列出的系统或 IP 地址的流量。大多数防火墙使用规则组合来过滤流量,例如阻止已知威胁,同时允许来自受信任来源的传入流量。防火墙还可以限制传出流量以防止垃圾邮件或黑客攻击。
网络管理员经常自定义配置硬件和软件防火墙。虽然自定义设置对于公司网络可能很重要,但为消费者设计的软件防火墙通常包含对大多数用户来说足够的基本默认设置。例如,在 OS X 中,只需在“安全和隐私”系统偏好设置中将防火墙设置为“开启”即可防止未经授权的应用程序和服务接受传入连接。一些防火墙甚至会随着时间的推移“学习”并动态开发自己的过滤规则。这有助于他们更擅长阻止不需要的连接,而无需任何手动定制。
WAN
代表“广域网”。它类似于局域网 (LAN),但要大得多。与 LAN 不同,WAN 不限于单个位置。许多广域网通过电话线、光纤电缆或卫星链路跨越长距离。它们也可以由互连的较小 LAN 组成。互联网可以说是世界上最大的广域网。如果您愿意,您甚至可以将 Internet 称为 Super WAN BAM。或者可能不是。
Storage Device
计算机存储设备是存储数据的任何类型的硬件。几乎所有计算机都有的最常见的存储设备类型是硬盘驱动器。计算机的主硬盘驱动器为计算机用户存储操作系统、应用程序以及文件和文件夹。
虽然硬盘驱动器是所有存储设备中最普遍的,但其他几种类型也很常见。闪存设备(例如 USB 钥匙串驱动器和iPod nano)是以小型移动格式存储数据的流行方式。其他类型的闪存,例如紧凑型闪存和SD卡是存储数码相机拍摄的图像的流行方式。
通过火线和USB连接的外部硬盘驱动器也很常见。这些类型的驱动器通常用于备份内部硬盘驱动器、存储视频或照片库,或者仅用于添加额外的存储空间。最后,使用磁带卷来存储数据的磁带驱动器是另一种类型的存储设备,通常用于备份数据。
RAM
内存代表“随机存取存储器”,发音为“ram”。RAM 是电子设备中常见的硬件组件,包括台式电脑、笔记本电脑、平板电脑和智能手机。在计算机中,RAM 可以安装为内存模块,例如DIMM或 (SO-DIMMs sodimm)。在平板电脑和智能手机中,RAM 通常集成到设备中并且无法移除。
设备中的 RAM 量决定了操作系统和打开的应用程序可以使用多少内存。当设备有足够的 RAM 时,可以同时运行多个程序而不会减慢速度。当设备使用接近 100% 的可用 RAM 时,必须在应用程序之间交换内存,这可能会导致明显的减速。因此,添加 RAM 或购买具有更多 RAM 的设备是提高性能的最佳方法之一。
系统内存被认为是“易失性”内存,因为它只在设备打开时存储数据。当设备断电时,存储在 RAM 中的数据会被擦除。当设备重新启动时,操作系统和应用程序会将新数据加载到系统内存中。这就是为什么重新启动计算机通常可以解决问题的原因。
Protocol
协议是允许电子设备相互通信的一组标准规则。这些规则包括可以传输什么类型的数据,使用什么命令来发送和接收数据,以及如何确认数据传输。
您可以将协议视为一种口语。每种语言都有自己的规则和词汇。如果两个人使用相同的语言,他们就可以有效地交流。同样,如果两个硬件设备支持相同的协议,它们可以相互通信,而不管设备的制造商或类型。例如,Apple iPhone可以使用标准邮件协议向 Android 设备发送电子邮件。基于 Windows 的PC可以使用标准 Web 协议从基于 Unix 的Web 服务器加载网页。
存在用于几种不同应用的协议。示例包括有线网络(例如,以太网)、无线网络(例如,802.11ac)和互联网通信(例如,IP)。用于通过 Internet 传输数据的 Internet 协议套件包含数十种协议。这些协议可以分为四类:
链路层协议在硬件级别建立设备之间的通信。为了将数据从一个设备传输到另一个设备,每个设备的硬件必须支持相同的链路层协议。Internet 层协议用于启动数据传输并通过 Internet 路由它们。传输层协议定义了数据包的发送、接收和确认方式。应用层协议包含特定应用的命令。例如,Web 浏览器使用HTTPS从Web 服务器安全地下载网页内容。电子邮件客户端使用SMTP通过邮件服务器发送电子邮件消息。
协议是数字通信的一个基本方面。在大多数情况下,协议在后台运行,因此典型用户无需了解每个协议的工作原理。不过,熟悉一些常用协议可能会有所帮助,这样您就可以更好地了解软件程序中的设置,例如 Web 浏览器和电子邮件客户端。
Font
字体是具有相似设计的字符的集合。这些字符包括小写和大写字母、数字、标点符号和符号。
更改字体可以改变文本块的外观。有些字体设计简单易读,而另一些字体则旨在为文本添加独特的风格。例如,Arial具有简单、现代的外观,而Palatino具有较旧的更传统的外观。
衬线与无衬线字体
两种最基本的字体类别是“serif”和“sans-serif”。字符边缘的小扩展,例如大写字母“ T ”底部的水平线,称为衬线。包含这些小线条的字体称为衬线字体。“sans”这个词的意思是“没有”,所以无衬线字体没有这些额外的行。一般来说,衬线字体具有传统的外观,经常用于印刷书籍和报纸。无衬线字体具有更现代的外观,并且在网络上常用。
大多数文字处理器允许您从工具栏中的“字体”下拉菜单中选择一种字体。您可以将字体应用于整个文档或突出显示的文本部分。为了使用字体,它必须安装在您的计算机上。在 Windows 中,您可以使用字体控制面板添加或删除字体,该控制面板位于控制面板 → 外观和个性化 → 字体。在 macOS 中,您可以使用位于/Applications目录中的Font Book来管理字体。
字体与字体
最初,术语“字体”指的是字体的特定大小和样式。例如,Verdana 是一种字体,而Verdana 16px 粗体将是一种特定字体。然而,近年来,这些术语可以互换使用,微软、苹果和谷歌等公司都使用术语“字体”来描述字体。因此,将 Roboto 等字体称为字体是可以接受的。
Utility
实用程序,通常称为“实用程序”,是为您的计算机添加功能或帮助您的计算机更好地运行的软件程序。其中包括防病毒、备份、磁盘修复、文件管理、安全和网络程序。实用程序也可以是应用程序,例如屏幕保护程序、字体和图标工具以及桌面增强功能。一些实用程序有助于使您的计算机免受病毒或间谍软件等有害软件的侵害,而其他实用程序则添加了允许您自定义桌面和用户界面的功能。通常,有助于使您的计算机变得更好的程序被视为实用程序。与水费和电费不同,计算机公用事业公司不会每月向您发送账单!
Hardware
计算机硬件是指计算机和相关设备的物理部分。内部硬件设备包括主板、硬盘驱动器和RAM。外部硬件设备包括显示器、键盘、鼠标、打印机和扫描仪。
计算机的内部硬件部分通常称为组件,而外部硬件设备通常称为外围设备。总之,它们都属于计算机硬件的范畴。另一方面,软件由在计算机上运行的程序和应用程序组成。由于软件在计算机硬件上运行,因此软件程序通常具有列出软件运行所需的最低硬件的系统要求。
Software
计算机软件是描述计算机程序的通用术语。软件程序、应用程序、脚本和指令集等相关术语都属于计算机软件的范畴。因此,在您的计算机上安装新程序或应用程序与在您的计算机上安装新软件是同义词。
软件可能很难描述,因为它是“虚拟的”,或者不像计算机硬件那样是物理的。相反,软件由计算机程序员编写的代码行组成,这些代码行已编译成计算机程序。软件程序以二进制数据的形式存储,在安装时会复制到计算机的硬盘中。由于软件是虚拟的并且不占用任何物理空间,因此升级比计算机硬件更容易(而且通常更便宜)。
虽然在最基本的层面上,软件由二进制数据、CD-ROM、DVD和其他用于分发软件的介质组成,也可以称为软件。因此,当您购买软件程序时,它通常以光盘形式提供,这是一种存储软件的物理方式。
Network
网络由多个相互通信的设备组成。它可以小到两台计算机,也可以大到数十亿台设备。传统网络由台式电脑组成,而现代网络可能包括笔记本电脑、平板电脑、智能手机、电视、游戏机、智能电器和其他电子产品。
LAN(局域网)
局域网仅限于特定区域,例如家庭、办公室或校园。家庭网络可能有一个提供有线和无线连接的路由器。例如,计算机可能通过以太网连接到路由器,而智能手机和平板电脑通过Wi-Fi连接到路由器。连接到路由器的所有设备共享相同的网络,并且通常共享相同的 Internet 连接。
更大的网络,例如教育机构的网络,可能由许多交换机、集线器和以太网电缆组成。它还可能包括多个无线接入点和无线中继器,提供对网络的无线访问。虽然这种类型的网络比家庭网络复杂得多,但它仍被视为 LAN,因为它仅限于特定位置。
WAN(广域网)
广域网不限于单个区域,而是跨越多个位置。WAN 通常由通过Internet连接的多个 LAN 组成。例如,公司 WAN 可以从总部延伸到世界各地的其他办事处。使用身份验证、防火墙和其他安全措施可能会限制对 WAN 的访问。Internet 本身是最大的 WAN,因为它包含连接到 Internet 的所有位置。
Server
服务器是向其他计算机提供数据的计算机。它可以通过 Internet 向局域网 ( LAN ) 或广域网 ( WAN ) 上的系统提供数据。
存在许多类型的服务器,包括Web 服务器、邮件服务器和文件服务器。每种类型都运行特定于服务器用途的软件。例如,Web 服务器可能运行 Apache HTTP Server 或 Microsoft IIS,它们都提供对 Internet网站的访问。邮件服务器可以运行像 Exim 或 iMail 这样的程序,它们提供SMTP服务来发送和接收电子邮件。文件服务器可能使用Samba或操作系统的内置文件共享服务通过网络共享文件。
虽然服务器软件特定于服务器类型,但硬件并不那么重要。事实上,普通的台式电脑可以通过添加相应的软件变成服务器。例如,可以将连接到家庭网络的计算机指定为文件服务器、打印服务器或两者兼而有之。
虽然任何计算机都可以配置为服务器,但大多数大型企业都使用专为服务器功能设计的机架式硬件。这些系统的大小通常为1U,占用空间极小,并且通常具有LED状态灯和热插拔硬盘驱动器托架等有用功能。多个机架式服务器可以放置在一个机架中,并且通常共享相同的监视器和输入设备。大多数服务器都是使用远程访问软件远程访问的,因此通常甚至不需要输入设备。
虽然服务器可以在不同类型的计算机上运行,但硬件足以支持服务器的需求非常重要。例如,实时运行大量 Web脚本的 Web 服务器应该具有快速的处理器和足够的RAM来处理“负载”而不会减慢速度。文件服务器应该有一个或多个可以快速读取和写入数据的快速硬盘驱动器或SSD 。无论服务器类型如何,快速的网络连接都至关重要,因为所有数据都流经该连接。
Proxy Server
如今,大多数大型企业、组织和大学都使用代理服务器。这是本地网络上的所有计算机在访问 Internet 上的信息之前都必须经过的服务器。通过使用代理服务器,组织可以提高网络性能并过滤连接到网络的用户可以访问的内容。
代理服务器主要通过使用缓存系统来提高网络的 Internet 访问速度。缓存将最近查看的网站、图像和文件保存在本地硬盘驱动器上,这样就不必再次从 Web 下载它们。虽然您的 Web 浏览器可能会在您的计算机上保存最近查看的项目,但代理服务器会缓存从网络访问的所有内容。这意味着如果 Bob 在 1:00 查看 cnn.com 上的新闻报道,而 Jill 在 1:03 查看同一页面,她很可能会直接从代理服务器的缓存中获取该页面。虽然这意味着对网页的超快速访问,但这也意味着用户可能看不到每个网页的最新更新。
代理服务器的另一个主要目的是过滤允许进入网络的内容。虽然 HTTP、FTP 和安全协议都可以通过代理服务器进行过滤,但 HTTP 是最常见的。代理服务器可以限制网络上用户可以访问的网站。许多组织选择阻止访问包含令人反感的材料(例如黑客信息和色情内容)的网站,但也可以过滤其他网站。如果雇主注意到员工在 eBay 或 Quicken.com 等网站上花费过多时间,这些网站也可能被代理服务器阻止。
Node
任何连接到网络的系统或设备也称为节点。例如,如果网络连接了一个文件服务器、五台计算机和两台打印机,那么网络上有八个节点。网络上的每个设备都有一个网络地址,例如MAC 地址,它唯一地标识每个设备。这有助于跟踪数据在网络上传入和传出的位置。
节点也可以指叶子,它是硬盘上的文件夹或文件。在物理学中,节点或节点点是位移最小的点或多个波会聚的点,产生的净振幅为零。
IPv4
IPv4 是使用最广泛的Internet 协议版本。它以 32 位格式定义IP 地址,类似于 123.123.123.123。每个三位数字部分可以包含一个从 0 到 255 的数字,这意味着可用的 IPv4 地址总数为 4,294,967,296(256 x 256 x 256 x 256 或 2^32)。
连接到 Internet 的每台计算机或设备都必须具有唯一的IP 地址,以便与 Internet 上的其他系统进行通信。由于连接到 Internet 的系统数量正在迅速接近可用 IP 地址的数量,因此预计 IPv4 地址将很快用完。考虑到世界上有超过 60 亿人,并且许多人拥有多个连接到 Internet 的系统(例如,在家、学校、工作场所等),大约 43 亿个地址也就不足为奇了。不够。
为了解决这个问题,一种名为IPv6的新 128 位 IP 系统已经开发出来,并且正在取代当前的 IPv4 系统。在从 IPv4 到 IPv6 的过渡过程中,连接到 Internet 的系统可能会被分配 IPv4 和 IPv6 地址。
IPv6
每个连接到 Internet 的计算机系统和设备都由一个IP 地址定位。当前分配 IP 地址的系统称为IPv4。该系统为每台计算机分配一个 32 位数字地址,例如 120.121.123.124。然而,随着连接到 Internet 的计算机的增长,预计可用 IP 地址的数量将在几年内用完。这就是引入 IPv6 的原因。
IPv6,也称为 IPng(或 IP Next Generation),是 IP 地址系统的下一个计划版本。(IPv5 是主要用于流数据的实验版本。)虽然 IPv4 使用 32 位地址,但 IPv6 使用 128 位地址,这使可能的地址数量成倍增加。例如,IPv4 允许使用 4,294,967,296 个地址 (2^32)。IPv6 允许超过 340,000,000,000,000,000,000,000,000,000,000,000,000 个 IP 地址。这应该足以持续一段时间。
因为 IPv6 允许的 IP 地址比 IPv4 多很多,所以地址本身更复杂。它们通常以这种格式编写:
hhhh:hhhh:hhhh:hhhh:hhhh:hhhh:hhhh:hhhh
每个“hhhh”部分由一个四位十六进制数字组成,这意味着每个数字可以是从 0 到 9 以及从 A 到 F。示例 IPv6 地址可能如下所示:
F704:0000:0000:0000:3458:79A2:D08B:4320
由于 IPv6 地址非常复杂,新系统还为连接到 Internet 的计算机增加了额外的安全性。由于 IP 地址的可能性如此之大,因此猜测另一台计算机的 IP 地址几乎是不可能的。尽管当今大多数计算机系统都支持 IPv6,但新的 Internet 协议尚未完全实施。在此过渡过程中,计算机通常同时分配有 IPv4 和 IPv6 地址。到 2008 年,美国政府已强制要求所有政府系统使用 IPv6 地址,这将有助于推动过渡。
MAC Address
代表“媒体访问控制地址”,不,它与 Apple Macintosh 计算机无关。MAC 地址是唯一标识网络上每个设备的硬件标识号。MAC 地址是在每个网卡中制造的,例如以太网卡或Wi-Fi卡,因此无法更改。
因为存在数以百万计的可联网设备,并且每个设备都需要有一个唯一的 MAC 地址,所以必须有非常广泛的可能地址。因此,MAC 地址由六个用冒号分隔的两位十六进制数字组成。例如,以太网卡的 MAC 地址可能为 00:0d:83:b1:c0:8e。幸运的是,您不需要知道这个地址,因为大多数网络都会自动识别它。
Packet
数据包是通过网络(例如LAN或Internet )发送的少量数据。与现实生活中的数据包类似,每个数据包都包括源和目标以及正在传输的内容(或数据)。当数据包到达目的地时,它们被重新组合成一个文件或其他连续的数据块。
虽然数据包的确切结构因协议而异,但典型的数据包包括两个部分——标头和有效负载。有关数据包的信息存储在标头中。例如,IPv6标头包括以下字段:
- 源地址(128 位)- 数据包来源的 IPv6 地址
- 目标地址(128 位)- 数据包目标的 IPv6 地址
- 版本(4 位)- IPv6 为“6”
- 流量类别(8 位)- 数据包的优先级设置
- 流标签(20 位)- 将数据包标记为特定流的一部分的可选 ID;用于区分来自单一来源的多个传输
- 有效负载长度(16 位)- 数据的大小,以八位字节定义
- Next header (8 bits) - 当前数据包后面的头部ID;可能是TCP、UDP或其他协议
- 跳数限制(8 位)- 丢弃数据包之前(路由器、交换机等之间)的最大网络跳数;在 IPv4 中也称为“ TTL ”
数据包的有效负载部分包含正在传输的实际数据。这通常只是文件、网页或其他传输的一小部分,因为单个数据包相对较小。例如,IP数据包有效负载的最大大小为 65,535字节或 64 KB。以太网数据包或“帧”的最大大小仅为 1,500 字节或 1.5 KB。
数据包旨在可靠且高效地传输数据。不是将大文件作为单个数据块传输,而是发送较小的数据包有助于确保每个部分都成功传输。如果一个数据包没有被接收或被“丢弃”,只有丢弃的数据包需要被重新发送。此外,如果数据传输由于多个同时传输而遇到网络拥塞,则剩余的数据包可以通过拥塞较少的路径重新路由。
AR
增强现实,通常缩写为“AR”,是覆盖在现实世界环境中的计算机生成内容。AR硬件有多种形式,包括您可以携带的设备,例如手持显示器,以及您佩戴的设备,例如耳机和眼镜。AR 技术的常见应用包括视频游戏、电视和个人导航,但也有许多其他用途。
Pokémon Go 是一款使用增强现实技术的流行视频游戏。该应用程序在iOS和Android设备上运行,使用智能手机的GPS信号来检测您的位置。当您四处走动时,您的化身会覆盖在真实世界的地图上,以及游戏中的内容,例如出现的 Pokéstop、健身房和 Pokemon。当您尝试捕捉神奇宝贝时,它会显示由您的智能手机相机创建的真实背景。可以使用“AR”拨动开关打开或关闭相机。
增强现实也用于电视,尤其是体育运动。例如,高尔夫广播有时会在屏幕上显示一条线来跟踪球的飞行。NFL 比赛显示覆盖在场地上的第一条下线。美国职业棒球大联盟比赛经常在本垒后面显示动态生成的广告。在奥运会比赛中,在某些比赛中会显示一条世界纪录 (WR) 线,以显示运动员距离创纪录的时间有多近。
在导航中,AR用于实时显示位置信息。这通常通过平视显示器 (HUD) 完成,该显示器像全息图一样在您面前投射图像。例如,汽车中的 HUD 可能会显示您的速度、发动机转速和其他有用数据。谷歌眼镜是一种头戴式显示器,可以覆盖谷歌地图的方向,并使用内置摄像头识别位置。
增强现实与虚拟现实
虽然增强现实和虚拟现实有一些共同点,但它们是两种不同的技术。AR 增强了现实,但不能取代它。VR 用虚拟环境完全取代了您的周围环境。因此,任何将数字内容与您的实际环境相结合的硬件都是 AR 设备。独立于您所在位置并包含您的视野的硬件是 VR 设备。
Authentication
在计算中,身份验证是验证个人或设备身份的过程。一个常见的例子是在您登录网站时输入用户名和密码。输入正确的登录信息可以让网站知道 1)您是谁,以及 2)您实际上是在访问该网站。
虽然用户名/密码组合是验证您的身份的常用方法,但存在许多其他类型的验证。例如,您可以使用四位数或六位数的密码来解锁手机。登录笔记本电脑或工作计算机可能需要一个密码。每次您检查或发送电子邮件时,邮件服务器都会通过将您的电子邮件地址与正确的密码匹配来验证您的身份。此信息通常由您的网络浏览器或电子邮件程序保存,因此您不必每次都输入。
生物特征也可用于认证。例如,许多智能手机都有一个指纹传感器,您只需轻按拇指或手指即可解锁手机。一些设施有视网膜扫描仪,需要进行眼部扫描以允许授权人员进入安全区域。Apple 的 Face ID(随 iPhone X 推出)通过面部识别对用户进行身份验证。
双重身份验证
身份验证是数字时代日常生活的一部分。虽然它有助于保护您的个人信息的私密性,但它并非万无一失。例如,如果有人知道您的电子邮件地址,他或她只需猜测您的密码即可访问您的帐户。这就是为什么使用不常见的、难以猜测的密码很重要的原因,尤其是对于您的电子邮件帐户。在可用时使用双因素身份验证也是一个好主意,因为这在访问您的帐户时提供了额外的安全检查。
双重身份验证(也称为“2FA”)通常需要正确登录以及另一次验证检查。例如,如果您为您的网上银行账户启用 2FA,您可能需要输入一个发送到您的手机或电子邮件地址的临时代码来完成登录过程。这可确保只有您(或有权访问您的电话或电子邮件帐户的人)才能访问您的帐户,即使在输入正确的登录信息后也是如此。
注意:在许多情况下,您可以在登录安全网站时选中“记住我”复选框。这将在您的设备(计算机、手机、平板电脑等)上存储一个cookie ,这表明该设备是受信任的,或者先前已通过该网站的身份验证。cookie 可能会让您在多个浏览器会话中保持登录状态,或者可能会在将来使用该设备时避免双重身份验证的需要。
Baseband
基带是指传输信号在转换或调制到不同频率范围之前的原始频率范围。例如,音频信号可能具有从 20 到 20,000赫兹的基带范围。当它在射频 (RF) 上传输时,它会被调制到更高、听不见的频率范围。
信号调制用于无线电广播以及多种类型的电信,包括手机通话和卫星传输。因此,大多数电信协议要求在传输原始基带信号之前将其调制到更高的频率。然后这些信号在目的地被解调,因此接收者接收到原始基带信号。拨号调制解调器是这个过程的一个很好的例子,因为它们在发送和接收信号时调制和解调信号。事实上,“调制解调器”这个词是调制器/解调器的缩写。
虽然大多数协议都需要调制基带信号,但有些协议无需任何信号转换即可在基带中传输。一个常见的例子是以太网协议,它使用原始基带信号传输数据。事实上,“10BASE-T”、“100BASE-T”和“1000BASE-T”以太网中的“BASE”一词指的是基带传输。这些以太网协议不需要信号调制。然而,与宽带网络不同,基带以太网网络仅限于单一传输通道。
Video Card
计算机上完成的大部分处理都是通过计算机的中央处理单元或CPU完成的。因此,为了让 CPU 休息一下并帮助它更有效地运行,可以使用显卡来处理处理负载的图形部分。由于当今的大多数程序都是面向图形的,因此视频卡可以帮助几乎所有程序更有效地运行。但是,性能差异在图像编辑应用程序和 3D 游戏中尤为明显。
显卡,也称为图形加速器,可以加速 2D 和 3D 图形渲染。照片编辑器和 Web 浏览器等程序可能会受益于 2D 加速,而CAD设计程序和视频游戏很可能会受益于卡片的 3D 加速。有些程序严重依赖显卡,如果未安装支持的显卡,它们将无法运行。
大多数视频卡都支持OpenGL和DirectX库。这些库包括用于操作程序员可以在其代码中包含的图形的命令。其中一些命令可能包括移动或旋转对象、变形多边形或投射光和创建阴影。通过使用标准的 OpenGL 或 DirectX 函数,开发人员可以更轻松地创建面向图形的程序。当然,这也使得计算机必须包含支持的视频卡才能运行程序。
视频卡通常安装在计算机背面的PCI或AGP插槽中。大多数计算机都在其中一个插槽中安装了视频卡,这意味着它可以在以后升级。
Bézier Curve
Bézier(发音为“bez-EA”)曲线是用于创建矢量图形的线或“路径” 。它由两个或多个控制点组成,这些控制点定义了线的大小和形状。第一个点和最后一个点标记路径的开始和结束,而中间点定义路径的曲率。
贝塞尔曲线用于创建平滑的曲线,这在矢量图形中很常见。由于它们是由控制点定义的,因此可以调整贝塞尔曲线的大小而不会失去其平滑的外观。另一方面,光栅图形定义图像中的每个像素,并在放大时出现块状或像素化。
贝塞尔曲线有多种类型,包括线性曲线、二次曲线和高阶曲线。线性曲线是由两点定义的直线。二次曲线包括在不同方向上拉控制点和路径的中间点。高阶曲线可能包括额外的中间点,用于微调路径如何跟随每个控制点。
贝塞尔曲线的形状是使用插值计算的,插值是一种近似每个控制点之间的直线路径的方法。由于计算机屏幕使用像素显示图形,因此当显示在屏幕上时,贝塞尔曲线总是近似的。如果您使用绘图程序或CAD软件放大贝塞尔曲线,您将看到更准确的路径表示。
注意: Bézier 曲线以法国工程师 Pierre Bézier 命名,这就是为什么“B”总是大写的原因。
Binary
二进制(或以 2 为底)的数字系统,仅使用两位数字 - 0 和 1。计算机以二进制方式运行,这意味着它们仅使用零和一来存储数据并执行计算。
在布尔逻辑中,单个二进制数字只能表示 True (1) 或 False (0) 。但是,可以使用多个二进制数字来表示大数并执行复杂的功能。事实上,任何整数都可以用二进制表示。
以下是以二进制表示的几个十进制(或“base-10”)数字的列表。
Boot
引导启动计算机时,只需将其打开即可。不建议将您的计算机踢得太远,尽管您有时可能很想这样做。“靴子”一词来自“bootstraps”一词,人们曾经用它来穿上靴子。同样,“启动”计算机可以使其启动并运行。
简单来说,启动计算机就是打开它。一旦计算机的电源打开,“启动过程”就会发生。此过程涉及从计算机的 ROM 加载启动指令,然后从当前启动盘加载操作系统。启动盘通常是内部硬盘驱动器,但也可以是外部驱动器、CD 或 DVD-ROM,甚至是软盘。加载操作系统软件后,启动过程就完成了,计算机就可以使用了。
Boot Sector
引导扇区是硬盘或其他存储设备的专用部分,其中包含用于引导计算机系统的数据。它包括在引导序列期间访问的主引导记录 (MBR) 。
引导扇区通常位于磁盘的最开始,在第一个分区之前。它包括分区映射,它标识磁盘上的所有分区。它还定义了哪个分区包含启动数据(例如操作系统)。这让计算机在启动时知道要访问哪个分区。因此,如果磁盘的引导扇区损坏或包含无效数据,则计算机可能无法从该磁盘启动。如果发生这种情况,您应该运行磁盘实用程序或防病毒程序来尝试解决问题。
Boot Sequence
引导顺序每次计算机启动时,它都会经历一系列初始过程。这一系列事件被恰当地命名为“引导序列”。在启动过程中,计算机会激活必要的硬件组件并加载适当的软件,以便用户可以与机器进行交互。
启动顺序从访问Windows PC 上的计算机BIOS或Macintosh 上的系统ROM开始。BIOS 和 ROM 包含告诉计算机如何启动的基本指令。这些指令然后被传递到计算机的CPU,它开始将信息加载到系统RAM中。一旦找到有效的启动盘或启动盘,计算机就会开始将操作系统加载到系统内存中。操作系统完成加载后,计算机即可使用。
启动顺序可能需要几秒钟到几分钟不等,具体取决于计算机的配置。如果系统从CD或DVD引导,则引导时间可能比计算机从硬盘驱动器引导的时间长得多。此外,如果您的计算机意外关闭,启动时间可能会增加,因为系统可能会执行一些额外的检查以确保一切正常。
VM
虚拟机(或“VM”)是使用软件创建的模拟计算机系统。它使用物理系统资源,例如CPU、RAM和磁盘存储,但与计算机上的其他软件隔离。它可以很容易地创建、修改或销毁,而不会影响主机。
虚拟机提供与物理机类似的功能,但它们并不直接在硬件上运行。相反,在硬件和虚拟机之间存在一个软件层。管理一个或多个虚拟机的软件称为“管理程序”,虚拟机称为“客户”或虚拟化实例。每个来宾都可以与硬件交互,但管理程序控制它们。管理程序可以启动和关闭虚拟机,还可以为每个虚拟机分配特定数量的系统资源。
您可以使用虚拟化软件创建虚拟机。示例包括 Microsoft Hyper-V Manager、VMware Workstation Pro 和 Parallels Desktop。这些应用程序允许您在单台计算机上运行多个 VM。例如,Parallels Desktop for Mac 允许您在 Mac 上运行Windows、Linux和macOS虚拟机。
VM 非常适合测试软件,因为开发人员可以安装一个或多个应用程序并在需要时恢复到保存状态(或“快照”)。在常规操作系统上测试软件可能会导致意外崩溃,并且可能会在卸载软件后留下一些文件。在与操作系统隔离并可以根据需要完全重置的虚拟机上测试软件更安全。
基于云的虚拟机
随着云服务越来越受欢迎,基于云的虚拟机也越来越受欢迎。“云实例”通常被称为“云实例”,运行在可通过Internet访问的计算机上。VM 通常通过Web 浏览器或远程访问实用程序进行控制。基于云的虚拟机是公司测试软件部署的常用方法,因为它们可以在数十台机器上进行测试,而无需在本地托管虚拟机。
Snapshot
指的是在特定时间由磁盘驱动器制作的副本。快照对于以不同的时间间隔备份数据很有用,它允许从不同的时间段恢复信息。
硬盘快照包括硬盘的完整目录结构,包括磁盘上的所有文件夹和文件。这种类型的备份也可以称为“磁盘映像”。磁盘映像允许在主磁盘发生故障时恢复整个磁盘。许多创建快照的备份程序还允许从快照中恢复特定文件,而不必恢复完整的备份。由于快照主要用于备份目的,因此明智的做法是将快照保存到辅助硬盘驱动器、可移动驱动器或光介质,例如CD或DVD。